
神經元每天都在「變心」,解碼器卻必須跟上
當大腦是一個非定態系統:用神經流形、貝氏狀態推論與雙智能體控制,重新理解腦機介面如何讀寫一個會自己變動的大腦。
神經元每天都在「變心」,解碼器卻必須跟上
假設你昨天花了一整個下午,幫一位癱瘓的受試者校準好一台腦機介面(Brain-Machine Interface, BMI)。游標流暢地滑向每一個目標,準確率漂亮得像示範影片。今天他回到實驗室,同一片電極、同一套解碼器(decoder)、同一個人——可是游標卻開始飄移,彷彿昨天的努力一夜蒸發。沒有人動過任何參數,到底發生了什麼事?
入門篇告訴你腦機介面有「擷取、解碼、控制、回饋」四個環節,也告訴你大腦與機器會在回饋中共同學習。但那是一張靜態的快照。真實世界裡,這套系統運行在一個會自己變動的基底之上:神經訊號本身就不穩定、群體活動每天都在悄悄重組、而你正試圖用一個固定的數學模型去追一個移動的標靶。這篇進階文章要處理的,正是入門篇刻意略過的硬核問題——當大腦是一個非定態(non-stationary)的系統,我們到底該用什麼樣的數學語言去讀它、追它、與它共舞。
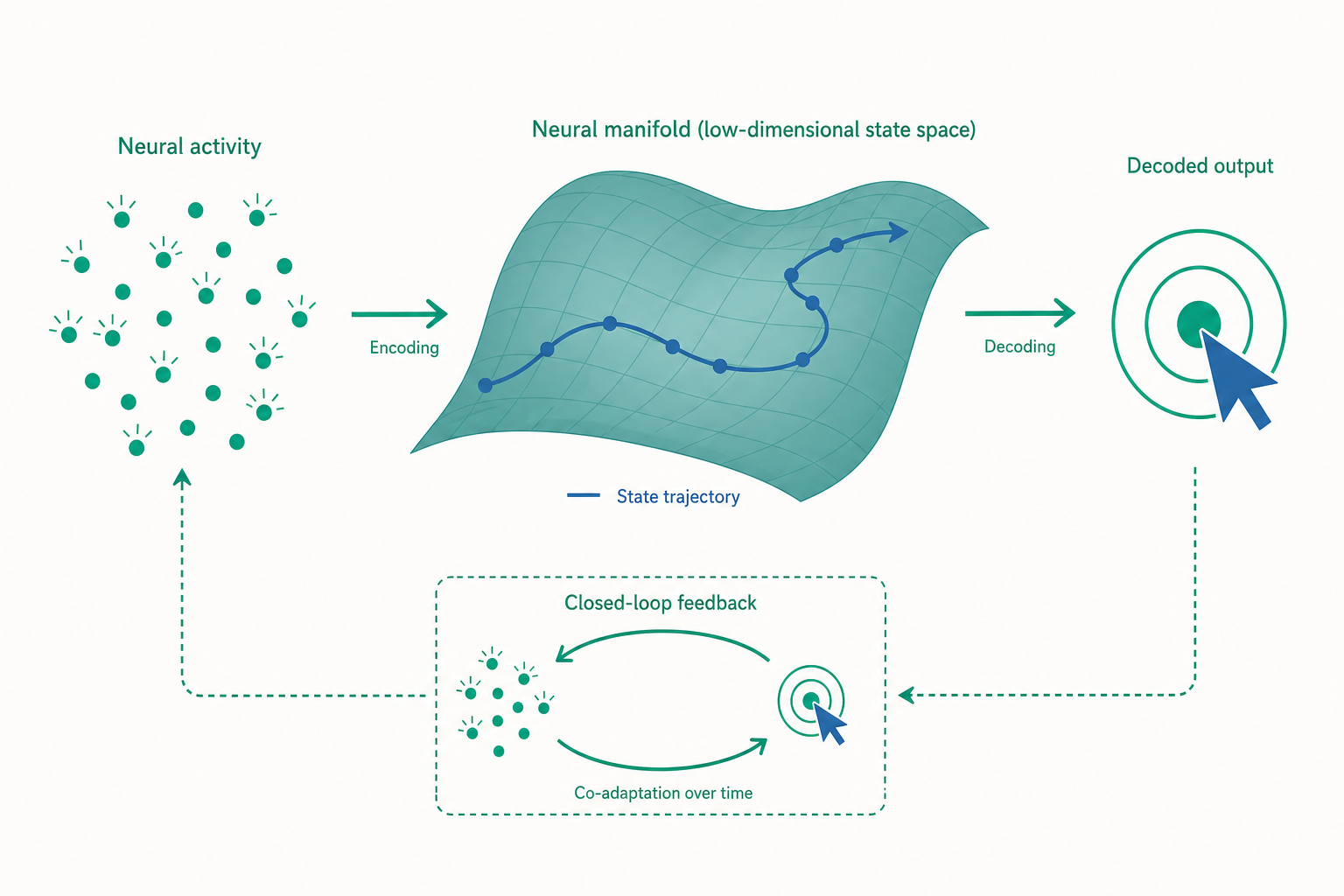
從「一顆神經元」退一步:神經流形的觀點
入門篇用「群體向量」(population vector)解釋了意圖如何分散在一群神經元裡。那是一九八○年代的語言。今天計算神經科學(computational neuroscience)看待運動皮質的方式,已經換了一副眼鏡——這副眼鏡叫神經流形(neural manifold)。
想像你同時記錄一百顆神經元的放電率。在數學上,每一個瞬間的群體狀態,就是一個一百維空間裡的點。直覺上你會以為,這些點會散布在整個一百維空間裡。但實驗反覆發現一件驚人的事:這些點並不到處亂跑,它們幾乎都落在一個低維度的曲面(流形)上。 一百顆神經元的活動,實際的「自由度」可能只有八維、十維。
這背後的原因是神經元之間高度相關——它們不是各自為政的一百個獨立旋鈕,而是被少數幾個底層的「指揮訊號」(latent factors,潛在因子)協同驅動。Mark Churchland、Krishna Shenoy 等人在二〇一二年《Nature》提出的觀點更進一步:運動皮質的群體活動,更像一個動力系統(dynamical system)——它在這個低維流形上沿著某種規律的軌跡演化,而手臂的運動,是這條神經軌跡「投影」出來的結果。神經元不是在「編碼方向」這麼靜態的事,它們是在「生成一段隨時間展開的運動」。
這個視角為什麼對腦機介面是革命性的?因為它把問題從「讀懂每一顆神經元在說什麼」,轉化成「找出那個穩定的低維流形,並追蹤狀態在上面的位置」。而流形,比起任何單一神經元,要穩定得多——這正是對付文章開頭那個「一夜蒸發」之謎的鑰匙。
看一個例子:為什麼游標會飄?
回到開頭的謎題。隔夜之間,你記錄到的某顆神經元可能因為電極相對腦組織的微小位移、阻抗變化或週遭環境,發放強度整個變了;某幾顆昨天還清晰的神經元,今天訊號淹沒在雜訊裡。如果你的解碼器是直接把「每顆神經元的放電」映射到「游標速度」,那麼任何一顆神經元的脾氣改變,都會直接污染輸出——這就是神經漂移(neural drift)在解碼器層面造成的災難。
