
會計師不可能查每一筆,那他到底「查多少」才算夠?
深入審計抽樣的統計骨架:屬性抽樣查內控、貨幣單位抽樣(MUS)查金額高估、實質分析性程序不抽樣也能取證,看偵查風險如何被一筆筆「算」出來。
會計師不可能查每一筆,那他到底「查多少」才算夠?
入門篇告訴你,審計提供的是「合理確信」而非絕對保證,而合理確信之所以做不到絕對,第一個原因就是「抽樣」(Sampling)——會計師不可能逐筆檢查數十萬張傳票。聽起來很合理,但這句話其實藏了一個更尖銳的問題:既然只抽一部分,那要抽幾筆?抽到的結果,憑什麼可以推論到整個母體?萬一抽樣剛好漏掉了那筆舞弊呢?
這不是憑感覺決定的。現代審計把「抽多少、怎麼推論、容許多少風險」變成一套統計決策。本文要深入入門篇刻意略過的硬核機器:統計抽樣(Statistical Sampling)的數學骨架——包含查核控制用的屬性抽樣(Attribute Sampling)、查核金額用的貨幣單位抽樣(Monetary Unit Sampling, MUS),以及用比率與迴歸「不查單筆也能下結論」的實質分析性程序(Substantive Analytical Procedures)。讀完你會明白:審計風險模型裡那個「會計師唯一能控制的偵查風險」,是怎麼一筆一筆被「算」出來的。
為什麼抽樣不是「隨便抽幾筆」
先釐清一個迷思。很多人以為抽樣就是「老闆覺得抽 30 筆差不多」。在審計裡,這叫非統計抽樣(Non-statistical Sampling),它依賴專業判斷、可以用、但無法量化抽樣風險。與之相對的是統計抽樣(Statistical Sampling),它用機率論決定樣本量、用機率論解釋結果,最大的好處是:抽樣風險(Sampling Risk)變成一個可以計算、可以控制的數字。
什麼是抽樣風險?就是「樣本的結論」與「對整個母體做全查會得到的結論」不一致的可能性。它有兩個方向,後果天差地別:
| 風險類型 | 控制測試情境 | 實質測試情境 | 後果 |
|---|---|---|---|
| 過度信賴風險 / 誤受風險(Risk of Incorrect Acceptance) | 內控其實無效,卻判斷有效 | 餘額其實有重大誤述,卻判斷允當 | 影響查核效果:簽錯意見,最危險 |
| 過度不信賴風險 / 誤拒風險(Risk of Incorrect Rejection) | 內控其實有效,卻判斷無效 | 餘額其實允當,卻判斷有誤述 | 影響查核效率:白做工、擴大查核、成本上升 |
兩者都是錯,但會計師最怕的是第一類——誤受。因為誤拒只是讓你多花成本查證,最後真相會浮現;誤受卻會讓一張該被退回的報表掛上無保留意見,等到事發已是訴訟與聲譽崩塌。所以統計抽樣的整套設計,核心就是把「誤受風險」壓到可接受的低水準。這裡的「可接受誤受風險」,其實就是入門篇審計風險模型裡偵查風險(DR)的具體化身。
屬性抽樣:查「內控有沒有照做」
控制測試(Test of Controls)問的是一個「是非題」:這項控制有沒有確實執行?例如「每張採購單是否都有經理核章」。每一筆抽出來的單據,結果只有兩種——有章(符合)或沒章(偏差,Deviation)。這種「成功/失敗」的二元結構,統計上對應二項分配(Binomial Distribution),使用的抽樣方法稱為屬性抽樣。
屬性抽樣要先設定三個參數:
- 可容忍偏差率(Tolerable Deviation Rate, TDR):你願意接受的最高偏差率。超過它,就認定這項控制不可信賴。
- 預期母體偏差率(Expected Deviation Rate, EDR):根據過去經驗或前測,預估母體實際的偏差率。
- 過度信賴風險(Risk of Overreliance):通常設 5% 或 10%。
