
為什麼一隻烏賊能教我們理解智慧?
計算神經科學把大腦當成資訊處理系統,用數學模型回答「大腦在算什麼、怎麼算、為什麼這樣算」,並與人工智慧雙向對話。
為什麼一隻烏賊能教我們理解智慧?
一九五二年,霍奇金(Alan Hodgkin)與赫胥黎(Andrew Huxley)把細小的電極插進一條烏賊(squid)異常粗大的神經軸突,量測膜電位隨時間的變化。他們做的不只是記錄——他們寫下了一組微分方程式,讓電壓、鈉離子、鉀離子之間的關係變成可以「計算」的數學。把方程式解出來,曲線竟然與真實神經元發放動作電位(action potential)的波形幾乎吻合。
這是一個關鍵的時刻:大腦的某個運作,第一次被一個方程式「預測」出來,而不只是被觀察、被描述。從那一刻起,神經科學多了一個問法。除了問「大腦長什麼樣子、哪裡亮起來」,我們開始問:「大腦在『算』什麼?它用什麼樣的計算規則,把感官輸入變成知覺、決策與行動?」
這就是計算神經科學(Computational Neuroscience)的核心關懷。它假設大腦是一台處理資訊的機器——不是比喻,而是字面意義上的資訊處理系統——並試圖用數學模型與電腦模擬,去逼近這台機器的運算原理。本文要帶你看的,正是「用模型理解大腦」這條路徑:它怎麼開始、發展出哪些層次的模型,又如何與今天的人工智慧(AI)彼此餵養。
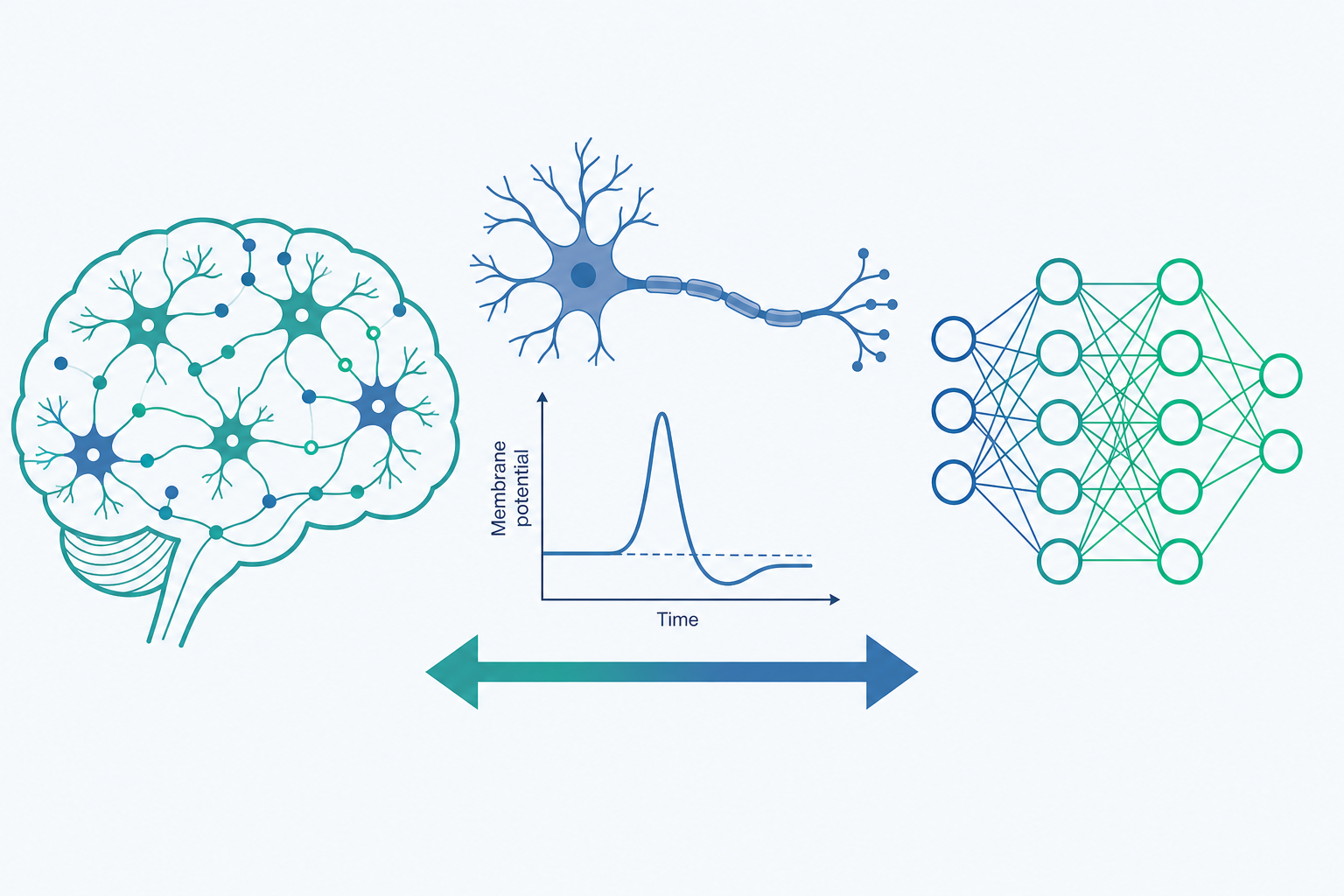
從「描述大腦」到「計算大腦」
傳統神經科學擅長描述。我們可以用組織切片畫出神經元的形態,用功能性磁振造影(fMRI)看哪塊腦區在做數學題時血氧增加,用腦電圖(EEG)記錄睡眠時的腦波節律。這些都極有價值,卻有一個共同的限制:它們告訴你「發生了什麼」,卻不一定告訴你「為什麼是這樣,而不是別的樣子」。
計算神經科學想補上的,是「為什麼」與「如何」。它的基本信念可以用一句話概括:大腦的結構是為了執行某種計算而存在的。如果我們能寫出那個計算的數學形式,就能用模型生成預測,再拿去和真實的神經資料比對。模型對了,我們就更接近理解;模型錯了,差異本身也告訴我們漏掉了什麼。
這裡有一個很有用的思考框架,來自視覺科學家馬爾(David Marr)。他在一九八二年的著作《Vision》中提出,理解任何資訊處理系統都應該分三個層次:
- 計算層(computational level):這個系統要解決什麼問題?目標是什麼?
- 演算法層(algorithmic level):它用什麼表徵(representation)與步驟來解這個問題?
- 實作層(implementational level):這些步驟如何由實際的硬體——對大腦而言就是神經元與突觸——來實現?
