
一群神經元的「形狀」,藏著大腦的計算嗎?
從表徵轉向動態系統:用狀態空間、吸引子、貝氏推論與預測編碼,理解大腦如何在時間中流動地計算。
一群神經元的「形狀」,藏著大腦的計算嗎?
你已經知道,計算神經科學把大腦看成資訊處理系統,也知道單一神經元會對特定特徵「調諧」、群體會用分散的活動模式編碼資訊。但這裡有一個更尖銳的問題:當你記錄到幾百顆神經元、每一顆都在以複雜的方式變化,你要怎麼說「這群神經元正在計算」?
換個方式問——大腦做決策、產生動作、維持一段工作記憶,這些過程在時間中展開。它們不是一張靜止的特徵地圖,而是一段持續演化的歷程。如果說入門篇談的是「大腦把世界寫成什麼格式」,那麼進階篇要談的是「這些格式如何隨時間流動、被推擠、被吸引、被穩定下來」。這正是當代計算神經科學最活躍的轉向之一:從把神經活動看成「表徵」(representation),轉向把它看成一個動態系統(dynamical system)的軌跡。本文要帶你進入這個視角,並看它如何與貝氏推論、預測編碼,以及人工智慧裡的遞迴網路深深咬合。
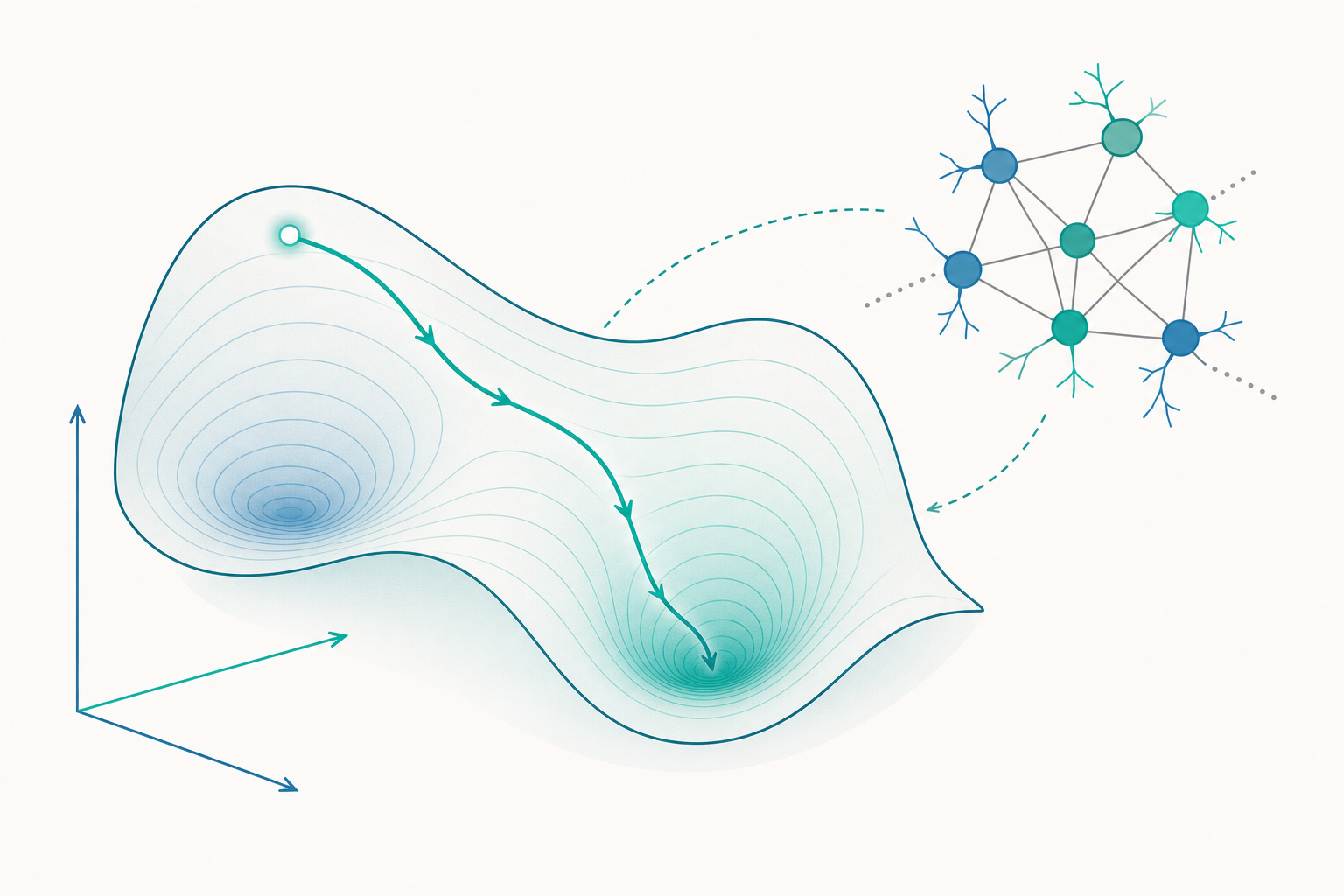
把神經活動放進「狀態空間」
先建立一個關鍵的幾何直覺。假設你同時記錄了 N 顆神經元的瞬間發放率,那麼在任何一個時刻,整群神經元的狀態就可以寫成一個 N 維向量——每一個維度是一顆神經元的活動。隨著時間推進,這個點在 N 維空間中移動,畫出一條軌跡(trajectory)。這個 N 維空間就叫神經狀態空間(neural state space)。
這個轉換看似只是換個座標,意義卻很深。它讓我們不再追問「第 37 號神經元代表什麼」,而是追問「整群活動的軌跡長什麼形狀、往哪裡走、被什麼拉著走」。計算,於是變成軌跡在狀態空間中的幾何與動態。
一個反覆被觀察到的現象是:雖然你記錄了幾百個維度,神經群體的活動其實常常被限制在一個低得多的子空間裡——它躺在一個低維流形(manifold)上。也就是說,神經元彼此不是各自獨立亂跳,而是高度協調,真正「自由」的維度遠少於神經元數目。這個低維結構不是冗餘的浪費,反而可能正是計算的所在:大腦把高維的神經硬體,組織成少數幾個有意義的「集體變數」(collective variables)來運算。
