
當一個念頭被「拍」了下來
從 fMRI 的血流訊號到 EEG 的毫秒電位,理解各種腦造影技術「看見」的究竟是什麼,以及彩色斑塊背後的時間—空間取捨與統計陷阱。
當一個念頭被「拍」了下來
1991 年的某天,麻省總醫院(Massachusetts General Hospital)的一群研究者讓一位受試者躺進磁振造影(Magnetic Resonance Imaging, MRI)儀器裡,請他在黑暗中閉眼,再忽然睜眼看一片閃爍的棋盤格。掃描儀沒有電極插進腦袋,沒有任何切片,但螢幕上,受試者初級視覺皮質(primary visual cortex, V1)的位置卻悄悄地「亮」了起來——亮的不是神經元本身,而是流向那片皮質的血液。
這就是功能性磁振造影(functional MRI, fMRI)登場的瞬間。從那一刻起,我們第一次能在不打開顱骨、不傷害任何組織的前提下,「看見」一個活著的、正在思考的大腦在做什麼。
但這裡藏著一個關鍵問題,也是本文要層層拆解的核心:腦造影到底「看見」了什麼? 你以為螢幕上那塊發亮的彩色斑塊就是「思考本身」,其實它只是思考留下的某種間接痕跡——而且不同的造影技術,捕捉到的痕跡完全不一樣。理解這個落差,是讀懂任何一篇腦科學新聞、任何一張腦圖的第一步。
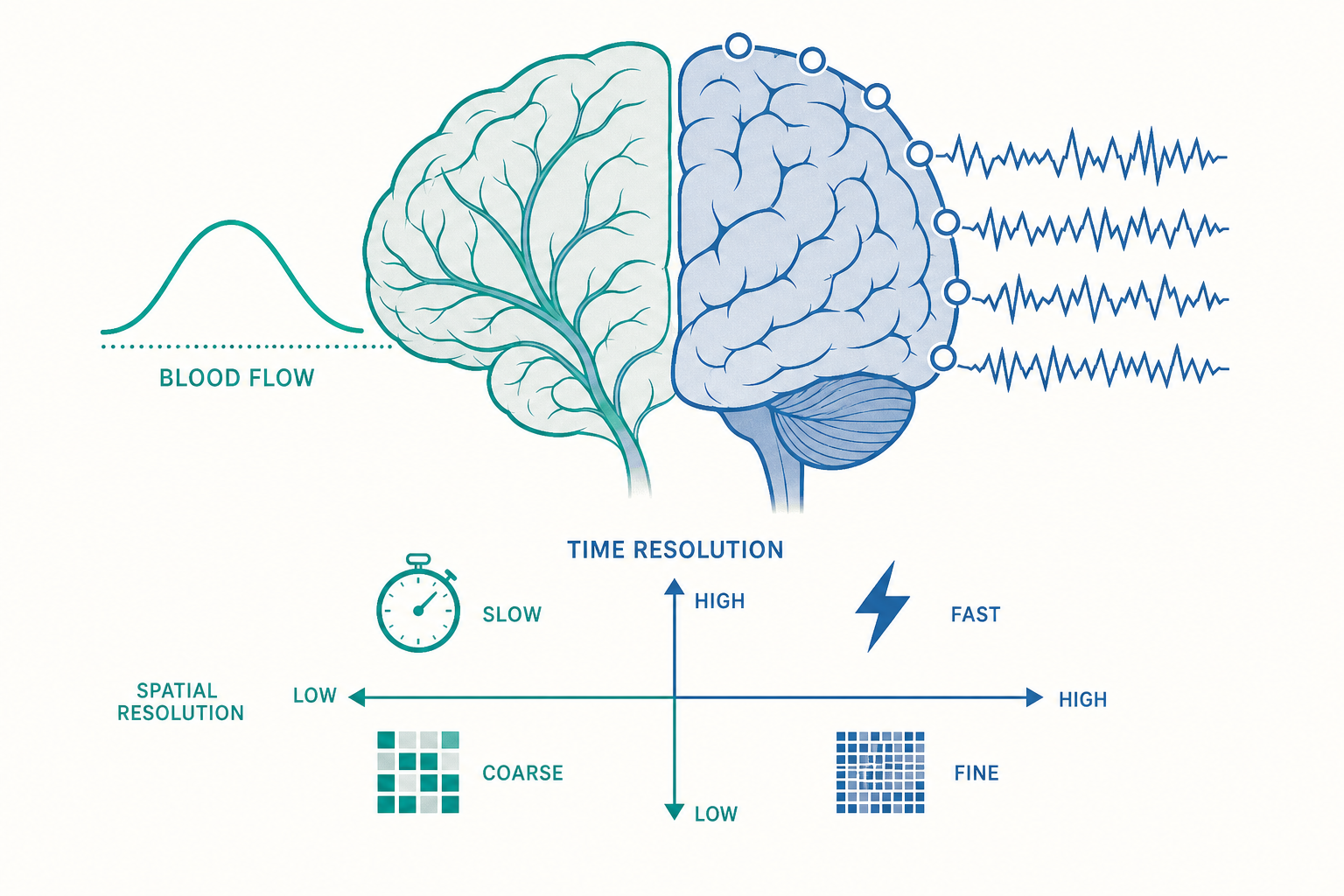
兩種根本不同的「看見」:訊號從哪裡來
要理解腦造影,先要分清楚大腦活動會留下哪兩類可被偵測的痕跡。
第一類是電與磁的痕跡。神經元溝通靠的是電訊號:當一個神經元被激發,離子(主要是鈉、鉀、鈣)穿過細胞膜進出,產生電位變化。成千上萬個神經元同步放電時,這些微弱電流會疊加,在頭皮表面產生可被測量的電壓波動——這就是腦電圖(Electroencephalography, EEG)的來源。電流流動同時會產生極微弱的磁場,由腦磁圖(Magnetoencephalography, MEG)捕捉。
第二類是代謝與血流的痕跡。神經元放電要消耗能量,能量來自氧氣與葡萄糖,由血液運送。當某塊腦區忙碌起來,身體會「超額供應」——送來的含氧血遠多於實際消耗,造成局部含氧血紅素(oxyhemoglobin)與缺氧血紅素(deoxyhemoglobin)比例改變。由於這兩種血紅素的磁性不同(缺氧血紅素具順磁性),fMRI 便能偵測到這個變化,稱為血氧濃度相依訊號(Blood-Oxygen-Level-Dependent signal, BOLD signal)。
這個區分至關重要,因為它直接決定了兩件事:時間解析度(能多精準地分辨「何時」發生)與空間解析度(能多精準地分辨「在哪裡」發生)。電訊號以毫秒(millisecond)為單位瞬間發生,血流反應卻要花好幾秒才達到高峰。這就埋下了後面所有取捨的種子。
fMRI:用血流追蹤思考的「在哪裡」