馬爾的洞見是:這三層相對獨立。你可以在不知道每顆電晶體怎麼運作的情況下,理解一台計算機在「做加法」;同樣地,我們可以先問「海馬迴(hippocampus)要解決什麼導航問題」,再問它用什麼演算法,最後才追究神經元層級的細節。計算神經科學的工作,常常就是在這三層之間來回穿梭、互相約束。
模型有不同的「解析度」
「用模型理解大腦」聽起來抽象,實際上模型有很多種,差別在於它描述到多細的層次。我們可以大致排出一個由細到粗的光譜。
生物物理模型(biophysical models)最接近真實的生理機制。前面提到的霍奇金—赫胥黎模型就是代表:它用離子通道的開關機率、膜電容、各種離子電流,精確描述單一神經元如何產生動作電位。這類模型參數多、計算量大,但能還原很細膩的電生理現象,也是後來各種簡化模型的源頭。
簡化的點神經元模型(point-neuron models)犧牲一些細節,換取可分析性與運算效率。最經典的是「整合發放模型」(integrate-and-fire model):把神經元想像成一個會累積電荷的容器,輸入電流讓膜電位上升,一旦超過閾值就「發放」一個脈衝,然後重置。它丟掉了動作電位的精細波形,卻保留了「累積—觸發—重置」這個核心邏輯,因此被廣泛用來搭建成千上萬個神經元的網路模擬。
網路與群體模型(network / population models)關心的不再是單顆神經元,而是一群神經元如何互相連結、產生集體行為。經典的例子是霍普菲爾德網路(Hopfield network),約翰·霍普菲爾德(John Hopfield)在一九八二年用它說明:一群彼此連結的神經元,可以把記憶儲存成網路的「穩定狀態」,當輸入一個殘缺的線索,網路會自動「滾」到最接近的記憶狀態——這正是聯想記憶(associative memory)的數學原型。值得一提的是,霍普菲爾德與辛頓(Geoffrey Hinton)因為這條把物理、神經與機器學習接起來的脈絡,獲得了二○二四年的諾貝爾物理學獎。
規範性/理性模型(normative models)則站在最高的計算層問問題:假設大腦在某個任務上「做得最好」,那最佳解會長什麼樣子?例如,把知覺看成貝氏推論(Bayesian inference)——大腦結合「先驗知識」與「當下的不確定感官證據」,推估外在世界最可能的狀態。這類模型不直接描述神經元,而是描述大腦「應該」如何計算才合理,再回頭檢查神經活動是否符合這個理性標準。
沒有哪一種解析度「最好」。要不要保留離子通道、要不要模擬單顆神經元,取決於你想回答的問題。這也是計算神經科學的一門手藝:選對抽象的層次。
大腦怎麼「編碼」資訊?
