
為什麼一個 99% 準確的檢驗,陽性時卻可能八成是假的?
從盛行率、ROC 曲線到檢驗/治療閾值,拆解診斷檢驗背後可量化的決策結構與常見偏誤。
為什麼一個 99% 準確的檢驗,陽性時卻可能八成是假的?
想像一種號稱「準確度 99%」的新血液篩檢,用於某種盛行率只有萬分之一(0.01%)的罕見癌症。一位健康受檢者拿到陽性報告,慌張地問你:「醫師,我是不是真的得了癌症?」
直覺會說「99% 準,那大概有 99% 機率中了」。但正確答案令人震驚:這個陽性結果有超過 99% 的機率是假警報,受檢者真正患病的機率還不到 1%。同一張檢驗單、同一個「陽性」,放在不同的人身上,意義可以天差地遠。
入門篇談過似然比與貝氏更新的直覺。這篇進階文章要把那層直覺拆解到底層的數學與決策結構:檢驗的好壞不是單一數字,而是一條曲線;一個檢驗值不值得做,取決於可量化的閾值;而看似客觀的「敏感度」「特異度」,其實會隨研究設計與病人族群悄悄漂移。理解這些,才能看穿臨床檢驗報告背後真正的訊息量。本文為醫學教育內容,不構成個人醫療建議。
陽性預測值:被盛行率主宰的真相
入門篇強調敏感度(sensitivity)與特異度(specificity)。但病人在意的從來不是這兩個數字,而是「我陽性,到底有多大機率真的有病?」——這就是陽性預測值(positive predictive value, PPV)。
關鍵洞見是:敏感度與特異度是檢驗本身的性質,理論上不隨族群改變;但 PPV 與陰性預測值(negative predictive value, NPV)卻被盛行率(prevalence)強烈左右。回到開頭的例子,用一個 2×2 列聯表(contingency table)算給你看。假設檢驗敏感度與特異度都是 99%,盛行率 0.01%,受檢人數 100 萬:
- 真正患病者:100 萬 × 0.01% = 100 人。敏感度 99%,驗出 99 個真陽性(TP)。
- 健康者:999,900 人。特異度 99% 代表 1% 假陽性,產生 9,999 個假陽性(FP)。
- 所以陽性總數 = 99 + 9,999 = 10,098 人。
- PPV = TP ÷(TP+FP)= 99 ÷ 10,098 ≈ 0.98%。
陽性者裡只有不到 1% 真的有病。問題不在檢驗不準,而在於健康人的基數太龐大:即使只有 1% 被誤判,假陽性的絕對數量也會輕鬆淹沒稀少的真陽性。這就是公共衛生上「對低盛行率族群做大規模篩檢要極度謹慎」的數學根源,也是為何同一個檢驗用於急診高風險病人(高前測機率)與用於無症狀健檢(低前測機率)時,陽性報告的份量截然不同。
反過來,在這種低盛行率情境,NPV 會高得驚人(接近 100%),所以這類篩檢真正的價值往往是「陰性時讓人安心排除」,而不是「陽性時確診」。一個檢驗在排除與確認上的能力,本來就不對稱。
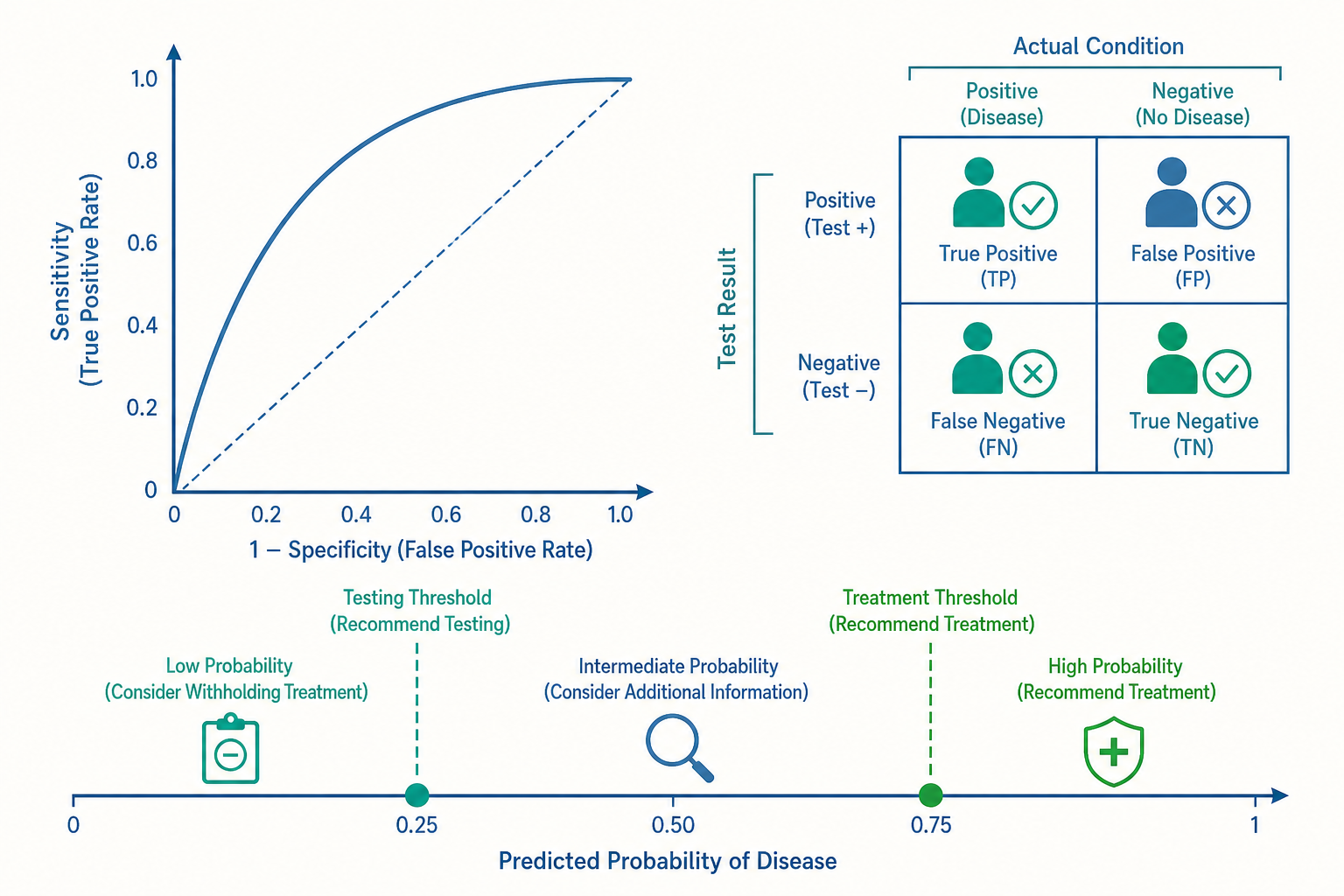
ROC 曲線:檢驗的好壞是一條曲線,不是一個數字
入門篇把敏感度/特異度當成固定值,但對多數連續型檢驗(如肌鈣蛋白 troponin、攝護腺特異抗原 PSA、血糖)來說,這兩個數字其實是你選的切點(cut-off)決定的。
把切點訂得低(容易判陽性):敏感度上升、特異度下降——抓到更多真病人,但假警報變多。把切點訂得高:特異度上升、敏感度下降——更少誤判,但會漏掉病人。敏感度與特異度是一組此消彼長的權衡(trade-off),沒有一個切點能同時讓兩者最大化。
