
大腦在「準備動作」時,到底在算什麼?
從族群向量到動力系統典範:解析運動皮質的旋轉動力學、伯恩斯坦自由度問題、小腦監督式學習與基底核三路徑動作選擇。
大腦在「準備動作」時,到底在算什麼?
你已經知道初級運動皮質(primary motor cortex, M1)的神經元會編碼動作的方向,許多神經元的「族群向量(population vector)」加總後能預測手往哪裡伸。這是個漂亮的故事,影響了三十年的研究與第一代腦機介面。但它有一個藏在角落、長期被忽略的問題:
如果 M1 神經元就是在「表徵」手的方向、速度或肌肉力量,那麼在你還沒動之前——動作準備期(preparatory period)——這些神經元明明已經劇烈活動了,卻沒有任何肌肉收縮,它們到底在表徵什麼?
一隻什麼都還沒動的手,沒有方向、沒有速度、沒有力量。可是猴子實驗裡,M1 與前運動皮質在「看到目標、等待 go 訊號」的那幾百毫秒,神經活動已經忙得不可開交。傳統「表徵論」對此無言以對。這個矛盾,把運動神經科學推向了一個全新的視角——動力系統觀點(dynamical systems view)。這篇進階文章,就從這個矛盾開始。
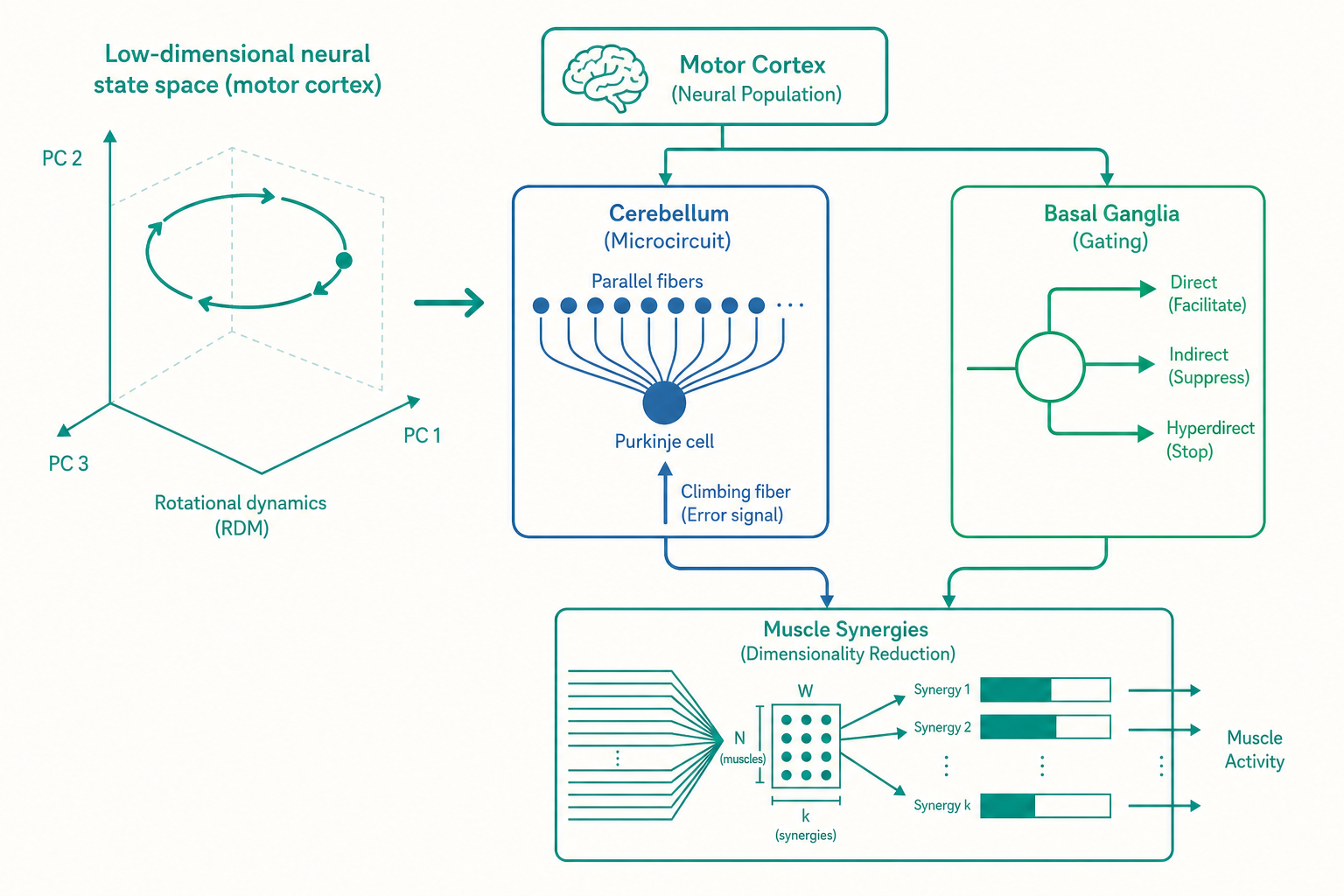
從「表徵」到「動力系統」:一次典範轉移
入門篇把 M1 神經元當成「讀數表」——每個神經元的放電率,對應到某個外在變數(方向、力量、速度)。這是表徵典範(representational paradigm):神經活動是世界的鏡子,我們要做的就是解讀它反映了什麼。
但 2010 年代,丘奇蘭(Mark Churchland)、申諾伊(Krishna Shenoy)等人提出了一個截然不同的問法。他們說:別問「這個神經元在表徵什麼」,改問「整個神經元族群的活動,作為一個動態系統,是怎麼隨時間演化的」。