但研究者(如 Karunesh Ganguly 與 Jose Carmena 的長期記錄、以及後來大量的群體動態研究)發現:儘管「哪顆神經元負責什麼」會變,整個群體所張開的那個低維流形,在跨日尺度上相對穩定。換句話說,演奏的樂手換了座位、有人感冒了,但整首曲子的調性還在。
於是新一代的策略是:先把今天的群體活動「對齊」(align)到昨天那個穩定的流形上——這在技術上往往透過尋找一個線性轉換,讓今天的潛在狀態分布去匹配歷史分布(這類方法常被稱為流形對齊,manifold alignment)——再讓固定的解碼器在流形座標上運作。游標飄移,從「重新訓練整個系統」變成「校正一個低維的座標轉換」。這就是把「神經流形」從一個漂亮的科學概念,落地成解決工程難題的實用工具。
解碼器的真身:一個潛在狀態的推論問題
入門篇提到了卡爾曼濾波器(Kalman filter)與深度學習。這裡我們把它們放進同一個更深的框架裡看——狀態空間模型(state-space model)與貝氏推論(Bayesian inference)。
腦機介面解碼,本質上是一個潛在狀態估計問題。使用者的「意圖」(例如手要去的位置與速度)是一個看不見的潛在狀態 $z_t$,它隨時間按某種動力學演化;而你觀測到的神經放電 $y_t$,是這個潛在狀態的一個帶雜訊的、非線性的投影。解碼器的任務,是反過來從 $y_t$ 推回 $z_t$。
用貝氏的語言寫,你想求的是後驗機率 $p(z_t \mid y_{1:t})$——「在看過至今所有神經訊號之後,意圖最可能是什麼」。這個式子優雅地拆成兩塊:
- 預測(prediction):根據上一刻的意圖與一個動力學模型,預測這一刻意圖大概在哪——這是先驗。
- 更新(update):用這一刻新進來的神經觀測,去修正那個預測——這是似然。
卡爾曼濾波器,正是這個貝氏遞迴在「線性動力學+高斯雜訊」這個特例下的精確解。它之所以在腦機介面早期那麼成功,不只因為它即時、輕量,更因為它內建了「平滑性」這個先驗——它假設意圖不會瞬間亂跳,於是天然地把抖動的神經雜訊濾掉,讓游標滑順。
理解了這個框架,深度學習的角色就清楚了:當潛在狀態與神經觀測之間的關係高度非線性、動力學不再是簡單的線性時,卡爾曼的假設就太天真了。遞迴神經網路(RNN)、特別是後來的序列模型,本質上是在學一個更有表達力的非線性狀態空間——它們學的不只是「神經訊號 → 意圖」的瞬間映射,更是把神經活動本身那套內在動力學也納入模型(這類工作如 LFADS, Latent Factor Analysis via Dynamical Systems,用循環網路去推論群體活動背後的潛在動力)。所以從卡爾曼到深度學習,不是換了個流派,而是在同一個潛在狀態推論的階梯上,往更複雜的動力學爬了好幾階。
這也是腦機介面與 AI 的另一層深刻連結:你在這裡用的數學——狀態空間、貝氏濾波、潛在變數——和語音辨識、機器人定位(SLAM)、時間序列預測背後是同一套。讀大腦,與其他「從帶雜訊的序列推論隱藏狀態」的問題,共享著同一副骨架。
把訊號鏈拆開:spike、雜訊與那個被忽略的前處理
入門篇直接從「神經訊號」跳到「解碼」,但中間其實藏著一段又髒又關鍵的工程,決定了一切的上限。
微電極記錄到的原始電壓,是一團混合物:有你想要的動作電位(spike)、有附近好幾顆神經元的放電疊在一起、有局部場電位(local field potential, LFP)的低頻起伏,還有大量的熱雜訊與環境干擾。傳統流程裡有一道叫棘波分類(spike sorting)的工序——根據波形形狀,判斷每一個 spike 是「哪一顆」神經元發出的,好把訊號歸戶到單一神經元(single unit)。
