
當一份試驗說「沒有比較差」,它到底在說什麼?
從試驗設計、ITT、Hazard Ratio 到統合分析的異質性,拆解臨床證據是如何被「設計」與「合成」出來的進階方法學。
當一份試驗說「沒有比較差」,它到底在說什麼?
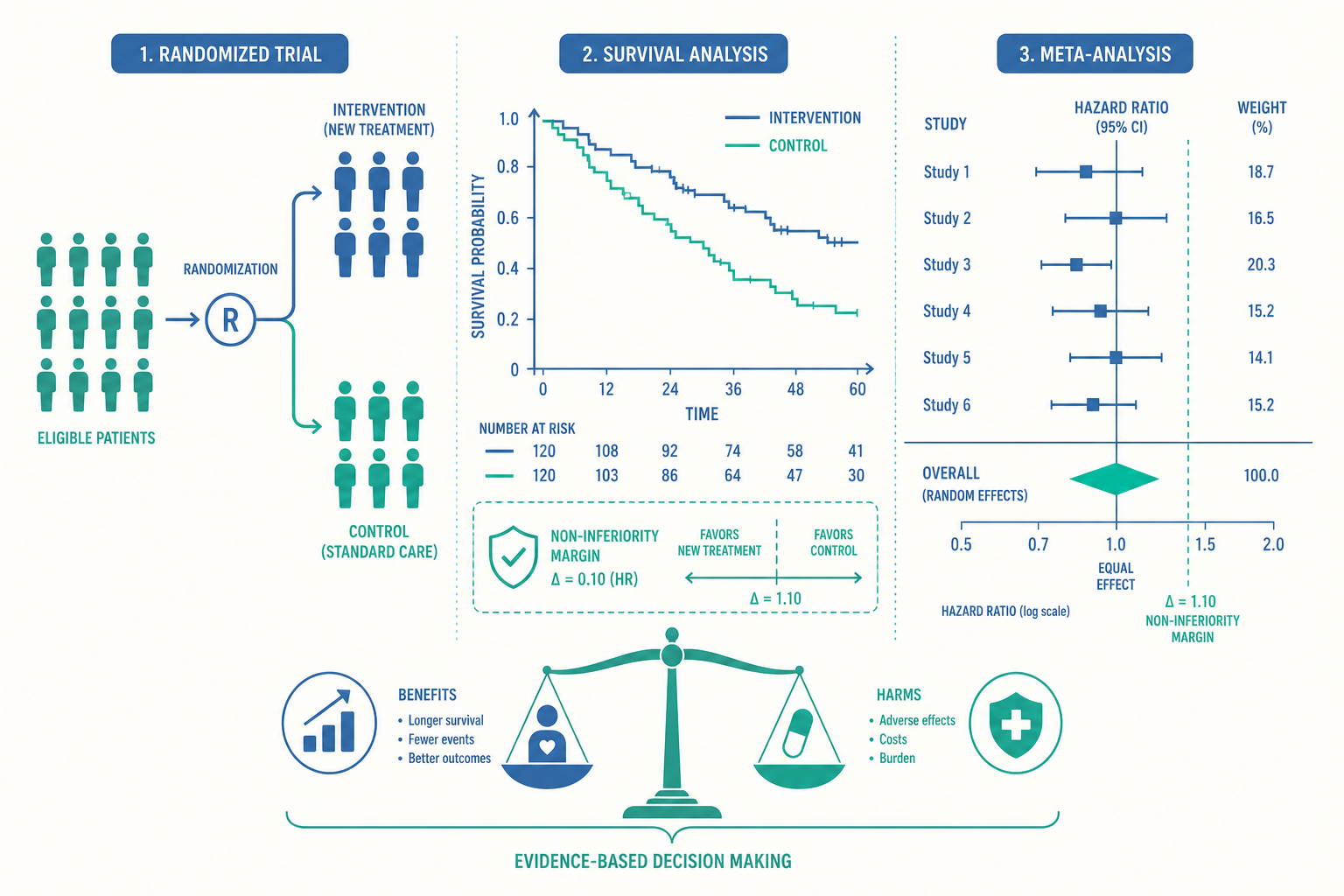
兩種降血壓藥的頭對頭試驗登上頂尖期刊,結論寫著:新藥「不劣於(non-inferior)」舊藥。新聞標題卻變成「新藥效果與老藥相當」。一位住院醫師問:「既然效果一樣,那為什麼要換更貴的新藥?」這個問題比它看起來深刻得多——因為「不劣性試驗」從設計之初,就不是為了證明兩者相等,而是在容忍一個事先講好的「可接受劣化幅度」之內,換取其他好處(更安全、更方便、更便宜)。
入門篇談過實證醫學(Evidence-Based Medicine, EBM)的三隻腳、證據金字塔、以及 ARR/NNT 這類療效指標。那是「怎麼讀一篇論文的結論」。這篇進階文章要走進更裡面一層:證據是怎麼被「設計」與「合成」出來的。同一批病人、同一個藥,換一種試驗設計、換一種統計分析、換一種統合方法,得到的數字可以截然不同。理解這層機制,你才不會被「有顯著差異」或「沒有顯著差異」這種表面結論牽著走。本文為醫學教育內容,不構成個人化醫療建議。
優越性、不劣性、等效性:問題決定設計
臨床試驗在動筆設計時,第一個要釐清的是「假設的方向」。這決定了整份試驗的統計架構,也決定了結論能說什麼、不能說什麼。
- 優越性試驗(superiority trial):想證明「新介入比對照好」。虛無假設(null hypothesis)是「兩者沒有差別」,研究者希望用資料推翻它。傳統 RCT 多屬此類。
- 不劣性試驗(non-inferiority trial):想證明「新介入沒有比舊的差太多(在可接受範圍內)」。它預設舊藥已被證實有效,新藥即使效果略遜,只要差距小於事先設定的「不劣性界限(non-inferiority margin, Δ)」,又有其他優勢(副作用少、口服取代針劑、價格低),就值得採用。
- 等效性試驗(equivalence trial):想證明「兩者效果落在一個對稱的範圍內」,常見於學名藥(generic)的生體相等性(bioequivalence)研究。