關鍵概念是神經狀態空間(neural state space)。想像你同時記錄了 200 個 M1 神經元的放電率,那麼在任一瞬間,整個族群的狀態就是一個 200 維空間裡的一個點。隨著時間流動,這個點會在高維空間裡畫出一條軌跡(trajectory)。動力系統觀點主張:運動皮質不是在「描述」動作,而是一台會自己演化的機器,它的內在動力學(dynamics)直接生成了驅動肌肉的時序訊號。
在這個框架下,準備期的活動終於有了意義:它不是在表徵一個還不存在的動作,而是在把系統的狀態設定到一個正確的「初始條件」。就像把彈簧拉到某個起點再放手,後續的彈跳軌跡早已由起點決定。動作準備,就是大腦在替即將上演的神經動力學「設定初始值」。
看一個例子:旋轉動力學(rotational dynamics)
丘奇蘭團隊 2012 年發表於《Nature》的一項分析給了這個觀點最戲劇性的證據。他們讓猴子做各種伸手動作,記錄 M1 與前運動皮質的族群活動,然後用降維方法(類似主成分分析)把高維軌跡投影到少數幾個維度上。
結果令人吃驚:無論是哪一種伸手動作,神經狀態在動作展開時,都在這些維度裡畫出乾淨的旋轉(rotation)軌跡——像時鐘指針一樣轉圈。不同的動作對應不同的旋轉起點與半徑,但「旋轉」這個基本動態結構是共通的。
這正是動力系統的特徵。一個簡單的線性動力系統 dx/dt = Ax,當矩陣 A 帶有虛部特徵值時,狀態就會在相空間裡旋轉。M1 看起來就像在執行這樣一台「振盪器」,用旋轉動力學生成肌肉所需的、帶有節律與時序結構的指令。重點在於:這個旋轉與「手往哪個方向動」沒有單純的對應——它是生成動作的「引擎內部運轉」,而非動作本身的「方向讀數」。表徵典範看到的方向調諧,在動力系統觀點裡,只是這台引擎運轉時投射出的影子。
自由度問題:伯恩斯坦留下的世紀難題
換一個同樣深刻、但更古老的問題。你的手臂從肩到指尖有數十個關節自由度,全身有超過六百條肌肉。當你要把手移到桌上某一點,達成這個目標的肌肉收縮組合有無限多種。大腦憑什麼從這片無窮的可能性裡,每次都俐落地挑出一組?