fMRI 是當代認知神經科學最常用的工具,它的強項是空間解析度。一台 3 特斯拉(Tesla)的標準研究用機器,可以把大腦分割成數十萬個邊長約 2 到 3 毫米的立方體小單元,稱為體素(voxel,volume + pixel 的合成詞)。每個體素記錄該位置的 BOLD 訊號隨時間的變化。
但 BOLD 訊號有個無法迴避的特性:它是血流動力學反應(hemodynamic response),不是神經放電本身。當一群神經元活躍後,BOLD 訊號要約 1 到 2 秒才開始上升,4 到 6 秒才達到高峰,然後緩慢回落,前後拖約 12 至 20 秒。換句話說,fMRI 看到的「思考」,其實是思考發生後好幾秒、被血管系統「低通濾波」過的模糊回聲。
這帶來一個常被誤解的觀念:fMRI 的時間解析度差,並不全是機器掃描慢的問題,而是被生理現象本身限制住的。 即使你能每 0.1 秒掃一次全腦,你量到的仍是那條拖泥帶水的血流反應曲線,無法直接還原毫秒級的神經事件。
看一個例子:減去法如何「分離」出一個心理歷程
假設我們想知道大腦的哪個區域負責「辨認人臉」。我們不能直接問「請啟動辨臉區」,於是認知神經科學用一個經典策略:認知減去法(cognitive subtraction)。
設計兩種情境: - 情境 A:受試者看一連串人臉照片。 - 情境 B:受試者看一連串房屋照片。
兩種情境都涉及「看見圖片」「視覺處理」「保持專注」等共通歷程。理論上,把 A 的腦活化「減去」B 的腦活化,那些共通成分會互相抵消,剩下的就是專屬於辨臉的部分。1997 年 Nancy Kanwisher 團隊正是用類似邏輯,定位出梭狀回臉孔區(Fusiform Face Area, FFA)——一塊在看到臉時特別活躍的腹側顳葉皮質。
減去法很漂亮,但它有個內建假設叫純粹插入假設(pure insertion):你以為只是「多加了辨臉這一步」,但實際上換成人臉可能連帶改變了情緒喚起、注意力分配等其他歷程。這個假設不見得永遠成立,正是後來研究者改用更複雜設計(如參數化調控、多體素模式分析)的原因。這也提醒學習者:腦造影的結論強度,高度依賴實驗設計,而非機器本身。
EEG:用毫秒捕捉思考的「何時」
如果說 fMRI 擅長回答「在哪裡」,EEG 就是回答「何時」的大師。EEG 把一組電極(從幾顆到 256 顆不等)貼在頭皮上,直接記錄神經電活動的電壓波動,時間解析度可達毫秒級。
EEG 量到的主要是大腦皮質錐體細胞(pyramidal cells)的突觸後電位(postsynaptic potentials)總和。這裡有個常見迷思要破除:EEG 量的不是動作電位(action potential,神經元的「放電」尖峰),而是突觸後較緩慢、可持續較久的電位變化。 動作電位太短、太不同步,在頭皮表面幾乎彼此抵消,量不到。
EEG 最強大的分析方式之一是事件相關電位(Event-Related Potential, ERP)。單次刺激引發的腦電變化淹沒在背景雜訊裡,但若把同一種刺激重複數十、數百次,再把每次刺激後的腦電波對齊、平均,隨機雜訊會互相抵消,剩下與刺激「鎖時」的穩定波形。