如果大腦在計算,那它一定得先把世界「寫」成某種內部的格式。這就是神經編碼(neural coding)的問題:一個神經元的發放,到底代表什麼?
最早的線索來自單細胞記錄。休伯爾(David Hubel)與威澤爾(Torsten Wiesel)在一九五○至六○年代記錄貓的初級視覺皮質(V1),發現某些神經元只有在視野中出現「特定方向的線條」時才強烈發放——有的偏好垂直線,有的偏好斜線。換句話說,單一神經元像是一個「特徵偵測器」,對某種刺激「調諧」(tuning)。他們因此獲得一九八一年諾貝爾生理醫學獎,這項發現也奠定了「皮質透過階層式特徵抽取來理解視覺」的觀念——這個觀念,數十年後幾乎原封不動地出現在深度卷積神經網路的設計裡。
但「一個神經元代表一個特徵」只是故事的一部分。後來的研究強調群體編碼(population coding):訊息往往不在單顆神經元,而分散在一群神經元的活動模式(pattern)裡。例如運動皮質中,單一神經元對手臂運動方向只有粗略偏好,但把整群神經元的偏好向量加總起來,就能精準預測手臂要往哪裡動——這就是著名的「群體向量」(population vector)概念。群體編碼的好處是抗噪、容錯,少數神經元失常不至於讓整個表徵崩潰。
還有一個長年爭論:訊息是藏在發放的頻率(rate coding,一段時間內發放幾次),還是藏在發放的精確時間(temporal coding,脈衝出現在哪個毫秒)?兩者在不同腦區、不同任務中可能都有角色。聽覺系統對時間極度敏感(我們能用兩耳到達聲音的時間差定位聲源),這暗示時間編碼在某些場景至關重要。計算神經科學的工作之一,就是用模型去釐清:在什麼條件下,哪一種編碼方式對大腦最有效率。
學習,是突觸在更新權重
理解了大腦如何「編碼當下」,下一個問題是:它如何「改變自己」?也就是學習。
計算的觀點下,學習往往等同於調整連結強度——突觸的權重。這個想法的源頭是心理學家赫布(Donald Hebb)在一九四九年提出的原則,常被濃縮成一句話:「一起發放的神經元,會連在一起」(neurons that fire together, wire together)。當突觸前與突觸後神經元反覆同步活動,它們之間的連結就會增強。這條赫布學習法則(Hebbian learning),後來在生理上找到了對應:長期增益效應(long-term potentiation, LTP)與長期抑制效應(long-term depression, LTD),以及更精細的「脈衝時序依賴可塑性」(spike-timing-dependent plasticity, STDP)——突觸增強或減弱,竟然取決於前後神經元發放的先後順序與時間差,差幾毫秒結果就可能相反。
赫布法則是「局部」的——每個突觸只需要看自己兩端的活動就能更新。但要學會複雜的任務,光靠局部規則似乎不夠,於是有了「監督式學習」的觀點:拿系統的輸出和正確答案比較,算出誤差,再把誤差「往回傳」去調整每一層的權重。這就是反向傳播(backpropagation)。它在工程上極為成功,是今天深度學習的引擎;但它在大腦中是否真實存在,一直備受質疑——因為它需要一條精確的「反向通路」傳遞誤差訊號,而真實神經迴路是否具備這種機制,至今仍是熱門的研究問題。這個張力本身,正是計算神經科學與 AI 對話最精彩的地方:工程上好用的演算法,不一定就是大腦用的演算法。
大腦與 AI:互相照亮的兩面鏡子
到這裡,計算神經科學與人工智慧的交纏已經呼之欲出。它們的關係,與其說是「誰啟發誰」,不如說是一段長達數十年、雙向流動的對話。