這就是俄國生理學家伯恩斯坦(Nikolai Bernstein)在 1930 年代提出的自由度問題(degrees-of-freedom problem)。他研究鐵匠揮錘的動作,發現一件反直覺的事:鐵匠手中錘頭的軌跡,比他各個關節角度的軌跡還要穩定。 也就是說,神經系統不是分別控制每個關節再讓它們碰巧湊出結果——關節之間是彼此補償的,某個關節多偏一點,另一個就少偏一點,共同把最終的錘頭軌跡穩住。
伯恩斯坦的洞見是:大腦不可能、也不需要逐一指揮每條肌肉。它必須凍結部分自由度、把肌肉組織成可重複使用的協調單元。這個單元,現代研究稱之為肌肉協同(muscle synergy)。
肌肉協同:把六百條肌肉壓縮成少數幾個「按鍵」
一個肌肉協同,是一組肌肉以固定的相對比例同時被激活的「套裝」。例如「往前伸手」可能對應某個協同,大腦只要決定這個協同「開多大」(一個係數),底下十幾條肌肉就會以預設比例一起動。
畢茲(Emilio Bizzi)與其同事在青蛙、貓的脊髓研究中發現了強力證據:刺激脊髓不同位置,會引發整組肌肉的協調收縮,把肢體推向空間中某個固定的平衡點。多個這樣的「力場(force field)」可以線性疊加,組合出豐富的動作。後續以非負矩陣分解(non-negative matrix factorization, NMF)分析人類肌電訊號(EMG)的研究也反覆發現:複雜的日常動作,往往能用少數幾個(常是 4 到 6 個)協同的加權組合重建出來。
這在計算上是一種降維(dimensionality reduction):大腦把高維的肌肉控制問題,壓縮成低維的「調幾個協同的係數」問題。這跟前面 M1 神經狀態落在低維流形上,其實是同一個故事的兩端——從神經到肌肉,控制的有效維度都遠低於元件的數目。神經系統用「結構」換取「可控性」。
小腦的微迴路:一台天生的監督式學習機
入門篇說小腦負責「誤差校正與平滑化」,建立內部模型。進階一層,我們要打開小腦看它的迴路,你會發現它的解剖結構幾乎是為監督式學習(supervised learning)量身打造的——這也是為什麼小腦被稱為神經科學裡「迴路與功能對應得最清楚」的腦區之一。
小腦皮質的核心輸出細胞是普金奇細胞(Purkinje cell)。它接收兩種截然不同的輸入:
- 平行纖維(parallel fibers):來自顆粒細胞,數量極其龐大——一個普金奇細胞接收多達二十萬條平行纖維的突觸。它們攜帶豐富的情境與感覺運動訊息,是「輸入特徵」。
- 攀緣纖維(climbing fibers):來自下橄欖核,每個普金奇細胞只接收一條。它放電時會引發普金奇細胞一個巨大的「複雜尖峰(complex spike)」。
馬爾(David Marr)與阿爾布斯(James Albus)在 1970 年前後各自提出、後由伊藤正男(Masao Ito)以生理實驗驗證的理論主張:攀緣纖維攜帶的是「誤差訊號(教師訊號)」。當動作出錯,下橄欖核發出攀緣纖維訊號,告訴普金奇細胞「剛才那組平行纖維輸入下,你的輸出錯了」,於是那些剛活躍過的平行纖維突觸被削弱——這就是長期抑制(long-term depression, LTD)。
把這三者對照機器學習,結構驚人地吻合:平行纖維是輸入層、普金奇細胞是輸出單元、攀緣纖維是監督式學習的教師訊號(error signal),LTD 則是依誤差調整權重的學習規則。小腦這台「天然的感知器」,正是入門篇所說「前饋內部模型」得以透過練習被校準的微觀基礎。當你適應一支更重的球拍,正是攀緣纖維在一次次揮拍誤差後,悄悄重寫了普金奇細胞的突觸權重。
值得一提的是爭論仍在:攀緣纖維除了傳統的「二元誤差」之外,近年研究(如 Medina、Lisberger 等人的工作)顯示它也可能攜帶有方向與幅度的、更接近連續值的訊息,這讓小腦學習規則的細節至今仍是活躍的研究前沿。
基底核的動作選擇:不只是放行與煞車
入門篇用「直接路徑放行、間接路徑煞車」來描述基底核。進階視角要把這個比喻精緻化,並引入第三條常被忽略的路徑。
把皮質想成同時提出許多「候選動作」的議會,每個候選動作都吵著要被執行。基底核的工作是競爭性的動作選擇(action selection):放行勝出的那一個,同時壓制其餘所有競爭者。三條路徑分工如下:
- 直接路徑(direct pathway):紋狀體中表達 D1 受體的神經元,經由「去抑制(disinhibition)」釋放被選中的動作。基底核的輸出核(內蒼白球/黑質網狀部)平時持續放電、像踩著煞車抑制視丘;直接路徑會「抑制這個抑制」,等於替特定動作鬆開煞車。
- 間接路徑(indirect pathway):表達 D2 受體的神經元,經蒼白球外部與視丘下核,加強對視丘的抑制,壓住競爭動作。