把所有可能切點下的「真陽性率(=敏感度)」對「假陽性率(=1−特異度)」描點連線,就得到 ROC 曲線(receiver operating characteristic curve)。曲線下面積(area under the curve, AUC)是衡量檢驗整體鑑別力的單一指標:
- AUC = 0.5:等於丟銅板,毫無鑑別力(對角線)。
- AUC = 1.0:完美區分病人與健康者。
- AUC ≈ 0.7–0.8:可接受;0.8–0.9:良好;> 0.9:優秀。
AUC 有個漂亮的機率詮釋:隨機抽一個真病人與一個健康者,檢驗值「病人 > 健康者」的機率。它的好處是不受盛行率影響、也不綁定特定切點,因此特別適合用來比較兩種檢驗誰的本質鑑別力更強。
但要小心:AUC 高不代表「在你需要的那個工作點上」表現好。臨床上常常只在乎「高敏感度區段」(不能漏掉心肌梗塞)或「高特異度區段」(不能誤切健康器官),這時要看的是 ROC 曲線局部的形狀,而非整體面積。選切點是一個價值判斷:漏診一個主動脈剝離的代價,遠大於多做一次影像,所以該情境寧可犧牲特異度、把切點壓低。
看一個例子:同一個檢驗、兩個切點
假設某心肌損傷標記在兩個切點下的表現如下:
| 切點 | 敏感度 | 特異度 | 適用情境 |
|---|---|---|---|
| 低(0.01 ng/mL) | 98% | 60% | 急診排除:寧可多留觀察,不可漏掉梗塞 |
| 高(0.05 ng/mL) | 80% | 95% | 確認診斷:要把握度高才啟動侵入性治療 |
同一支試劑、同一台機器,只因切點不同,「陽性」的意義就從「需要進一步排除」變成「高度懷疑確診」。臨床指引常因此設兩個甚至連續的決策區間(如 0/1 小時 troponin 演算法)——用低切點先安全排除一大群人,再用高切點與時序變化(delta)鎖定真正高風險者。這正是 ROC 思維落地成臨床流程的縮影。
檢驗閾值與治療閾值:要不要做這個檢查,可以算
入門篇結尾提過「測試閾值理論」,這裡把它真正展開,因為它是把診斷從藝術變成可推導決策的關鍵。
對任一疾病,病人的患病機率落在 0 到 1 之間的某處。Pauker 與 Kassirer 提出的閾值模型(threshold approach)指出,這條機率軸上存在兩個臨界點:
- 檢驗閾值(testing threshold):機率低於它,連檢查都不必做,直接當作沒病、不治療。再驗下去,假陽性帶來的傷害(不必要的後續侵入檢查、焦慮、過度治療)會超過罕見真陽性的好處。
- 治療閾值(treatment threshold):機率高於它,不必再驗,直接治療。再驗下去只是拖延,且假陰性可能害你錯失治療時機。
- 兩閾值之間的「灰區」:才是檢查真正有價值的地方——只有在這裡,一個檢驗結果有機會把機率推過某個行動線、改變你的處置。
這個模型的深刻之處在於:閾值的位置由「治療的好處與壞處之比」決定,而不只是檢驗本身。治療閾值大致可寫成
治療閾值 ≈ 傷害 ÷(傷害+好處)
其中「傷害」是對沒病者誤治的代價,「好處」是對有病者正確治療的獲益。當治療本身風險很低、漏治後果嚴重(例如疑似敗血症給抗生素),治療閾值就很低——機率不高也該先治;反之當治療風險高(例如大手術、化療),治療閾值就拉高,必須更確定才動手。