從大腦流向 AI 的一面:人工神經網路(artificial neural network)的最初靈感,正來自神經元。麥卡洛克(Warren McCulloch)與皮茨(Walter Pitts)在一九四三年提出的形式神經元,是把神經元簡化成「加權求和再過閾值」的邏輯單元。前面提到的休伯爾—威澤爾發現,啟發了福島邦彥(Kunihiko Fukushima)的「神經認知機」(Neocognitron),而後者又是現代卷積神經網路(CNN)的直接前身。連「注意力」(attention)這個今天大型語言模型的核心機制,其名稱與直覺也借自認知與神經科學對選擇性注意的研究。
從 AI 流回大腦的一面:當深度網路強大到能在影像辨識上接近人類,神經科學家做了一件有趣的事——直接拿訓練好的 CNN 各層的活動,去比對獼猴視覺皮質各區的神經反應。結果發現,網路低層的活動類似 V1,高層的活動類似下顳葉皮質(IT cortex),對應得出奇地好。這讓深度網路成為一種新的工具:把它當成「大腦的可操作模型」,在裡面做各種真實實驗難以進行的拆解與假設檢驗。這個方向近年常被歸入更廣義的 NeuroAI。
但必須誠實地說明界線:人工神經網路與真實大腦的差異仍然巨大。生物神經元是發放離散脈衝、消耗極少能量、在連續時間中運作的;它的學習可能根本不靠反向傳播;它還與身體、荷爾蒙、睡眠、情緒深深耦合。把 CNN 當成視覺皮質的模型很有啟發性,但若忘了它只是某個層次的近似,就會落入「大腦就是個深度網路」的迷思。模型是用來思考的工具,不是大腦的替身。
看一個例子
讓我們用一個具體的故事,把前面的概念串起來——海馬迴系統裡的「位置細胞」(place cells)與「網格細胞」(grid cells)。
一九七一年,奧基夫(John O'Keefe)在大鼠的海馬迴記錄到一類神經元:當動物走到環境中某個特定地點時,這顆細胞就劇烈發放,走到別處就安靜。彷彿大腦裡有一張「地圖」,每顆位置細胞負責標記地圖上的一個點。這是純粹的「描述性」發現——我們看到了現象。
但描述只是起點。計算的問題接著浮現:動物在黑暗中、沒有外部地標時,怎麼知道自己走到哪了?合理的猜想是,大腦能整合自身的移動(走了多遠、轉了多少角度)來持續更新位置估計——這在工程上叫「路徑積分」(path integration)。
二○○五年,莫澤夫婦(May-Britt Moser 與 Edvard Moser)在鄰近的內嗅皮質(entorhinal cortex)發現了網格細胞:它的發放不是對應單一地點,而是對應一個鋪滿整個空間的、規律的六邊形格點。多個不同尺度、不同相位的網格細胞疊加起來,理論上可以唯一地編碼任意位置——這簡直就是一套天生的「空間座標系統」。奧基夫與莫澤夫婦因此共享了二○一四年諾貝爾生理醫學獎。
而這裡出現了計算神經科學最迷人的一幕:當研究者訓練一個人工遞迴神經網路(recurrent neural network),單純要求它根據速度訊號去做路徑積分、估計自己的位置時,網路內部「自發地」長出了類似網格細胞的六邊形發放模式(二○一八年,DeepMind 與合作團隊發表於《Nature》的研究)。沒有人告訴網路要長成六邊形——它只是為了把路徑積分這個計算任務做好,最有效率的內部表徵恰好就是網格。
這個例子完整走過了我們談的每一層:從描述(看到位置細胞)→ 提出計算問題(如何路徑積分)→ 發現對應的神經編碼(網格細胞)→ 用規範性模型(人工網路只被要求把任務做好)回頭驗證「為什麼是六邊形」。它也漂亮地示範了大腦與 AI 的雙向對話:神經發現啟發了模型,而模型又回過頭來提供了神經發現背後「為什麼」的一種解釋。