樣本量會隨「TDR 越小、EDR 越接近 TDR、可接受風險越低」而急遽放大。直覺上:你要求越嚴(容忍度低)、母體越爛(預期偏差高)、又越不能出錯(風險低),自然要看更多筆才敢下結論。
查完之後,關鍵在於計算樣本偏差率上限——也就是偏差率上限(Upper Deviation Limit, UDL):
$$ \text{UDL} = \text{樣本偏差率} + \text{抽樣風險寬容(Allowance for Sampling Risk)} $$
判斷規則乾淨俐落:
$$ \text{若 } \text{UDL} \le \text{TDR} \implies \text{控制可信賴;反之則否} $$
看一個例子:採購核章控制測試
某公司全年採購單約 8,000 張。會計師設定可容忍偏差率 TDR = 6%、過度信賴風險 = 5%、預期偏差率 EDR = 1%。查表得樣本量約 78 張(此處用抽樣表結果,實務上由統計表或軟體決定)。會計師隨機抽 78 張,發現其中 2 張缺核章。
樣本偏差率:
$$ \text{樣本偏差率} = \frac{2}{78} \approx 2.56\% $$
光看 2.56% 小於 6%,會不會就放心了?不行。 樣本偏差率只是「點估計」,必須加上抽樣風險寬容。在 5% 風險、78 筆、2 個偏差下,查統計表得偏差率上限 UDL 約為 7.6%:
$$ \text{UDL} \approx 7.6\% \; > \; \text{TDR} = 6\% $$
結論:即使樣本只有 2.56% 偏差,UDL 仍超過容忍門檻,會計師不能信賴這項控制。換句話說,控制風險(CR)評估必須調高,連帶迫使偵查風險(DR)下降——會計師必須擴大後續的實質測試。這正是入門篇「內控越弱、實質測試越多」那句話背後的數學機制。
貨幣單位抽樣:查「金額有沒有虛報」
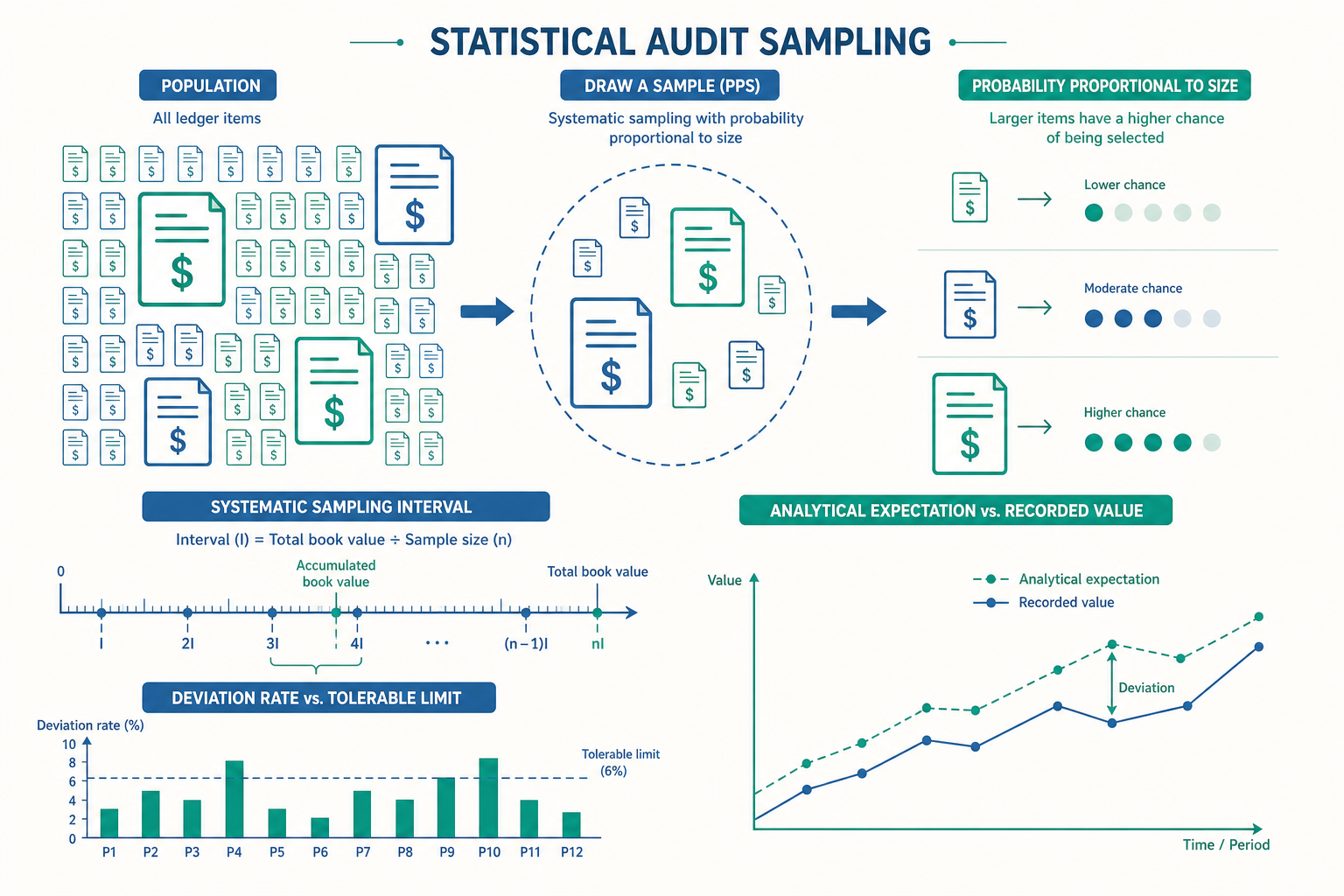
控制測試問是非,實質細項測試(Substantive Test of Details)問的卻是「金額對不對、有沒有高估」。這時二元結構不夠用,因為一筆 1,000 萬元的錯與一筆 100 元的錯,影響天差地別。審計實務最常用的解法是貨幣單位抽樣(Monetary Unit Sampling, MUS),又稱機率與規模成比例抽樣(Probability-Proportional-to-Size, PPS)。
MUS 的天才之處在於:它不是把「每一筆交易」當抽樣單位,而是把「每一塊錢」當抽樣單位。一筆 1,000 萬元的應收帳款,內含 1,000 萬個被抽中的機會;一筆 100 元的只有 100 個機會。結果就是金額越大的項目,越容易被抽中——這完全符合審計直覺:大金額本來就該優先查,因為它對重大性的威脅最大。
MUS 的樣本量由一條簡潔的公式決定:
$$ n = \frac{\text{母體帳列金額(Book Value)} \times \text{信賴因子(Reliability Factor, RF)}}{\text{可容忍誤述(Tolerable Misstatement, TM)} - (\text{預期誤述} \times \text{擴張因子})} $$
其中信賴因子由可接受的誤受風險決定:誤受風險 5% 對應 RF ≈ 3.0、10% 對應 RF ≈ 2.3。抽樣的「間距」(Sampling Interval)則是:
$$ \text{抽樣間距} = \frac{\text{母體帳列金額}}{n} $$
實作上,會計師把所有項目金額累加,然後每隔一個「間距」就抽中落在那個累計點上的項目。
動手試試:應收帳款的 MUS