關鍵在於:「沒有達到統計顯著差異」不等於「兩者相等」。這是 EBM 評讀中最常被誤用的一句話。優越性試驗若結果不顯著(p > 0.05),正確的解讀是「沒有足夠證據顯示有差異」,而非「證明了沒有差異」——可能只是樣本太小、檢定力(power)不足。要主張「兩者相當」,必須一開始就用不劣性或等效性設計,並事先定好那條 Δ 界限。
不劣性界限怎麼訂,是整個設計最敏感、也最容易被操弄的環節。界限訂得越寬鬆,新藥越容易「過關」,但臨床意義也越稀薄。一個惡名昭彰的陷阱是「生物蠕變(biocreep)」:第一代新藥「不劣於」原始有效藥、第二代「不劣於」第一代、第三代「不劣於」第二代……每一步都在容許範圍內小幅退步,幾代累積下來,最新的藥可能其實已經不比安慰劑好多少。這提醒我們:讀不劣性試驗時,那條 Δ 是不是合理、是怎麼從歷史試驗推導出來的,比 p 值重要得多。
ITT 還是 PP:你分析的是「分到誰」還是「吃了誰」
試驗做完,要把病人放進哪一組來算?這個看似技術性的選擇,會實質改變結論。
- 意向治療分析(Intention-to-Treat, ITT):按照當初隨機分組的歸屬來分析,不管病人後來有沒有乖乖吃藥、有沒有中途換組、有沒有失聯。
- 依計畫分析(Per-Protocol, PP):只分析真正完整遵照試驗計畫完成療程的人。
直覺上 PP 似乎更「乾淨」——只看真正接受治療的人,效果不是更真實嗎?但 ITT 才是優越性試驗的金科玉律,原因在於隨機化的價值。隨機分組之所以強大,是因為它讓兩組在已知與未知干擾因子上趨於平衡;一旦你因為「沒遵從」就把人剔除,這些人往往不是隨機脫落的——病情較重、副作用較大、依從性差的病人會系統性地被排除,破壞了隨機化建立起來的平衡,重新引入選擇偏誤(selection bias)。
更深一層:ITT 估計的是「指派這個治療策略」的效果(治療意圖效應),這恰恰最貼近真實臨床——醫師能決定的是「開不開這個藥」,沒辦法保證病人百分之百遵從。ITT 因為納入了不遵從者,通常會稀釋療效估計,使其偏向保守,這對優越性試驗是「寧可低估也不高估」的安全方向。