重點回顧
- 計算神經科學把大腦看成資訊處理系統,目標不只是描述「發生了什麼」,而是用數學模型回答「大腦在算什麼、怎麼算、為什麼這樣算」。
- 馬爾的三層次框架(計算層、演算法層、實作層)提醒我們:理解大腦要在「解決什麼問題」與「神經元如何實現」之間來回穿梭,選對抽象層次是關鍵手藝。
- 模型有不同解析度,從貼近生理的霍奇金—赫胥黎模型,到簡化的整合發放模型,到群體網路模型,再到問「最佳解長什麼樣」的規範性模型,各自回答不同尺度的問題。
- 編碼與學習是兩大主軸:大腦用單細胞調諧與群體模式編碼資訊,並透過突觸權重的可塑性(赫布法則、LTP/LTD、STDP)來學習。
- 大腦與 AI 是雙向流動的兩面鏡子:神經科學啟發了人工神經網路,而訓練好的網路又成為理解大腦的新工具——但兩者差異仍大,模型是思考的工具,而非大腦的替身。
深入探討(研究所視角)
對有志於進一步鑽研的同學,計算神經科學目前有幾條值得關注的前沿與爭論。
第一,反向傳播在大腦中的「生物合理性」(biological plausibility)。 深度學習靠反向傳播取得壓倒性成功,但它要求權重對稱的反向通路、全域同步的誤差傳遞,這些在解剖學上難以對應。近年一系列工作試圖找出「生物可行的近似」:例如回饋對齊(feedback alignment)顯示,就算反向權重是隨機的、與前向權重不對稱,網路仍能學習;又如平衡傳播(equilibrium propagation)、預測編碼(predictive coding)框架,試圖用局部規則逼近反向傳播的效果。「大腦是否在做某種形式的近似反向傳播」,是 NeuroAI 領域最核心的開放問題之一。
第二,從速率到脈衝、從靜態到動態。 主流深度網路用連續的發放速率與離散的時間步,而真實神經系統用稀疏的脈衝在連續時間中運作。脈衝神經網路(spiking neural networks, SNN)與神經形態運算(neuromorphic computing)試圖還原這層真實性,不只是為了生物逼真,更因為脈衝式、事件驅動的計算可能帶來極高的能源效率——這對被能耗問題困擾的當代 AI 是重要啟示。同時,研究焦點也從「網路學到什麼表徵」轉向「神經群體的動態系統」(dynamical systems)觀點:把運動皮質、前額葉的活動看成高維狀態空間中的軌跡,用吸引子(attractor)、流形(manifold)等語言來理解決策與運動的生成。
第三,表徵相似性與「對齊」的方法學爭論。 拿人工網路比對大腦的研究愈來愈多,但「相似」要怎麼嚴謹地量化?表徵相似性分析(representational similarity analysis, RSA)、中心核對齊(centered kernel alignment, CKA)等指標各有盲點,高相似度也不等於相同的計算機制。如何避免「過度詮釋」一個剛好擬合得好的模型,是這個領域必須面對的方法學自律。
最後,跨維度的整合視野。 把計算神經科學放回 Educational Omics 的脈絡,它與優生物(神經元的離子機制、突觸可塑性的分子基礎)、優心理(知覺、記憶、決策的行為層次)以及 AI(人工神經網路、強化學習)天然相連。對學習科學而言,這條路尤其誘人:如果學習在神經層次就是突觸權重的更新,那麼「什麼樣的教學情境最能驅動有效的權重更新」這個老問題,或許有一天能在計算的層次被重新提問。理解大腦如何計算,最終也可能回過頭來,幫助我們理解人如何學習。