幾個經典 ERP 成分值得學習者記住: - P300:刺激後約 300 毫秒出現的正向波,與注意力和對「意外/罕見刺激」的偵測有關。 - N400:約 400 毫秒的負向波,當語意不協調時會增大(例如「我把咖啡加了襪子」會引發比「加了糖」更大的 N400)。1980 年 Kutas 與 Hillyard 的這項發現,至今仍是語言神經科學的基石。 - 錯誤關聯負波(Error-Related Negativity, ERN):在人犯錯後極短時間內出現,反映大腦的自我監控。
EEG 的代價是空間解析度差。電訊號穿過腦脊髓液、顱骨、頭皮時會被擴散、扭曲,使得「頭皮上某顆電極變強」很難回推到「腦中某一個確切位置」。這個從頭皮訊號反推腦內來源的難題,數學上稱為逆問題(inverse problem),它沒有唯一解——同一組頭皮電壓,理論上可由無限多種腦內電流分布產生。
動手試試:替每個任務挑對工具
試著替下面三個研究問題,判斷該優先用 fMRI 還是 EEG,並說出理由:
- 「閱讀句子時,大腦偵測到語意錯誤需要多少毫秒?」
- 「兩種不同的數學解題策略,分別動用哪些腦區?」
- 「淺眠與深眠時,大腦的整體電活動節律有何不同?」
參考答案:第 1 題重點在精確「時間」(毫秒),且 N400 是現成指標 → EEG/ERP。第 2 題重點在精確「位置」(哪些腦區) → fMRI。第 3 題關注的是睡眠時整體的節律性電波(如 delta 波、睡眠紡錘波) → EEG(這也是睡眠醫學的標準工具)。
做完這個練習,你會發現一件事:沒有「最好的」造影技術,只有「最適合這個問題」的技術。 這正是研究方法學的精髓。
時間與空間的根本取捨,與互補之道
把幾種主要技術放在「時間—空間」座標上比較,可以看清整個版圖:
| 技術 | 訊號來源 | 時間解析度 | 空間解析度 | 侵入性 |
|---|---|---|---|---|
| EEG | 頭皮電位 | 極佳(毫秒) | 差(公分級) | 無 |
| MEG | 頭皮磁場 | 極佳(毫秒) | 中等 | 無 |
| fMRI | BOLD 血流 | 差(秒級) | 佳(毫米) | 無 |
| PET | 放射性示蹤劑 | 很差(分鐘級) | 中等 | 有(注射) |
| fNIRS | 近紅外光血氧 | 中等 | 中等(淺層) | 無 |
這張表透露一個深刻的限制:目前沒有任何單一非侵入技術能同時擁有毫秒級時間與毫米級空間解析度。 EEG 與 MEG 快但模糊,fMRI 準但遲緩,這幾乎是物理與生理的天花板。