對學過線性代數的同學,這裡的工具一點都不陌生——主成分分析(PCA)、因子分析這類降維方法,正是用來把高維神經紀錄投影到少數幾個主軸,好讓我們「看見」那條軌跡的形狀。但要小心:降維後看到的漂亮結構,是真實的計算原理,還是只是分析方法強加的視覺假象?這個分寸,後面會再回來談。
吸引子:用「地形」理解穩定與選擇
有了狀態空間,我們需要一個語言來描述軌跡為什麼這樣走。最有力的概念是吸引子(attractor)。
想像狀態空間像一片有高低起伏的地形,而神經活動的當前狀態,像一顆在這片地形上滾動的球。地形的低谷會把附近的球吸進去,這些低谷就是吸引子。一旦球落入某個谷底,就算被輕輕推一下(受到雜訊干擾),它也會自動滾回谷底——這就是穩定性的來源。吸引子的「地形」並非真實存在的物理表面,而是由神經元之間的連結(突觸權重)所隱含決定的動態。
這個比喻能解釋好幾種核心認知功能:
- 記憶:入門篇提過的霍普菲爾德網路,正是一種點吸引子(point attractor)系統。每段記憶是一個谷底;給網路一個殘缺線索,狀態就會滾向最接近的谷底,把完整記憶「補全」出來。聯想記憶,本質上是落入吸引子的過程。
- 工作記憶:當你心裡默記一個電話號碼、一個角度、一個位置,外在刺激早已消失,但相關的神經活動卻能持續好幾秒。一種主流解釋是,大腦維持著一個連續吸引子(continuous attractor)——不是孤立的谷底,而是一條相連的「山谷」,狀態可以停在這條谷線上的任何一點,藉此穩定地保存一個連續變數(例如頭部朝向的角度)。
- 決策:當你要在兩個選項間抉擇,可以把它想成一個有兩個谷底的地形。證據像是一股股推力,緩緩把球推向其中一邊;一旦越過分水嶺、落入某個谷底,決策就「定了」,而且不容易反悔。這對應到行為學上熟悉的「證據累積到閾值」模型。
吸引子之所以重要,是因為它把抽象的「計算」翻譯成可以分析、可以用神經連結實現的動態。穩定的記憶、可靠的決策、持續的注意,都可以理解為大腦在狀態空間裡,巧妙地塑造出對的吸引子地形。
大腦是一台「推論機器」嗎?
