
同樣一隻神經元,為什麼在亮房間與暗房間講的是兩種「語言」?
從效率編碼、適應性增益控制到貝氏觀察者,看感覺系統如何用有限的神經資源對最有資訊量的世界做最佳推論。
同樣一隻神經元,為什麼在亮房間與暗房間講的是兩種「語言」?
你已經知道感覺系統會把光、聲、壓力轉成神經訊號,也知道大腦是在「猜測」世界。但這裡有一個更尖銳的問題:一個神經元發射動作電位的速率上限大約只有每秒幾百次,而它要編碼的外在世界——比如光的強度——卻可以橫跨十個數量級(從星光到正午陽光,亮度相差約十億倍以上)。一條頻寬如此有限的「電纜」,怎麼可能塞得下這麼大的動態範圍?
答案不是「塞不下」,而是「不硬塞」。感覺系統選擇了一個極其聰明的策略:它不編碼絕對值,而是不斷地重新校準自己,只編碼「相對於當下脈絡的偏差」。同樣一個神經元,在暗房間裡,它把微弱的光差講得很大聲;在亮房間裡,它整個重設靈敏度,對同樣的絕對亮度幾乎沉默。它講的是兩種「語言」,因為它在用最少的位元(bit),傳遞當下最有資訊量的內容。
這篇進階文章不再重述轉導與拓樸地圖,而是要帶你進入感覺系統的編碼理論(coding theory)視角:它如何用有限的神經資源,逼近資訊論的效率極限;如何在毫秒到秒的尺度上動態調整增益;以及為什麼「貝氏觀察者(Bayesian observer)」這個數學框架,能把錯覺、適應與個體差異統一在同一支方程式底下。
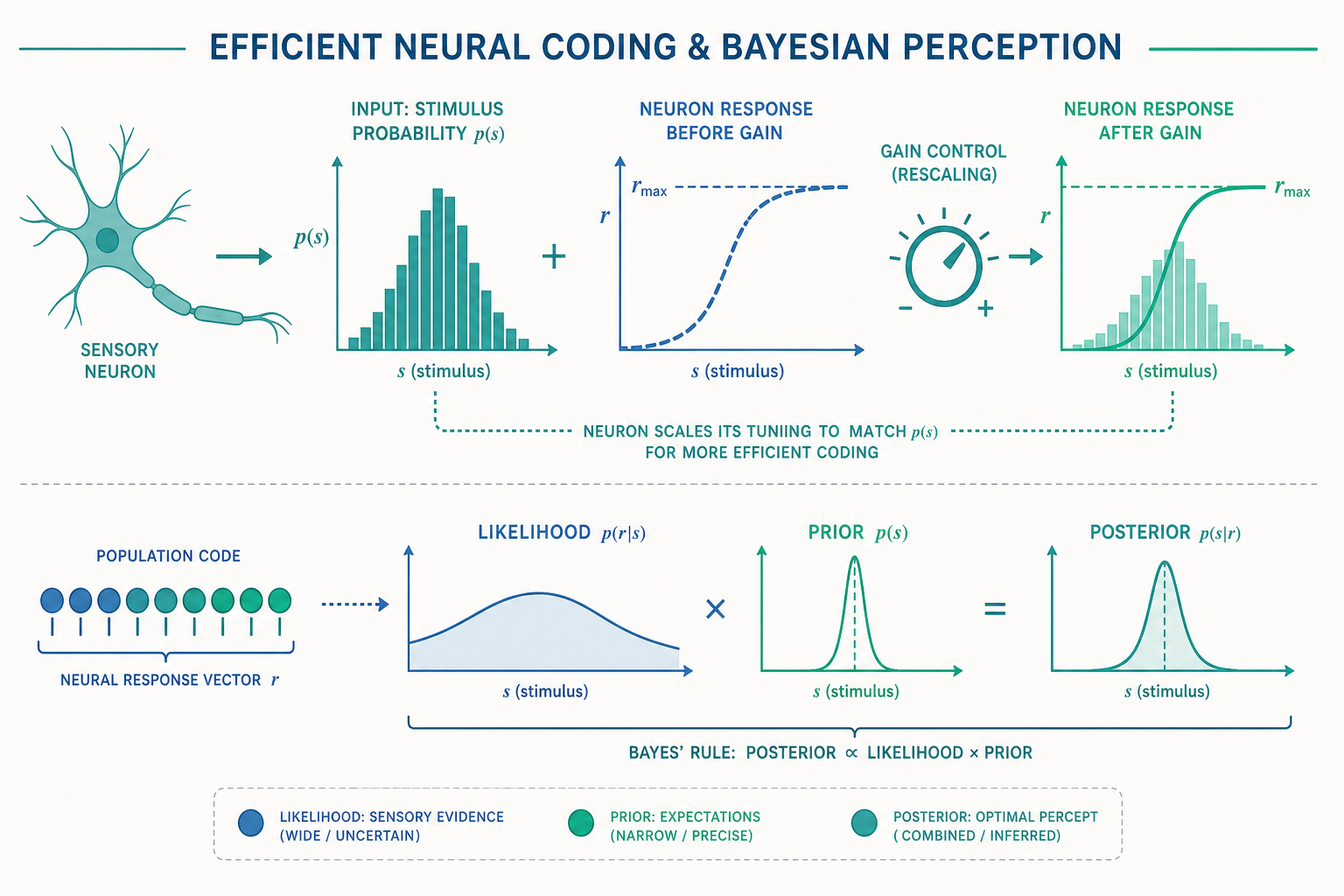
效率編碼假說:大腦是一位資訊論工程師
1961 年,神經科學家 Horace Barlow 提出了一個影響深遠的想法——效率編碼假說(efficient coding hypothesis)。他主張:感覺系統在演化與發育中,被塑造成能用最少的神經活動,去傳遞最多關於自然環境的資訊。換句話說,感覺神經元的設計目標,與通訊工程師 Claude Shannon 在《資訊論》中追求的目標是一致的——最大化通道的資訊傳輸效率。
這個假說有兩個具體且可驗證的預測:
預測一:神經元的反應曲線應該配合刺激的統計分布。 如果某個刺激值在自然界很常出現,神經元就應該把較多的「可分辨等級」分配給它;反之,罕見的刺激值不值得浪費頻寬。這正是「直方圖等化(histogram equalization)」的概念。1981 年,Simon Laughlin 在蒼蠅的視覺系統(大單極細胞,large monopolar cell)做了一個經典實驗:他先測量蒼蠅自然棲地中對比度(contrast)的機率分布,然後預測——如果神經元是效率最佳的,它的反應曲線(contrast-response curve)形狀,應該正好等於這個分布的累積分布函數(cumulative distribution function, CDF)。實測結果與理論預測驚人地吻合。這是「神經元的形狀,是被環境的統計雕刻出來的」最漂亮的證據之一。