這道工序聽起來理所當然,卻是腦機介面裡一個被認真質疑的環節。原因有二。第一,spike sorting 很容易出錯,而且它的錯誤會隨時間漂移(又是漂移!),人工校準成本高昂。第二,也更深刻:從前面神經流形的觀點看,「精確分出是哪一顆神經元」也許根本不必要。 既然意圖編碼在群體層次、在低維流形上,那麼直接拿「未分類的多單元活動」(multi-unit threshold crossings,只判斷有沒有超過閾值的 spike,不管是誰發的)餵給解碼器,效能往往幾乎不打折。這是一個漂亮的、由科學洞見反過來簡化工程的案例——當你理解資訊住在群體裡,你就不再執著於還原每一個個體。
這裡有一個值得放在心裡的張力:腦機介面的效能,常常不是被解碼演算法限制,而是被訊號的資訊量本身限制。 一片電極能拿到多少獨立的、與意圖相關的神經訊息,是一個物理與生物的硬上限。再聰明的 AI,也變不出原始訊號裡沒有的資訊。這呼應了訊號處理裡的資訊瓶頸觀念——演算法能做的,是逼近那個上限,而不是突破它。所以這個領域的進步,一半來自更好的演算法,另一半(也許更關鍵的一半)來自更高密度、更穩定、能記錄到更多神經元的電極硬體。
共適應,其實是一個雙智能體的控制問題
入門篇把回饋與可塑性比喻成「雙人舞」——機器在學,人腦也在學。這個比喻很美,但作為進階學習者,你該看見它底下藏著一個更尖銳、甚至有點危險的結構:這是兩個會學習的智能體(agent),在同一個閉環裡,同時改變對方腳下的地面。
把它拆開來看。解碼器是一個學習系統,它假設「使用者的神經活動 → 意圖」的映射是固定的,然後去擬合它。使用者的大腦也是一個學習系統,它假設「我這樣發放 → 游標這樣動」(也就是解碼器)是固定的,然後去適應它。問題是:兩邊的假設同時都不成立——因為對方也在變。
這在控制論與機器學習裡是一個典型的非定態、移動標靶問題。如果處理不當,兩個學習者會互相追逐、震盪,甚至一起跑向一個誰都不滿意的爛策略。但如果設計得當——例如讓解碼器的學習速率與使用者大腦的可塑性節奏「錯開」或「協調」——兩者就能協同收斂到一個雙方都省力、都精準的共同控制策略。這正是「共適應式腦機介面」(co-adaptive BMI)的核心研究課題:不是讓機器一味去逼近大腦,也不是讓大腦一味去屈就機器,而是設計一個能保證兩個學習者穩定收斂的耦合動力學。
這個視角一旦建立,你會發現它和優心理裡的技能習得與強化學習(reinforcement learning)驚人地相通。使用者的大腦其實在做一件很像強化學習的事:用「游標有沒有更接近目標」當作回饋訊號(某種獎勵),去調整神經輸出策略。事實上已有研究探討,運動皮質的這種「以結果為導向的重塑」,與基底核(basal ganglia)的多巴胺(dopamine)獎勵學習系統可能有所牽連——大腦把「驅動一個外部裝置」當成一項新技能,動用了它本來就用來學騎車、學打字的那套神經機制。腦機介面因此意外地成了一扇窗,讓我們反過來研究人腦如何學習一項全新的運動技能。讀寫大腦的工具,回過頭來變成了探測大腦學習法則的探針。
重點回顧
- 神經流形(neural manifold)是理解現代解碼的關鍵:一群神經元的活動其實落在低維曲面上,由少數潛在因子協同驅動;運動皮質更像一個在流形上演化的動力系統,而非靜態的「方向編碼器」。