有趣的是,在不劣性試驗裡情況反轉:ITT 的稀釋效應會讓兩組看起來更接近,反而容易製造出「不劣」的假象。因此嚴謹的不劣性試驗要求 ITT 與 PP 兩種分析都做、且結論一致,才比較可信。同一個原則(ITT),在不同設計裡會偏向不同方向——這正是為什麼「分析方法」必須和「試驗問題」配套思考。
複合終點與時間事件:藏在 Hazard Ratio 裡的細節
許多大型試驗用的不是「有沒有中風」這種單一是非題,而是更複雜的結果結構,這裡有兩個進階概念值得拆解。
複合終點(composite endpoint)。 心血管試驗常用「主要不良心血管事件(MACE)」當主要結果,把「心血管死亡+心肌梗塞+中風」綁成一個複合指標。好處是事件數變多、統計檢定力提升、樣本可以小一點。陷阱是:複合終點把嚴重程度不同的事件當成等值。如果一個藥讓「死亡」沒變、卻大幅減少「需要再住院」,整體複合終點可能看起來改善亮眼,但驅動這個結果的其實是最不嚴重的那一項。評讀時要拆開看各個成分的個別貢獻,特別警惕「軟終點(soft endpoint,如住院、再灌流手術)撐起整個結果、硬終點(死亡)紋風不動」的情況。
時間事件分析(time-to-event / survival analysis)。 很多結果不只關心「有沒有發生」,還關心「多快發生」。這時會用 Kaplan-Meier 存活曲線描述各組隨時間的事件累積,並用 Cox 比例風險模型(Cox proportional hazards model) 算出風險比(Hazard Ratio, HR)。HR 是進階文獻最常見、也最常被誤讀的指標之一。
HR = 0.7 常被講成「降低 30% 風險」,但它和入門篇的相對風險(RR)不完全一樣:HR 是瞬時風險(hazard)的比值,反映的是「在任一時間點,治療組相對對照組發生事件的速率」。它的成立倚賴一個重要假設——比例風險假設(proportional hazards assumption):兩組的風險比值在整個追蹤期間維持恆定。一旦兩條存活曲線交叉或先合後分(例如某些癌症免疫療法早期沒效、後期才拉開差距),單一 HR 就會誤導,這時要改看里程碑存活率(landmark analysis)或限制平均存活時間(restricted mean survival time)。看到一個漂亮的 HR,請順手追問:這兩條 Kaplan-Meier 曲線長什麼樣?比例風險假設成立嗎?