預測二:神經元之間應該盡量「去相關(decorrelation)」。 自然影像中,相鄰的像素高度相關(天空這一點是藍的,旁邊那一點多半也是藍的)。如果每個神經元都忠實地重複鄰居的訊息,那是巨大的浪費。側抑制(你在入門篇學過的機制)在這裡有了更深的詮釋:它的數學功能其實是白化(whitening)——移除空間上的冗餘相關,讓每個神經元攜帶的訊息盡量獨立。視網膜神經節細胞那個著名的「中央-周邊拮抗(center-surround antagonism)」感受野,正可以從「在自然影像統計下做最佳去相關」這個原則推導出來。
換句話說,感覺系統的許多「設計」,並不需要逐一硬編碼,而是從一條原則——讓神經反應的統計,去匹配環境輸入的統計——自然湧現。
適應不是疲勞,而是即時的「重新對焦」
回到開頭的動態範圍問題。效率編碼還有一個關鍵推論:最佳的反應曲線會隨環境統計改變而改變。自然界的統計不是固定的——你從室內走到豔陽下,亮度分布整個平移了;你戴上耳機,聲音的對比結構變了。如果神經元的反應曲線是固定的,它在新環境下就會「飽和」或「沉默」,浪費頻寬。
所以感覺系統演化出適應(adaptation)——一種在多重時間尺度上持續進行的增益控制(gain control)。請特別注意:適應不等於疲勞或耗竭。它是一個主動、有計算目的的歷程,目的是把神經元有限的反應範圍,動態地「對準」當下最常見的刺激區間。
這在實驗上可以用 Adrienne Fairhall 與 William Bialek 等人的工作來理解:當他們改變刺激的變異數(variance,可理解為對比的強弱)時,神經元的輸入-輸出函數會在數百毫秒內沿著輸入軸縮放(rescaling)——高變異環境下曲線變寬、斜率變緩;低變異環境下曲線變窄、斜率變陡。而且這個縮放幾乎正好維持了固定的資訊傳輸率。神經元不是被動地累了,而是聰明地換檔。
看一個例子:瀑布錯覺與運動後效
請你盯著一段持續往下流動的瀑布看 30 到 60 秒,然後把視線移到旁邊靜止的岩石上。岩石看起來會緩緩向上漂移——儘管它明明是靜止的。這就是運動後效(motion aftereffect, MAE),俗稱「瀑布錯覺(waterfall illusion)」,亞里斯多德的時代就有記載。
它的機制是適應的絕佳示範。視覺皮質(如 MT/V5 區)裡有偵測不同運動方向的神經元,它們彼此以「對立」方式平衡——「向下」細胞群與「向上」細胞群的活動相減,得到你感知到的運動。當你長時間看向下的運動,「向下」細胞群被持續驅動、增益被調降(適應);此時再看靜止畫面,靜止本應讓兩群細胞活動相等、相互抵消,但因為「向下」群被壓低了,平衡被打破,「向上」群相對佔了上風——於是你「看到」了不存在的向上運動。
這個例子的深層啟示是:你感知到的「靜止」與「運動」,其實是兩群相對立神經元的差值,而這個基準線會被最近的歷史悄悄移動。 適應不是 bug,而是讓系統永遠對「變化」最敏感的 feature——畢竟在自然界,會動的東西(掠食者、獵物)通常比靜止的背景更值得你立刻注意。