這解釋了一個常被誤會的現象:同一個病人、同一個檢驗結果,A 醫師決定治療、B 醫師決定再觀察,未必有人犯錯——可能只是兩人對「治療傷害 vs 好處」的權衡(也就是閾值位置)不同。診斷決策的爭論,本質上常是價值權衡的爭論,不純是事實的爭論。
序列檢驗與獨立性陷阱
真實診斷很少只做一個檢查,而是一連串檢驗逐步更新機率。入門篇示範過單一似然比更新;進階版要面對「多個檢驗如何串接」。
最常見的策略有兩種:
- 序列檢驗(serial testing):先做便宜、高敏感的篩檢,陰性就停(安全排除);陽性才接昂貴、高特異的確認檢驗(如 HIV 先做篩檢、陽性再做確認)。整體特異度上升、敏感度下降,適合追求「確診要準」。
- 平行檢驗(parallel testing):同時做多個檢查,任一陽性就算陽性。整體敏感度上升、特異度下降,適合急診「不能漏」的情境。
連續用似然比相乘來更新機率(後測勝算 = 前測勝算 × LR₁ × LR₂ × …)有個致命前提:各檢驗必須條件獨立(conditionally independent)。但臨床上常常不獨立——兩個檢驗若測的是同一個底層生理機制(例如兩種都反映心肌缺氧的指標),它們的錯誤會高度相關。此時天真地把似然比連乘,會系統性高估診斷把握度,產生過度自信的後測機率。
這是進階臨床推理與簡化教科書公式的真正分野:新增一個檢驗帶來的「增量資訊(incremental value)」,往往遠小於它單獨的似然比所暗示的。一個成熟的診斷者會問:「這第三個檢查,在前兩個已經告訴我的之外,真的還補上了新資訊嗎?」——這也呼應了現代生物標記研究強調的「增量預測價值」評估,而非只看單一標記的 AUC。
看穿檢驗研究的偏誤:你信的那個敏感度可能是膨脹的
最後一層進階素養,是懷疑檢驗準確度數字本身。「這個檢驗敏感度 92%」這句話,數字從哪個研究、哪群人算出來的,決定了它能不能套用到你眼前的病人。兩個最經典的陷阱:
- 頻譜偏誤(spectrum bias):若敏感度/特異度是在「明顯重症 vs 健康人」這種兩極族群算出的,數字會被人為灌水——因為極端個案最好分辨。但臨床真正困難的,是介於兩者之間的未分化、早期、輕症病人。把教科書上漂亮的數字,套用到比研究族群更接近灰區的真實病人,準確度往往明顯打折。
- 驗證偏誤(verification / work-up bias):若只有「檢驗陽性者」才被安排昂貴的金標準(gold standard)去確認,而陰性者很少被追下去,那麼假陰性會被系統性漏算,敏感度被高估。
此外還有金標準本身不完美的問題:當我們用來定義「真相」的參考檢驗(如某些病理或培養)本身就會出錯,新檢驗與一個有缺陷的標準相比,算出來的準確度自然失真。這也是為什麼讀一篇診斷準確度研究時,國際上有 STARD 報告規範(Standards for Reporting of Diagnostic Accuracy),要求作者交代取樣方式、誰被金標準驗證、盲性如何維持等細節——這些設計細節,直接決定那個敏感度數字能不能信。
動手試試:替一個「95% 敏感度」做盡職調查
下次看到「某快篩敏感度 95%」,試著追問五個問題:
- 研究對象是誰?是症狀明顯的住院病人,還是社區無症狀者?(頻譜偏誤)
- 陰性者也都被金標準驗證了嗎?還是只驗陽性者?(驗證偏誤)
- 當作「真相」的金標準本身有多可靠?