延續入門篇晶睿公司的場景,假設應收帳款母體帳列總額為 8,000 萬元。會計師設定可容忍誤述 TM = 400 萬元(低於整體重大性)、可接受誤受風險 5%(RF = 3.0),先假設預期誤述為 0 以簡化:
$$ n = \frac{80{,}000{,}000 \times 3.0}{4{,}000{,}000} = 60 \text{ 個(樣本量)} $$
$$ \text{抽樣間距} = \frac{80{,}000{,}000}{60} \approx 1{,}333{,}333 \text{ 元} $$
意義是:每累積約 133 萬元就抽中一筆。任何帳列金額大於 133 萬元的單筆項目,必然被抽中(因為它一定跨過至少一個間距點),這保證了大額項目 100% 被查——這是 MUS 相對於傳統隨機抽樣最受推崇的特性。
接著看怎麼推估母體誤述。假設抽中的某筆帳列 80 萬元,查證後真實金額只有 60 萬元,高估了 20 萬元。MUS 用污染率(Tainting)換算這筆抽樣單位代表的誤述:
$$ \text{污染率} = \frac{\text{帳列} - \text{查得}}{\text{帳列}} = \frac{800{,}000 - 600{,}000}{800{,}000} = 25\% $$
由於這筆金額(80 萬)小於抽樣間距(133 萬),它代表的是整個間距的一個樣本,推估誤述為:
$$ \text{推估誤述} = \text{污染率} \times \text{抽樣間距} = 25\% \times 1{,}333{,}333 \approx 333{,}333 \text{ 元} $$
把所有抽中項目的推估誤述加總,再加上信賴因子帶來的基本精確度(Basic Precision),就得到誤述上限(Upper Misstatement Limit, UML)。判斷規則同樣乾淨:
$$ \text{若 } \text{UML} \le \text{TM} \implies \text{餘額允當(接受);反之則需擴大查核或建議調整} $$
注意一個細節:若抽中項目的帳列金額大於或等於抽樣間距,就不需要污染率推估——因為它本來就被 100% 全查了,直接用實際查得的誤述金額即可。這就是為什麼 MUS 對「大額高估」特別敏銳。
不查單筆也能下結論:實質分析性程序
抽樣是「由部分推全體」,但審計還有另一條更高效的路——實質分析性程序(Substantive Analytical Procedures)。它的核心思想是:如果某個會計科目與其他變數之間有穩定、可預測的關係,那麼會計師可以先建立一個「期望值」,再拿期望值與帳列數比對。只要兩者落差在容許範圍內,就能對該科目取得實質證據——完全不必抽任何一筆傳票。
最經典的例子是利息費用。借款利息高度可預測:
$$ \text{期望利息費用} = \text{平均借款餘額} \times \text{平均利率} $$
假設某公司平均借款 5 億元、平均年利率 3%,期望利息費用約 1,500 萬元。若帳列利息費用是 1,480 萬元,落差僅 20 萬元(1.3%),在重大性容許範圍內,會計師對「利息費用無重大誤述」就有了合理把握。但若帳列是 2,200 萬元,多出近 700 萬元無法解釋,這就是強烈紅旗——可能漏列了某筆借款、或利息資本化處理有誤。
更進階的版本會用迴歸分析(Regression)建立期望模型。例如以歷史資料估計「水電費」與「產量、氣溫」的關係:
$$ \hat{Y} = \beta_0 + \beta_1 \cdot \text{產量} + \beta_2 \cdot \text{平均氣溫} + \varepsilon $$