換一個層次,我們從「動態怎麼跑」上升到「大腦為什麼要這樣跑」。這就回到入門篇點過、但值得深挖的規範性觀點:貝氏大腦假說(Bayesian brain hypothesis)。
核心想法是:感官給大腦的證據永遠是不完整、有雜訊、且有歧義的。你的視網膜收到的是二維的光影,外面卻是三維的世界;同一片影像可能對應無數種外在原因。大腦的根本任務,因此不是「讀取」世界,而是「推論」世界——在不確定中,估計最可能的外在狀態。
用貝氏定理的語言:大腦結合先驗(prior,過去經驗告訴你世界通常長怎樣)與似然(likelihood,當下感官證據的支持程度),算出後驗(posterior,對世界的最佳估計)。一個漂亮的可驗證預測是:當感官證據越不可靠,大腦就應該越倚賴先驗。許多錯覺正是這樣產生的——在資訊不足時,大腦用「世界通常的樣子」去填補空白,結果填出了與物理現實不符、卻符合統計常理的知覺。
從貝氏推論再往前一步,就是近年極具影響力的預測編碼(predictive coding)框架。它的核心主張是:大腦不是被動等著感官資訊湧入,而是主動地、不斷地對下一刻的輸入做出預測。高層腦區把自己的預測往下傳給低層,低層拿真實輸入和預測相減,只把「沒被預測到的部分」——也就是預測誤差(prediction error)——往上送。整個系統的目標,是讓預測誤差最小化。
這個架構優雅地把好幾件事接了起來。第一,它解釋了為什麼大腦這麼省能量:如果上層已經準確預測,下層幾乎不必傳訊號,安靜就是成功。第二,它把「知覺」與「學習」統一在同一個原則下:短期內,調整你對世界的估計來消除誤差,那是知覺;長期下,調整你的內部模型(突觸權重)來讓未來預測更準,那是學習。第三,它甚至延伸到行動——你也可以透過「動起來、改變感官輸入」來消除預測誤差,這就把感知和運動納進了同一個迴圈。當然,預測編碼究竟在多大程度上是大腦真實的運作方式,仍有爭論,但它無疑是當前最具整合野心的計算框架之一。
看一個例子
讓我們用一個能被實驗操弄的場景,把狀態空間、吸引子、推論這三件事串起來:知覺決策(perceptual decision-making)中的隨機點運動任務。
想像螢幕上有一群隨機飄動的點,其中一定比例的點往同一方向(比如往右)一致移動,其餘的點則是純粹的雜訊。受試者(人或獼猴)要判斷「整體往左還是往右」。實驗者可以調整「一致移動的比例」來控制難度——比例越低,證據越微弱、越接近純雜訊,這恰好對應了貝氏觀點裡「感官證據不可靠」的情境。
在這個任務裡,研究者記錄了頂葉與前額葉的神經活動,看到了清晰的「證據累積」訊號:某些神經元的發放率,隨著支持某一方向的證據累積而緩緩上升,一旦衝到某個水準,動物就做出選擇並行動。這正是「球被推向某個谷底」的動態圖像——決策對應狀態軌跡越過分水嶺、落入吸引子。
把這三層連起來看就很完整:從推論的目標(在雜訊中估計運動方向,且證據越弱越該謹慎)出發,落實為動態的機制(活動軌跡在狀態空間中被證據持續推動),最後穩定為吸引子的結果(落入「往右」的谷底,做出決策)。而當研究者訓練一個遞迴神經網路去做同樣的任務,再去剖析它內部的動態時,往往也會發現類似的低維軌跡與近似吸引子的結構——再一次,人工網路成了一面照亮大腦動態的鏡子。這個取徑,常被稱為「逆向工程一個被訓練好的網路」。
動手試試
你不需要實驗室也能對這些概念建立手感,這裡有兩個可以在紙上或腦中進行的思想練習。
第一個,關於連續吸引子。請你閉上眼睛,在心裡想像一個時鐘的指針指向三點鐘方向,並試著「維持」這個方向幾秒鐘。在你維持的這幾秒裡,沒有任何外在刺激,但某個內部狀態被穩定地保持著——這就是連續吸引子要做的事:把一個連續的角度,鎖在一條「山谷線」上的某一點。接著想像有人輕喊一聲「往右轉一點」,你的內部指針平滑地滑動到四點鐘——這對應狀態沿著谷線移動,而不是跳到另一個孤立的谷底。連續吸引子之所以叫「連續」,正是因為它允許這種無縫的滑動。
第二個,關於先驗如何主宰知覺。找一張著名的「空心面具錯覺」(hollow-mask illusion)說明,或回想任何一次你把凹陷的臉看成凸出的臉的經驗。物理上,那是一張凹進去的臉;但你的視覺系統幾乎無法把它看成凹的,總是「強迫」看成正常凸出的臉。為什麼?因為「臉是凸的」這個先驗,在你的一生中被無數次驗證,強到足以推翻當下明明指向「凹」的感官證據。這就是貝氏大腦的活教材:當先驗夠強、證據夠弱,後驗會倒向先驗,而你「看見」的,永遠是後驗。
雜訊:是敵人,還是計算的一部分?
