
同樣血壓 145,為什麼有人該吃藥、有人不必?
從閾值思維走向風險思維:用絕對風險、NNT 與篩檢偏差,看懂常見疾病臨床決策背後的機率與證據邏輯。
同樣血壓 145,為什麼有人該吃藥、有人不必?
讀過入門篇後,你已經知道三高(hypertension、hyperglycemia、dyslipidemia)背後的恆定失衡與動脈粥狀硬化機制。現在來看一個臨床上每天都在發生、卻常令人困惑的場景:兩位都是血壓 145/92 mmHg 的患者,一位 38 歲、不抽菸、家族史乾淨;另一位 68 歲、糖尿病多年、曾抽菸三十年。同樣的數值,醫師對前者可能先建議三個月的生活型態調整再追蹤,對後者卻會立刻開立降壓與降脂藥物。
這不是醫師「看心情」,而是現代慢性病處置的核心邏輯已經悄悄轉移:我們治療的不再是「一個數字」,而是「一個人未來十年發生心血管事件的整體機率」。要看懂這個轉移,必須引入一套量化推理的工具——絕對風險(absolute risk)、相對風險(relative risk)、風險分層(risk stratification)、以及衡量治療值不值得的 NNT(number needed to treat)。這篇進階文章,就帶你進入臨床決策背後那層「機率與證據」的世界。
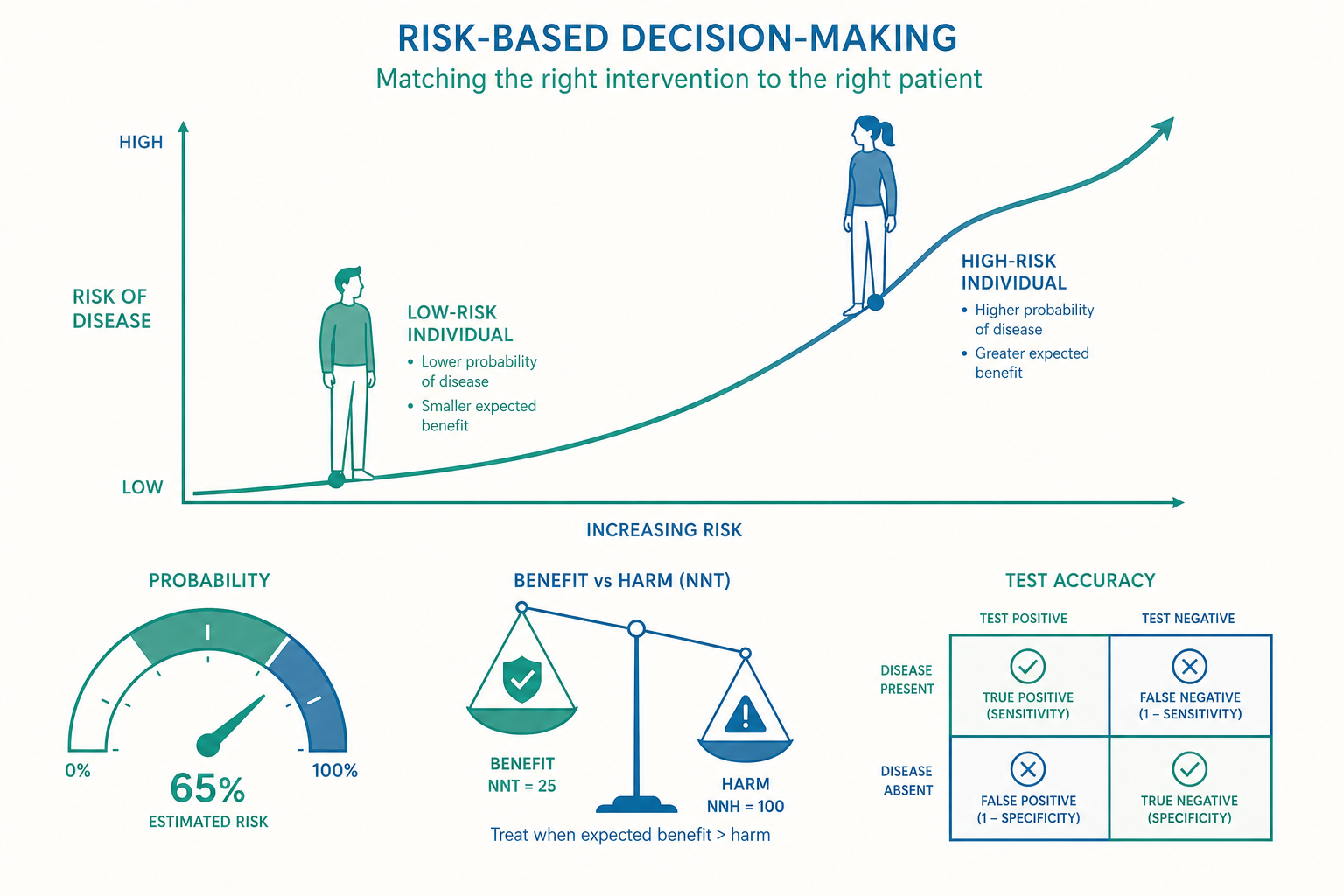
從「閾值思維」到「風險思維」
入門篇提到,血壓 140/90 mmHg 是傳統的高血壓診斷界線。閾值(threshold)思維很直覺:超過線就是病、就要治。但它隱含一個錯誤假設——彷彿 139/89 安全、141/91 危險,風險在那條線上瞬間跳升。實際上,心血管風險與血壓、血糖、膽固醇之間是連續且大致呈對數線性的關係:血壓從 115/75 開始,每升高 20/10 mmHg,心血管死亡風險約增為兩倍。風險是一條平滑上升的曲線,閾值只是我們為了方便溝通在曲線上畫的一條人為刻度。
更關鍵的是,同樣的數值對不同人意味著不同的絕對風險。所謂絕對風險,是指「某個特定個體在特定時間內(通常是 10 年)實際發生某事件的機率」。前述 38 歲年輕人血壓 145,他的 10 年心血管事件絕對風險可能只有 2–3%;68 歲、糖尿病、曾吸菸者即使同樣 145,絕對風險可能高達 25–30%。血壓只是眾多風險因子之一,年齡、性別、吸菸、糖尿病、膽固醇、家族史共同決定了那條曲線上你站的位置。
這就是為什麼當代指引(如美國 ACC/AHA、歐洲 ESC)都搭配風險計算器:例如美國的 Pooled Cohort Equations、歐洲的 SCORE2、台灣本土化的風險模型。輸入年齡、血壓、膽固醇、是否糖尿病與吸菸等變項,輸出一個百分比——這個百分比,而非單一檢驗值,才是決定「要不要用藥、用多猛」的真正依據。
相對風險 vs 絕對風險:最容易被誤導的數字
媒體最愛報導「某藥物降低心臟病風險 30%」「常吃某食物罹癌風險增加 50%」。這些聳動的百分比,幾乎都是相對風險(relative risk reduction / increase),而它常常嚴重誤導。
關鍵在於分清兩件事:
- 相對風險降低(RRR):治療組事件率相對於對照組下降的「比例」。