數量、時序、與群體:訊息藏在哪裡?
入門篇談的是「哪一條神經被活化」(標籤線原理,labelled line)。但進階的問題是:就算鎖定一條神經元,訊息究竟編碼在它的什麼性質裡? 神經科學長期有一場「率編碼 vs. 時序編碼」的辯論。
-
率編碼(rate coding):訊息在於一段時間窗內的平均發射率。刺激越強,每秒動作電位越多。這是最早由 Edgar Adrian(1932 年諾貝爾獎)在蛙的牽張感受器上發現的——他看到刺激強度與放電頻率的單調關係。率編碼穩健、抗雜訊,但「慢」:要估計一個平均率,需要累積時間。
-
時序編碼(temporal coding):訊息在於動作電位精確的時間結構,而非只是平均。聽覺是最有力的例子——你的聽覺神經會把放電「鎖定」在聲波的特定相位上(相位鎖定,phase locking),讓兩耳之間僅僅幾十微秒的時間差(interaural time difference, ITD)就能被偵測出來,這是你定位低頻聲源左右方位的基礎。Carr 與 Konishi 在倉鴞身上發現的「延遲線(delay line)+ 重合偵測(coincidence detector)」迴路,是時序編碼的教科書範例。
-
群體編碼(population coding):許多訊息並不在單一神經元,而在一整群神經元的活動向量裡。經典案例是 Apostolos Georgopoulos 在運動皮質發現的群體向量(population vector):單一神經元只「粗略偏好」某個方向,但把上百個神經元的偏好方向,依其活動強度加權求和,就能精準解碼出手臂實際的運動方向。感覺系統同理——氣味的組合編碼、顏色的對立通道,本質上都是群體編碼。它的好處是容錯(少數神經元壞掉不致命)與高解析度(群體能比任何單一成員都更精確,這叫超敏銳,hyperacuity)。
這三者不是互斥的。真實的感覺系統往往同時用率、時序與群體三種維度承載不同訊息,像一條多工的通道。
把錯覺、適應、先驗統一起來:貝氏觀察者
現在我們把前面的線索收攏成一個數學框架。入門篇說「知覺是大腦的最佳猜測」——進階版本是:這個猜測可以寫成貝氏推論(Bayesian inference)的形式。
大腦想知道世界的真實狀態 (s)(例如物體真正的運動速度、光源真正的方向),但它只能拿到帶雜訊的感覺證據 (x)。貝氏定理告訴我們,最合理的估計來自:
後驗(posterior) ∝ 似然(likelihood)× 先驗(prior)
- 似然 (P(x\mid s)):感覺輸入有多可靠。雜訊越大、訊號越弱,似然就越「寬」(不確定)。
- 先驗 (P(s)):大腦對「世界通常長什麼樣」的內建假設,是長期演化與經驗統計(也就是效率編碼學到的環境統計)的沉澱。
- 後驗 (P(s\mid x)):兩者相乘後的最佳信念,知覺就讀取這個後驗(通常取其峰值或期望值)。
這個框架的威力在於它能定量解釋許多現象:
-