看一個例子:統合分析裡的「異質性」
假設你讀到一份統合分析(meta-analysis),整合了 8 份探討「某抗凝血劑預防靜脈栓塞」的 RCT,森林圖(forest plot)最下方的菱形(pooled estimate)顯示 RR = 0.75(95% CI 0.62–0.91),看起來證據充分。但別急著下結論,先看一個常被忽略的數字:I²(異質性指標)= 78%。
I² 衡量的是「各研究結果之間的差異,有多少比例來自真實的研究間異質(heterogeneity),而非單純抽樣機運」。粗略分級:
- I² 約 0–40%:異質性可能不重要。
- I² 約 40–60%:中度異質。
- I² 約 60–90%:高度異質——這正是我們的例子。
I² = 78% 是個警訊:這 8 份研究可能根本不在測同一件事。也許其中幾份用的是不同劑量、不同病人族群(術後 vs 內科住院)、不同追蹤長度。此時把它們硬「平均」成一個數字,那個漂亮的 RR = 0.75 其實意義不大——就像把蘋果和橘子的重量平均。
這也牽涉到統合分析的兩種模型選擇:
- 固定效應模型(fixed-effect model):假設所有研究在估計同一個真實效果,差異純粹來自抽樣誤差。異質性低時適用。
- 隨機效應模型(random-effects model):假設各研究的真實效果本來就略有不同,來自一個效果的分布。異質性高時較合理,但代價是信賴區間會變寬(更誠實地反映不確定性)。
正確的做法不是看到高 I² 就硬套隨機效應了事,而是回頭做次群組分析(subgroup analysis) 或統合迴歸(meta-regression),去找出「是什麼因素讓研究結果分歧」。異質性不是統計的麻煩,而是臨床的線索——它常常在提醒你:療效在不同病人身上,本來就不一樣。
多重比較與提前喊停:被忽略的偽陽性溫床
進階評讀必須對「機運被反覆抽籤的機會」保持警覺。
多重性問題(multiplicity)。 如果一份試驗檢驗 20 個結果,即使所有治療其實都無效,在 α = 0.05 的門檻下,純靠機運也預期會有約 1 個出現「p < 0.05 的顯著結果」。這就是為什麼主要結果(primary endpoint)必須在試驗開始前就事先指定、且通常只有一個。事後才從一堆次要結果或次群組裡挑出顯著的那個來宣傳(俗稱 data dredging 或 p-hacking),是製造偽陽性的溫床。嚴謹的試驗會用 Bonferroni 校正或階層式檢定(hierarchical testing)來控制整體第一型錯誤率(family-wise error rate)。讀到「在某某次群組中達到顯著」時,要問:這是事先假設的,還是事後撈出來的?
期中分析與提前喊停(interim analysis & early stopping)。 大型試驗常設「資料安全監測委員會(DSMB)」做期中分析,若療效已極度明顯或出現嚴重安全疑慮,可提前終止。這在倫理上必要,但「因有效而提前喊停(stopped early for benefit)」的試驗有個系統性傾向:高估療效。因為提前喊停往往發生在效果曲線「運氣好、剛好衝高」的那個時間點,後續可能回落卻沒機會被觀察到。因此會用 O'Brien-Fleming 等「消耗函數(alpha spending)」方法,讓期中分析需要更嚴苛的門檻才能喊停。看到一份「因效果太好而提前結束」的試驗,數字要打點折扣看。
從證據合成到臨床指引:GRADE 的角色
入門篇提過 GRADE(Grading of Recommendations Assessment, Development and Evaluation)會把證據品質分成高、中、低、極低四級。進階視角要理解它的運作邏輯:GRADE 不是看研究設計貼標籤,而是動態加減分。
RCT 的證據起點是「高品質」,但會因以下因素降級:偏誤風險(risk of bias)、結果不一致(inconsistency,即前面講的高異質性)、間接性(indirectness,試驗族群或介入與你的問題對不上)、不精確(imprecision,信賴區間太寬)、發表偏誤(publication bias)。反過來,觀察性研究起點是「低品質」,但若呈現極大的效果量、有劑量反應關係、或所有可能的干擾都只會讓效果被低估,則可以升級。