最後一個進階轉折,足以顛覆許多人對大腦的直覺。神經活動充滿了變異性(variability):同一個刺激重複呈現,神經元每次的反應都不完全一樣;自發的、看似隨機的放電,無處不在。傳統觀點把這些雜訊當成需要被平均掉、被克服的麻煩。
但計算的觀點提供了另一種可能:雜訊也許是計算的一部分,甚至是被善用的資源。
如果大腦真的在做貝氏推論,那它不只需要知道「最可能的答案」,還需要表徵「答案的不確定性」——也就是整個機率分布。一個誘人的假說是,神經活動的變異性,可能正是大腦在用「採樣」(sampling)的方式表徵機率分布:每一個瞬間的活動模式,是從後驗分布中抽出的一個樣本;看似隨機的波動,其實是在「探索」各種可能的世界狀態。在這個觀點下,變異性不是雜訊污染,而是不確定性的載體。
雜訊也可能在學習與探索中扮演積極角色。在強化學習裡,行為若毫無隨機性,個體就會困在已知的選項裡、無法發現更好的策略;一點點隨機探索,反而是找到更優解的前提。大腦中的隨機性,或許也提供了這種「跳出局部最優」的能力。當然,這些都還是活躍的假說而非定論——但它示範了計算視角的威力:同一個現象(變異性),在「描述」框架下是要被消除的瑕疵,在「計算」框架下卻可能是被精心利用的功能。看待事物的層次一變,問題的意義就全變了。
重點回顧
- 狀態空間與低維流形:把整群神經元的瞬間活動看成高維空間中的一個點,計算就成了這個點隨時間畫出的軌跡;而軌跡往往被約束在少數幾個維度構成的流形上,暗示大腦用「集體變數」運算。
- 吸引子動態:用「地形上滾動的球」這個比喻,點吸引子解釋聯想記憶、連續吸引子解釋工作記憶、雙穩態地形解釋決策——抽象的計算被翻譯成可由突觸連結實現的動態。
- 貝氏大腦與預測編碼:感官證據總是不完整且有雜訊,大腦的根本任務是「推論」而非「讀取」世界;預測編碼進一步主張大腦主動預測、只上傳預測誤差,把知覺、學習、行動統一在最小化誤差的原則下。
- 雜訊可能是功能而非瑕疵:神經變異性也許承載著不確定性(採樣假說),或支持探索(強化學習),提醒我們同一現象在「描述」與「計算」兩種框架下意義截然不同。
- 動態系統視角貫穿全篇:從表徵轉向軌跡、從靜態地圖轉向流動歷程,是當代計算神經科學與遞迴神經網路對話最密集的前沿。
深入探討(研究所視角)
對想更進一步的同學,這個動態與推論的視角下,有幾條真正前沿的線索與必要的警覺。
第一,動態系統工具的數學深度。 把神經群體當成動態系統來分析,需要的不只是降維。近年發展出一系列方法:高斯過程因子分析(GPFA)能在單次試驗層級萃取平滑的低維軌跡;LFADS(latent factor analysis via dynamical systems)用遞迴變分自編碼器去推斷「生成」觀測到的脈衝序列的潛在動態;而要嚴謹刻畫吸引子,則牽涉到固定點(fixed point)分析、線性化後的特徵值、流形的曲率等動態系統理論的核心工具。把這套數學練扎實,是進入這個領域的門檻。
第二,相關不等於因果——「擾動」才是試金石。 觀察到漂亮的低維軌跡或吸引子結構,只是相關證據;它不能證明大腦「真的用」這個結構在計算。真正的檢驗來自因果操弄:用光遺傳學(optogenetics)精準地把神經活動「推離」軌跡,看系統是否會如吸引子理論預測的那樣自動滾回、或滾向特定方向。降維分析給出假說,擾動實驗才能驗證假說。沒有擾動,再美的幾何都可能是過度詮釋。
第三,貝氏與預測編碼的可否證性難題。 貝氏大腦假說極具解釋力,但也正因為太有彈性而難以否證——幾乎任何行為,事後都能找到一組先驗與似然來「解釋」它。嚴謹的研究因此必須事先獨立地測量先驗、預測後驗、再用實驗檢驗,而不是反過來湊。預測編碼同樣面臨「神經實作證據」的考驗:哪些神經元真的在傳預測、哪些在傳誤差?不同腦層之間的訊號流向,是否符合理論要求的方向?這些都還在被積極檢驗中。
第四,跨維度的整合視野。 把這套動態與推論的框架放回 Educational Omics 的脈絡,它與優生物(突觸與離子通道如何實現吸引子所需的遞迴連結與持續活動)、優心理(決策、工作記憶、知覺錯覺的行為層次)以及 AI(遞迴神經網路、變分推論、強化學習中的探索)天然相連。對學習科學尤其值得玩味:如果知覺與學習都是「最小化預測誤差」的過程,那麼一個好的教學設計,或許正是在學習者心中製造「恰到好處的預測誤差」——既不是早已預測到的無聊,也不是完全無法預測的混亂,而是落在能驅動內部模型更新的甜蜜點上。理解大腦如何在動態中推論世界,最終可能回過頭來,照亮我們如何設計能驅動有效學習的歷程。