錯覺不是大腦犯錯,而是先驗在發揮作用。 一個經典例子是運動感知的「慢速先驗(slow-speed prior)」:自然界大多數東西移動得慢,所以大腦預設低速。當感覺證據很弱(低對比、昏暗),似然很寬,後驗就被先驗往「慢」拉。這正是為什麼昏暗中物體看起來移動得比實際慢——也解釋了某些車禍中駕駛低估了暗處來車的速度。
-
適應就是先驗(或似然)的動態更新。 前面講的運動後效,可以理解為近期統計改變了系統的基準/先驗。貝氏框架讓「適應」與「學習」變成同一件事的不同時間尺度。
-
多感覺整合是「最佳加權平均」。 當你同時用眼睛和手感知一個物體大小,大腦會依各感覺的可靠度(似然寬度的倒數,即精確度 precision)來加權——哪個感覺此刻更可靠,就更聽它的。Ernst 與 Banks(2002)用視覺-觸覺實驗精準驗證了人類的整合行為,與貝氏最佳整合的預測在統計上無法區分。麥格克效應之所以發生,正是因為在判斷子音時,視覺(嘴型)的可靠度有時高於聽覺。
於是「主動推論(active inference)」「預測編碼」「效率編碼」「適應」這些看似分散的詞彙,在貝氏-自由能的數學底下,其實是同一座大山的不同側面:大腦持續地用先驗預測輸入、用輸入修正先驗,並把神經資源花在最不確定(最有資訊量)的地方。
重點回顧
- 效率編碼假說(Barlow) 主張感覺神經元被環境統計雕刻,以最少活動傳遞最多資訊。Laughlin 的蒼蠅實驗證明反應曲線等於刺激分布的累積分布函數;側抑制的本質是去相關/白化。
- 適應(adaptation)不是疲勞,而是增益控制:神經元在數百毫秒內沿輸入軸縮放反應曲線,動態對準當下的刺激變異數,藉此維持近乎固定的資訊傳輸率。瀑布錯覺(運動後效)是其行為證據。
- 訊息可藏在三個維度:率編碼(平均發射率,穩健但慢)、時序編碼(精確時間,聽覺 ITD 達微秒級)、群體編碼(活動向量,容錯且能超敏銳)。三者常同時運作。
- 貝氏觀察者框架 把知覺寫成「後驗 ∝ 似然 × 先驗」,能定量解釋慢速先驗造成的錯覺、依可靠度加權的多感覺整合(Ernst & Banks),並把適應、學習、預測編碼統一起來。
- 核心轉變:感覺系統的目標不是「忠實複製世界」,而是「在有限資源下,對最有資訊量的部分做最佳推論」。
深入探討(研究所視角)
1. 自然刺激統計與「自然主義轉向」。 早期感覺生理學多用光點、正弦光柵、純音等簡化刺激,但效率編碼假說邏輯上要求我們用自然刺激(naturalistic stimuli)來檢驗——因為神經元是被自然統計優化的,餵它人工刺激可能完全錯估它的計算。這帶來方法學上的「自然主義轉向(naturalistic turn)」:研究者改用自然影像、真實語音、自由觀看的電影片段,搭配如最大雜訊熵(maximum noise entropy)、廣義線性模型(GLM)與深度編碼模型(deep encoding models)來估計感受野。一個富有張力的發現是:在自然刺激下,許多神經元的反應遠比在人工光柵下更稀疏、更非線性,這支持了 Olshausen 與 Field(1996)的稀疏編碼(sparse coding)——他們證明,若要求一組基底函數既能重建自然影像、又讓任一時刻只有少數單元活化,學出來的基底竟自發地長成 V1 簡單細胞那種「局部、定向、多尺度」的感受野。這把效率編碼從「去相關」推進到「稀疏性」這個更強的目標函數。