這套邏輯的精神,是把「證據的可信度」和「推薦的強度」分開處理。可能出現「高品質證據但只給弱推薦」(因為效益與風險很接近、病人偏好分歧大),也可能「低品質證據卻給強推薦」(如極危急又沒有替代方案時)。臨床指引(clinical guideline)裡那個「我們強烈建議/我們有條件地建議」的措辭,背後就是這整套 GRADE 推理——而不只是「有沒有 RCT」這麼簡單。
重點回顧
- 試驗設計的「假設方向」決定結論能說什麼:優越性試驗不顯著只代表「證據不足」,不等於「兩者相等」;要主張相當必須用不劣性/等效性設計並事先定好界限 Δ。
- ITT 保護隨機化、貼近真實臨床、傾向保守,是優越性試驗的標準;但在不劣性試驗中 ITT 反而容易製造「不劣」假象,故需 ITT 與 PP 雙分析一致。
- 複合終點要拆開看各成分貢獻,當心「軟終點撐場、硬終點不動」;Hazard Ratio 依賴比例風險假設,務必回看 Kaplan-Meier 曲線形狀。
- 統合分析要先看 I² 異質性:高異質時硬平均沒有意義,異質性是尋找「療效為何因人而異」的臨床線索,而非單純的統計障礙。
- 多重比較與提前喊停都是偽陽性與高估療效的溫床;主要結果須事先單一指定,「因有效提前終止」的試驗數字要打折看。
深入探討(研究所視角)
走到研究所層級,EBM 的方法學會從「評讀既有證據」推進到「設計與合成證據、並質疑整個證據生態」。
網絡統合分析(network meta-analysis, NMA)。 當臨床上有 A、B、C、D 四種療法,卻只有「A vs B」「B vs C」等零散的頭對頭試驗,缺少全部兩兩直接比較時,NMA 透過共同對照(例如都和安慰劑比過)建立間接比較(indirect comparison),把所有療法放進同一個證據網絡排序。它的效力強大(能回答「哪個最好」),但成立前提是「遞移性假設(transitivity)」——被間接連起來的試驗,在病人族群與設計上要夠相似,否則整個排序會建立在不可比的基礎上。NMA 結果常以「排序機率(SUCRA)」呈現,但要警惕「排第一卻信賴區間極寬」的不穩定排名。
真實世界證據與因果推論的張力。 RCT 內部效度(internal validity)高,但外部效度(external validity)常受限——嚴格的納入排除條件讓試驗族群與門診實際病人差距甚大。真實世界資料(real-world data, RWD,如健保資料庫、電子病歷)涵蓋面廣,卻充滿干擾與選擇偏誤。前述的 target trial emulation 框架,正是試圖用觀察資料「模擬」一個理想 RCT 的設計(明確定義納入時點、治療策略、追蹤起點),以避免 immortal time bias 等經典陷阱。這條路徑與向有向無環圖(DAG)為基礎的因果推論結合,是當代流行病學最活躍的前沿。
最小臨床重要差異與以病人為中心的結果。 統計顯著與臨床重要的鴻溝,在研究所層級具體化為「最小臨床重要差異(minimal clinically important difference, MCID)」的量測學問題:一個量表分數要變動多少,病人才「感覺得到」?這推動了病人報告結果(patient-reported outcomes, PRO)的標準化、以及核心結果集(core outcome set, COS)運動——讓同一疾病領域的所有試驗測量一致、可比、且真正反映病人在乎的事,而非各自挑選最容易達標的替代指標。
證據的可重複性危機與制度回應。 即使方法正確,整個科學體系仍受「可重複性危機(reproducibility crisis)」衝擊:陽性結果偏好、選擇性報告、難以複製的研究結論。制度性對策包括試驗預先登錄(pre-registration)、結果開放共享、登錄式報告(registered reports,方法先審後做)、以及對統計推論本身的反省——從機械化套用 p < 0.05,轉向報告效果量、信賴區間、乃至貝氏後驗機率與證據強度的連續描述。
跨領域的方法遷移。 這套「設計嚴謹、誠實面對不確定、區分顯著與重要」的方法論,正外溢到實證教育(evidence-based education)與學習分析——本平台的 Educational Omics 框架,本質上就是把 EBM 對「多模態資料、效果量、異質性、因果推論」的講究,搬到學習科學的場域。對醫學生與研究者而言,掌握進階 EBM 的真正回報,不是記住一堆統計名詞,而是養成一種習慣:面對任何「研究顯示」的主張,先追問它是怎麼被設計、被分析、被合成出來的,再決定要不要相信。
本文為醫學教育與科學素養之知識讀本,旨在說明實證醫學的進階方法學概念,不構成個人化的醫療建議。任何診斷與治療決策,請與您的主治醫師或合格醫療專業人員討論。