正因如此,現代研究越來越走向多模態整合(multimodal integration):例如同步記錄 EEG 與 fMRI,用 fMRI 提供「在哪裡」的空間約束,幫助 EEG 解逆問題,定位電活動的腦內來源;同時用 EEG 提供「何時」的毫秒時序,補足 fMRI 的時間盲區。這也是優生物學中「結構決定功能」概念在工具層面的延伸——不同尺度的測量,拼湊出完整的生命機制圖像。
此外還有一個容易被忽略的革命:靜息態功能連結(resting-state functional connectivity)。2005 年前後研究者發現,即使受試者什麼都不做、只是安靜躺著,不同腦區的 BOLD 訊號仍會出現緩慢的、同步起伏的關聯。由此辨識出預設模式網路(Default Mode Network, DMN)等大尺度腦網路——大腦從來不是一塊塊孤立的「功能模組」,而是時刻在進行分散式協作的網路系統。
最該警惕的迷思:彩色斑塊不等於「思考的位置」
媒體上的腦圖常給人一種錯覺:紅色亮塊就是「快樂中樞」「說謊中樞」被點亮了。學習者必須建立幾個批判性認識:
第一,顏色是統計,不是發光。 腦圖上的彩色區塊代表「該體素在某條件下的訊號變化,在統計上達到顯著水準」,紅黃色通常對應較高的統計值(如 t 值或 z 值),而非神經元真的變紅變亮。改變統計閾值,亮塊的大小就會變。
第二,活化不等於必要。 一個區域在某任務中活化,只能說它「參與」了,不代表它「不可或缺」。要證明必要性,需要病灶研究(lesion study)或經顱磁刺激(Transcranial Magnetic Stimulation, TMS)暫時「關閉」該區,觀察功能是否受損。相關不等於因果,這條統計學鐵律在腦造影同樣成立——這一點與優心理、AI 領域對「相關 vs. 因果」的反覆強調完全一致。
第三,當心多重比較陷阱。 全腦 fMRI 動輒數十萬個體素,若對每個體素獨立做檢定而不校正,純靠隨機就會冒出一堆假陽性。2009 年一項著名的諷刺研究,把一條死掉的鮭魚放進掃描儀並「請牠判斷照片中人物的情緒」,結果在未校正下,死魚腦中竟出現了「活化」斑塊。這項拿下搞笑諾貝爾獎的研究,深刻提醒所有人:沒有適當的統計校正(如 FDR、cluster correction),腦圖可以「測出」任何不存在的東西。這與 AI 領域對過度擬合(overfitting)與虛假關聯的警惕,是同一個科學良知。
重點回顧
- 腦造影分兩大類訊號:電磁訊號(EEG/MEG,毫秒級時間解析度)與血流代謝訊號(fMRI/PET,毫米級空間解析度),兩者捕捉的是大腦活動的不同側面。
- fMRI 偵測的是 BOLD 血流動力學反應,而非神經放電本身,因此時間上有數秒延遲;其時間解析度受生理限制,非單純機器快慢問題。
- EEG 量到的是皮質錐體細胞的突觸後電位總和(非動作電位);透過多次平均得到的 ERP(如 P300、N400)可精準捕捉認知歷程的時序。
- 沒有單一非侵入技術能兼顧毫秒與毫米解析度,故發展出 EEG-fMRI 多模態整合;靜息態研究更揭示大腦是分散式網路系統(如 DMN)。