2. 增益控制的生物物理與規範性張力。 增益控制(gain control)在機制層次有多種實現:突觸短期可塑性(short-term depression)、抑制性迴路的除法正規化(divisive normalization,Heeger 1992)、神經調質(如乙醯膽鹼、正腎上腺素調節皮質增益與訊雜比)、乃至離子通道層次的適應電流。除法正規化尤其重要——它是一個被反覆發現的規範性運算(canonical computation),從 V1 對比正規化、嗅球的群體正規化,到注意力對神經反應的調控,甚至深度學習裡的 normalization 層,都是同一個數學形式的化身。研究所層次的張力在於:規範性理論(normative theory,「系統應該做什麼」) 與 機制理論(mechanistic,「系統實際怎麼做」) 之間如何對接——效率編碼告訴你最佳曲線該長怎樣,但真正的神經元用的是有限、帶雜訊、能耗受限的生物元件,兩者的落差正是當代計算神經科學最肥沃的研究地帶。值得一提的是,代謝能耗(metabolic cost) 應被納入目標函數:動作電位昂貴,所以「效率」的完整版本是「每焦耳能量傳遞最多資訊」,這部分修正了純資訊論的預測,也解釋了為何稀疏編碼在能量上如此划算。
3. 與 AI 的雙向對話,以及對優心理/優生物的連結。 貝氏知覺與深度學習正在快速融合:變分自編碼器(VAE)、擴散模型(diffusion model)本質上都在做「似然 × 先驗」的生成式推論,與大腦的預測編碼在數學上同源;而神經科學啟發的正規化、適應、稀疏性也反過來改良了 AI 模型的穩健性與能效。但要謹慎一個陷阱:深度網路中間層能預測 IT 皮質反應,不代表機制相同——人工網路缺乏生物的回饋連結、時序動態、增益自適應與能耗約束。對連結 優生物學,本文的關鍵詞是「發育與經驗如何雕塑感受野」:稀疏編碼基底要在發育中靠自然輸入學出來,呼應視覺關鍵期可塑性與感覺剝奪研究。對連結 優心理學,貝氏框架提供了把「個體差異」操作化的工具——例如有理論主張,自閉特質與某些感覺處理差異,可以用「先驗權重過低/感覺精確度過高」來建模(precise-likelihood/weak-prior 假說),讓主觀的知覺經驗差異變成可量化、可實驗的精確度參數。延伸思考方向:如果知覺是貝氏推論,那「先驗」存在大腦的哪裡、以什麼突觸形式儲存?當預測與輸入長期嚴重失配(如幻覺、慢性疼痛、耳鳴),是否正是「先驗失靈」或「精確度錯配」的臨床表現?從感覺編碼出發,你已經站在計算精神醫學(computational psychiatry)的入口。