- 絕對風險降低(ARR):治療組與對照組事件率的「差值」(百分點)。
舉個具體例子。假設一種降脂藥讓 10 年心臟病風險「相對下降 30%」。如果某患者本來的絕對風險是 30%,吃藥後降到 21%——絕對下降了 9 個百分點,這是極大的獲益。但如果另一位本來絕對風險只有 2%,同樣「相對下降 30%」只是把風險從 2% 降到 1.4%——絕對只降了 0.6 個百分點。同一個「30%」,在高風險者身上是救命,在低風險者身上幾乎沒差別。
這正是「治療高風險者效益遠大於低風險者」的數學根源,也是為什麼回到開頭:同樣血壓 145,高風險的長者吃藥划算,低風險的年輕人未必。相對風險隱藏了「基準風險(baseline risk)」這個關鍵分母;只有絕對風險,才告訴你介入「真正能改變多少」。
看一個例子:用 NNT 衡量一個治療值不值得
把上述邏輯量化成一個極實用的指標:NNT(number needed to treat,需治療人數)。它的定義很簡單:
NNT = 1 ÷ 絕對風險降低(ARR,以小數表示)
意思是:為了避免「一個」不良事件發生,需要治療多少人、多少年。NNT 越小,治療效益越高。
延續上面的例子:
- 高風險患者:ARR = 30% − 21% = 9% = 0.09,NNT = 1 ÷ 0.09 ≈ 11。意思是治療 11 位這樣的高風險患者 10 年,可避免 1 次心血管事件。非常值得。
- 低風險患者:ARR = 2% − 1.4% = 0.6% = 0.006,NNT = 1 ÷ 0.006 ≈ 167。要治療 167 位這樣的低風險者 10 年,才能避免 1 次事件。其餘 166 人吃了藥卻不會因此獲益,還要承擔藥物副作用與成本。
NNT 把抽象的機率翻譯成「治療多少人換一個好結果」的具體語言,讓醫病雙方能在「獲益」與「負擔(副作用、費用、長期服藥的心理成本)」之間做更誠實的權衡。對應地還有 NNH(number needed to harm,需傷害人數):平均治療多少人會造成一次藥物相關傷害。一個治療是否「划算」,本質上是 NNT 與 NNH 的拉鋸——這也是實證醫學(evidence-based medicine)做臨床決策時的核心算式。
篩檢的兩難:為什麼「早期發現」不總是好事
入門篇強調健檢紅字是「提早發出的訊號」。這在三高等慢性病確實成立——早期介入效益最好。但把「早期發現一定有益」推廣到所有疾病(尤其癌症篩檢),就會落入幾個統計學陷阱,這是進階學習者必須警覺的。
前導時間偏差(lead-time bias):篩檢讓疾病「更早被診斷」,但若無法改變疾病進程,患者只是「更早知道自己生病」,從診斷到死亡的時間看似變長,實際存活並未延長。存活期統計被人為拉長,造成「篩檢有效」的錯覺。
病程長度偏差(length-time bias):進展緩慢、惰性的腫瘤停留在「可被篩檢偵測」的視窗更久,因此更容易在篩檢時被抓到;而惡性、快速進展的腫瘤常在兩次篩檢之間就發病。結果篩檢偏向揪出「本來預後就好」的病灶,再次高估篩檢的好處。