- 流形的穩定性是對付神經漂移的解方:「哪顆神經元做什麼」會跨日改變,但群體張開的流形相對穩定,因此用流形對齊校正一個低維座標轉換,遠勝於每天重訓整個解碼器。
- 解碼本質是潛在狀態的貝氏推論:卡爾曼濾波器是「線性+高斯」特例下的精確解,深度學習則是在同一個狀態空間階梯上爬向更複雜的非線性動力學——兩者同源,不是兩個流派。
- 訊號鏈的前處理決定上限:spike sorting 未必必要(群體層次的多單元活動往往就夠),而效能常被原始訊號的資訊量(硬體)限制,而非演算法限制。
- 共適應是雙智能體的非定態控制問題:人腦與解碼器同時學習、互相改變對方的地面,設計重點是讓兩個學習者穩定協同收斂;這條線索也把腦機介面連向強化學習與大腦的獎勵學習機制。
深入探討(研究所視角)
對想再往前一步的同學,這裡有幾條更前沿、也更開放的線索。
第一,跨日、跨人的「神經對齊」與遷移學習。 如果今天的流形能對齊到昨天,那能不能把 A 受試者學到的解碼結構,遷移給 B 受試者,省掉漫長的校準?這牽涉到一個深刻的科學問題:不同個體的運動皮質,是否共享某種規範性(canonical)的低維幾何?近年用對齊技術(如典型相關分析 CCA、或基於最優傳輸 optimal transport 的方法)跨受試者對齊神經流形的研究,正在試探這個邊界。它的答案,將決定腦機介面是必須「一人一校準」的客製品,還是有機會變成「即插即用」的標準裝置。
第二,從點過程(point process)的角度重寫似然。 我們前面把神經觀測寫成帶高斯雜訊的連續量,那是近似。spike 本質上是離散的事件序列,更嚴謹的模型是點過程——用一個隨時間變化的瞬時發放率(conditional intensity)來描述「下一個 spike 何時來」。基於點過程的解碼器(如點過程濾波器)在低發放率、需要極短時間窗的場景下理論上更精確。這條路把神經統計學(neural statistics)與解碼緊密結合,是計算神經科學裡相當硬核的一支。
第三,寫入端的逆問題遠比讀取兇險。 入門篇說「寫入比讀取難」,難在哪裡值得具體說。讀取是一個前向的推論:給定神經活動,估計意圖。寫入卻是一個逆問題(inverse problem):我想讓大腦產生某個感知,該施加什麼樣的時空電刺激模式?這個逆映射往往是病態的(ill-posed)——多種刺激可能對應到難以預測的感知,而電流會非線性地擴散、激活一整片你沒打算碰的神經元。更棘手的是,被刺激的大腦會立刻可塑性地反應,使得「刺激 → 感知」的對應本身也在變。如何閉環地、即時地校正刺激以產生穩定可控的人工感覺,是讀寫雙向腦機介面(bidirectional BMI)最深的難關之一。
最後,回到一個謙遜的提醒:相關不等於因果,解碼不等於理解。 一個解碼器能從神經活動準確預測意圖,並不代表我們理解了大腦如何產生意圖。解碼成功,可能只是抓到了一個與意圖高度相關的代理訊號。把「能解碼」誤當成「已理解神經編碼」,是這個領域常見的認識論陷阱。對研究者而言,最有價值的工作往往不是再把準確率刷高一個百分點,而是去問:這個模型學到的潛在結構,是否真的對應到大腦運算的某種機制?這也正是計算神經科學、AI 可解釋性與神經科學在腦機介面交會處,最迷人也最不容易的功課——而它連向的,正是 Educational Omics 框架中 Cognomics(認知歷程)維度最根本的提問:我們究竟能不能、又該如何,從外顯訊號回推內在的心智運算。