- 腦圖的彩色斑塊是統計顯著性而非「發光」;活化不等於必要,相關不等於因果,且必須做多重比較校正(死魚實驗即為警世範例)。
深入探討(研究所視角)
從神經血管偶聯到 BOLD 模型。 BOLD 訊號的物理基礎可追溯到 1936 年 Linus Pauling 發現缺氧血紅素具順磁性、含氧血紅素具反磁性。Seiji Ogawa 在 1990 年將此原理轉化為 fMRI 的基礎。但真正待解的科學問題是神經血管偶聯(neurovascular coupling):神經活動如何「指揮」局部血流增加?目前認為星形膠細胞(astrocyte)、血管周邊的中間神經元釋放的訊號分子(如一氧化氮、前列腺素)扮演關鍵中介。這意味著 BOLD 並非純粹的神經訊號,而是神經—膠細胞—血管系統的耦合產物,任何改變這個耦合的因素(如老化、咖啡因、某些藥物與疾病)都可能在不改變神經活動的情況下扭曲 BOLD,這是臨床解讀的重大挑戰。
逆問題與貝氏推論。 EEG/MEG 的源定位本質是病態反問題(ill-posed inverse problem),解的非唯一性需靠先驗假設約束。現代方法(如 minimum-norm estimate、beamforming、sLORETA)多採貝氏框架(Bayesian framework),引入解剖學先驗(用個人 MRI 約束電流只能來自皮質灰質)與稀疏性先驗。這與機器學習中正則化(regularization)的數學精神如出一轍——在無限多解中,用先驗知識挑出最合理的那個。這正是 AI 與神經科學的深層交會點。
解碼與多體素模式分析。 傳統 fMRI 問「哪裡活化」,新典範 MVPA(Multi-Voxel Pattern Analysis)則問「腦活化模式裡編碼了什麼資訊」。研究者訓練分類器(如支援向量機 SVM)去學習體素活化的分布模式,進而從腦活動「解碼」受試者正在看什麼物件、想像什麼場景。Kamitani、Gallant 等團隊甚至做到從 fMRI 部分重建受試者觀看的影像。這與深度學習表徵學習(representation learning)緊密呼應,催生了「神經解碼」與腦機介面(Brain-Computer Interface, BCI)的快速發展——而這正連回優心理對「大腦如何表徵世界」的根本提問。
朝向因果與計算模型。 觀察性造影的終極限制是無法建立因果。前沿方向包括:結合 TMS-EEG 主動擾動腦區並觀察網路反應;以生成模型(如動態因果模型,Dynamic Causal Modelling, DCM)推估腦區間的有效連結方向;以及將造影資料餵入計算神經科學模型,反推潛在的神經計算過程。這提醒每一位學習者:腦造影不是終點,而是把生物(優生物)、心智(優心理)與運算(AI)三條線索編織起來的觀測窗口。讀懂一張腦圖,從來不只是看懂顏色,而是看懂背後那一整套關於「測量什麼、能推論什麼、又必須謙卑承認自己看不到什麼」的科學思維。