- 這個數字對應的切點是多少?換到我的決策切點還成立嗎?
- 研究族群的盛行率,跟我面前這個病人的前測機率接近嗎?
你會發現,一個孤立的百分比幾乎無法直接用——診斷準確度永遠是「在某個族群、某個設計、某個切點下」的條件性陳述。
重點回顧
- PPV 由盛行率主宰:敏感度/特異度是檢驗性質,但「陽性到底多可能真有病」會隨族群劇烈變化;低盛行率下,再準的檢驗也可能陽性多為假警報。
- 檢驗好壞是一條 ROC 曲線:對連續型檢驗,敏感度與特異度隨切點此消彼長;AUC 衡量整體鑑別力且不受盛行率影響,但選切點是反映臨床代價的價值判斷。
- 要不要做檢查可以算:檢驗閾值與治療閾值切出三個區間,只有落在「灰區」的檢查才改變處置;閾值位置由治療的傷害/好處之比決定。
- 多檢驗串接有獨立性陷阱:似然比連乘要求條件獨立,否則會高估把握度;該問的是新檢查的「增量資訊」而非單獨似然比。
- 準確度數字要做盡職調查:頻譜偏誤、驗證偏誤與不完美金標準會膨脹敏感度/特異度;STARD 等報告規範就是為了讓這些設計細節攤在陽光下。
深入探討(研究所視角)
把上述概念統整起來,診斷決策可以被形式化為一個期望效用最大化(expected utility maximization)問題。對每個可能的處置(不治療、再檢查、直接治療),給定當下的後測機率分布與各結局的效用(utility),計算其期望效用,選擇最高者。閾值模型其實就是這個最佳化問題在「二元疾病、單一檢驗」簡化下的閉式解——治療閾值正是「直接治療的期望效用」等於「不治療的期望效用」的那個機率交會點。這把第一段那位「治療還是觀察」的醫師爭論,安放進一個可量化的決策框架:差異往往不在機率估計,而在效用函數(病人對副作用、漏診、侵入檢查的偏好權重)不同。
ROC 框架在研究所層級還連向兩個進階主題。其一是校準(calibration)與鑑別(discrimination)的分離:AUC 只衡量「排序能力」(高風險者是否被排在前面),卻完全不保證「模型輸出的 70% 真的對應 70% 的觀察頻率」。一個 AUC 高但校準差的模型,在臨床決策上可能很危險,因為閾值決策直接依賴機率的絕對值。其二是淨效益(net benefit)與決策曲線分析(decision curve analysis):傳統 AUC 把假陽性與假陰性視為等價,但臨床上兩者代價天差地遠;決策曲線把「治療閾值」當作可變參數,畫出模型在各種臨床偏好下的淨效益,比單一 AUC 更貼近真實決策價值。這也是當代預測模型(含醫療 AI)評估從「比 AUC」轉向「比臨床效用」的核心轉折。
最後,把鏡頭拉到過度診斷(overdiagnosis)這個由上述機率結構直接孳生的系統性難題。當篩檢技術越來越敏感、能偵測越來越微小的異常,我們不可避免地會抓到大量「終其一生都不會造成傷害」的病灶(如某些惰性的早期癌或偶見影像異常)。這不是檢驗出錯,而是敏感度提升的必然副產物:在低盛行率與不完美特異度的乘積效應下,偽陽性與「真陽性但無臨床意義」會一起膨脹,帶來不必要的標籤化、焦慮與後續介入傷害。這提醒我們,診斷的終極目標從來不是「偵測到最多異常」,而是「做出能真正改善病人結局的判斷」。能區分「測得到」與「值得治」,分辨「統計上的陽性」與「臨床上的重要」,才是診斷學從技術走向智慧的最後一哩。
(本文為醫學教育性質之知識讀本,旨在說明臨床檢驗與診斷決策之原理,不構成任何個人診斷或醫療建議。身體不適或對檢驗報告有疑問,請諮詢合格醫療專業人員。)