把本期的產量與氣溫代入,得到期望水電費,再與帳列比較。落差超過門檻值(Threshold)才需追查。實質分析性程序有效的四個前提是:(1) 關係本身可信且穩定;(2) 資料可靠(最好來自外部或受良好內控保護);(3) 期望值夠精確;(4) 落差門檻設得夠嚴。少了任何一個,分析性程序就只能當「指認方向的指南針」,不能當「下結論的證據」。
重點回顧
- 抽樣風險是可計算、可控制的數字:統計抽樣相對非統計抽樣的最大價值,在於量化抽樣風險;其中誤受風險(影響查核效果)遠比誤拒風險(影響效率)危險,是整套設計要壓低的對象,也是審計風險模型中偵查風險(DR)的具體化身。
- 屬性抽樣查控制、看是非:以二項分配為基礎,比較偏差率上限 UDL 與可容忍偏差率 TDR;UDL 必須加上抽樣風險寬容,光看樣本偏差率會誤判。
- 貨幣單位抽樣(MUS)查金額、看高估:以「每一塊錢」為抽樣單位,大金額必被抽中;用污染率 × 抽樣間距推估誤述,比較誤述上限 UML 與可容忍誤述 TM。
- MUS 對大額高估特別敏銳:帳列金額 ≥ 抽樣間距者一律全查、不需污染率推估,天然契合重大性導向。
- 實質分析性程序可不抽樣就取證:建立可預測的期望值(如利息 = 平均餘額 × 利率,或迴歸模型),與帳列比對,落差超門檻才追查;前提是關係穩定、資料可靠、期望精確。
深入探討(研究所視角)
進入研究所層次,審計抽樣與分析性程序背後是統計推論、決策理論與資料科學的交會地帶,至今仍有大量未解的研究與實務張力。
第一,貝氏更新與審計風險模型的再詮釋。 傳統 $AR = IR \times CR \times DR$ 是乘積式的點估計,但更嚴謹的觀點把審計視為貝氏推論(Bayesian Inference):固有風險與控制風險構成「先驗機率」,每一項查核證據都是一次「資料更新」,逐步修正對「報表是否重大誤述」的後驗信念。MUS 的信賴因子其實隱含 Poisson 近似下的信賴上界,這讓抽樣結論能無縫接入貝氏框架。研究上,如何在「會計師主觀先驗」與「客觀統計」之間取得平衡,仍是審計判斷研究的核心議題。
第二,全量資料時代抽樣會消失嗎? 當交易全面電子化、會計師能對整個母體做分析,「抽樣」的存在理由似乎被動搖。資料分析(Audit Data Analytics, ADA)讓 100% 檢測成為可能——用 Benford 定律檢測數字首位分布異常、用孤立森林(Isolation Forest)等非監督式學習標記離群交易、用流程探勘(Process Mining)重建並比對交易流程。但全量分析帶來新問題:偽陽性爆炸(離群不等於錯誤)、以及「例外(Exception)不等於誤述」的判斷負擔。學界正辯論:當會計師面對機器標出的數千筆例外,專業懷疑與判斷的角色是被強化還是被稀釋?
第三,分析性程序的精確度悖論。 迴歸式期望模型越精準,理論上越能取代細項測試、提升效率;但模型越複雜,模型風險(Model Risk)也越高——過度配適(Overfitting)、資料外推、結構性斷裂(如疫情、政策變動使歷史關係失效)都可能讓「看似精準的期望」變成「精準的錯」。如何驗證分析模型本身的可靠性,正成為查核「演算法輔助查核」時的元問題。
第四,抽樣風險與訴訟風險的不對稱。 從決策理論看,誤受與誤拒的成本天差地別,理性的會計師會在「期望損失最小化」下決定樣本量與精確度。但這個最優解受法律責任制度(連帶責任 vs. 比例責任)、事務所聲譽資本與保險市場強烈影響。量化這些制度因素如何反向形塑會計師的抽樣保守程度與查核投入,是審計經濟學最活躍的前沿之一。
審計抽樣的迷人之處在於:它把「我到底相不相信這張報表」這個極度人性的判斷,翻譯成機率、間距與信賴因子的精密語言。讀懂它,你會發現會計師的簽名背後,不是直覺,而是一整套可被檢驗的推論結構。