- 超直接路徑(hyperdirect pathway):皮質繞過紋狀體,直接經視丘下核(subthalamic nucleus)快速、廣泛地踩下「全域煞車」。一般認為它提供一個短暫的「先全部停住,再讓贏家浮現」的時間窗,是衝動控制與動作中止的關鍵。
多巴胺在此扮演調節「煞車鬆緊」與「學習」的雙重角色。它一方面調控直接/間接路徑的平衡(這解釋了帕金森病多巴胺不足時動作難以啟動),另一方面——回到入門篇提過的——它編碼獎賞預測誤差(reward prediction error),依此強化「在某情境下選某動作」的傾向。換句話說,基底核不只在「當下選動作」,更在「依結果學習以後要怎麼選」。這正是它與強化學習(reinforcement learning)對應得如此緊密的原因:紋狀體像是儲存「狀態—動作價值」的表,多巴胺像是更新這張表的學習訊號。
重點回顧
- 動力系統典範取代了單純的表徵論:M1 族群活動不只是「讀數表」,而是一台會自我演化的動態機器;準備期活動的意義是替後續神經動力學設定初始條件,動作展開時族群狀態呈現乾淨的旋轉軌跡。
- 自由度問題是運動控制的核心難題:肌肉與關節的可能組合無窮,大腦透過「肌肉協同」把高維控制壓縮成少數係數的低維問題,與神經活動落在低維流形是同一邏輯。
- 小腦微迴路是天然的監督式學習機:平行纖維為輸入、普金奇細胞為輸出、攀緣纖維傳遞誤差教師訊號、LTD 為學習規則(Marr–Albus–Ito 理論)。
- 基底核執行競爭性動作選擇:直接(放行)、間接(壓制競爭者)、超直接(全域急煞)三路徑協作,多巴胺同時調節即時平衡與長期的獎賞學習。
- 「降維」是貫穿全系統的主題:從神經狀態空間到肌肉協同,運動系統反覆把高維問題壓縮到低維、可控的子空間。
深入探討(研究所視角)
循環神經網路(RNN)作為運動皮質的計算模型。 動力系統觀點最有力的延伸,是用訓練過的循環神經網路(recurrent neural network)來模擬運動皮質。蘇斯西洛(David Sussillo)、丘奇蘭與申諾伊團隊訓練 RNN 生成真實的肌電(EMG)訊號,發現網路內部自發演化出與真實 M1 高度相似的旋轉動力學——即使從未被要求要旋轉。這是強力的「殊途同歸」證據:當任何動態系統被優化來生成帶時序結構的肌肉指令時,旋轉式的低維動力學是一種自然湧現的解。這條路線把神經科學與深度學習接成雙向的對話:RNN 成為可解剖、可擾動的「模型大腦」,而真實大腦的數據又回頭約束我們對 RNN 內部機制的理解(這催生了整個 NeuroAI 領域)。
新一代腦機介面:解碼動力學而非方向。 入門篇提到族群向量解碼。當代高效能腦機介面(如 BrainGate 計畫,Hochberg、Henderson、Shenoy 等人)已不再只解「瞬時方向」,而是把神經活動視為一個潛在動力系統(latent dynamical system)來建模——先用降維與狀態空間模型(如高斯過程因子分析、LFADS 這類深度學習方法)找出低維潛在軌跡,再從中解碼意圖。Willett 等人 2021 年讓癱瘓者用「想像手寫」隔空打字、2023 年的語音腦機介面達到每分鐘上看數十詞的速度,背後都是這種「解碼潛在動力學」思路的勝利。基礎科學對「M1 是動力系統」的重新理解,直接轉化成了臨床效能。
最優控制、神經幾何與未竟的爭論。 把這些線索收攏,當代運動神經科學正圍繞一個野心勃勃的綜合:運動系統是一個分層的最優控制器,皮質設定動力學、基底核做選擇與強化學習、小腦做監督式的前饋校正,而所有層級的計算都發生在遠低於元件數目的低維神經流形(neural manifold)上。但爭論遠未止息——動力系統觀點是否真的「取代」了表徵觀點,還是兩者只是同一現象的不同投影?協同究竟是神經系統主動施加的控制策略,還是肌肉骨骼力學與任務約束被動造成的統計假象?這些問題沒有定論,正是這個領域迷人之處。
跨領域連結。 從優生物的角度,肌肉協同的物理基礎根植於肌肉骨骼的生物力學與脊髓迴路的解剖約束,神經控制必須在身體允許的動作空間內運作(具身認知,embodied cognition)。從優心理的角度,技能從「費力的意識控制」自動化為「流暢的動力學執行」,正對應動作從前額葉主導轉移到皮質下與小腦迴路的神經變化,這是專家表現與運動學習研究的核心。而與 AI 的對話是雙向的:強化學習的時序差分演算法受多巴胺研究啟發、機器人控制借鏡小腦的前饋模型與「運動牙牙學語(motor babbling)」式的探索,反過來,深度學習又給了神經科學家前所未有的工具,去理解大腦這台在演化與學習中淬鍊出來的、優雅得驚人的控制器。