過度診斷(overdiagnosis):篩檢可能找到一些「終其一生都不會造成症狀或死亡」的病變(例如某些低惡性度的早期癌、或進展極慢的結節)。發現它們不僅無益,反而帶來不必要的手術、放療、焦慮與標籤化——這正是「健康人被製造成病人」的反面風險。
理解這些偏差,才能解釋一個違反直覺卻被反覆驗證的事實:不是每一項篩檢都應該對每個人做。一項好的篩檢必須同時滿足——疾病有可偵測的早期階段、早期治療確實改變預後、篩檢工具夠準(高敏感度與特異度)、且整體效益大於過度診斷的傷害。這也是為什麼篩檢指引會依年齡、風險族群劃定範圍,而非「人人都驗、越多越好」。
敏感度、特異度與「陽性不一定有病」
既然談篩檢,就必須理解檢驗本身的不確定性。任何檢驗都不是完美的真/假判官,而要用兩個指標描述其表現:
- 敏感度(sensitivity):真正有病的人中,被檢驗正確判為陽性的比例(抓得到病人的能力)。
- 特異度(specificity):真正沒病的人中,被正確判為陰性的比例(排除健康人的能力)。
實務上最容易被誤解的是陽性預測值(positive predictive value, PPV)——「檢驗陽性的人,真的有病的機率」。它不只取決於敏感度與特異度,還強烈受到該疾病在受檢族群中盛行率(prevalence)的影響。
舉例:某檢驗敏感度 99%、特異度 99%,聽起來幾乎完美。但若拿去篩一個盛行率僅 0.1%(每千人 1 人患病)的罕見病:每 10 萬人中有 100 人真患病(99 人驗出陽性),另有 99,900 健康人中約 1% 即 999 人被誤判為陽性。於是陽性者共 99+999 ≈ 1098 人,其中真正有病的只有 99 人——PPV 僅約 9%。換言之,在低盛行率族群中,即使是高準確度的檢驗,陽性結果有九成是假警報。這就是為什麼篩檢要鎖定高風險(高盛行率)族群,也是為什麼陽性結果常需要更精準的「確診檢查」二次驗證。這套推理背後其實是貝氏定理(Bayes' theorem):檢驗結果更新的是「事前機率」,而事前機率由盛行率決定。
重點回顧
- 從閾值到風險:心血管風險與血壓、血糖、膽固醇呈連續曲線,閾值只是人為刻度;現代決策看的是個體 10 年絕對風險,而非單一數值。
- 相對 vs 絕對風險:媒體常報的「降低 30%」是相對風險,會隱藏基準風險;只有絕對風險降低(ARR)才反映介入真正改變了多少。
- NNT 是實用的決策尺:NNT = 1 ÷ ARR,把機率翻譯成「治療幾人換一個好結果」;高風險者 NNT 小(值得),低風險者 NNT 大(效益有限),需與 NNH 權衡。
- 早期發現有陷阱:前導時間偏差、病程長度偏差與過度診斷,會系統性高估篩檢效益;好的篩檢需嚴格條件,並非人人皆驗越多越好。
- 陽性不等於有病:陽性預測值取決於盛行率,低盛行率族群中即使高準確度檢驗也會產生大量假陽性,這是貝氏推理的必然。
深入探討(研究所視角)
對想更進一步的讀者,這套「機率化的臨床決策」正是當代實證醫學與臨床流行病學最活躍的交會處。
第一個方向是風險預測模型的開發與驗證。傳統 Cox 比例風險模型(Cox proportional hazards model)與 logistic 迴歸仍是骨幹,但機器學習方法(梯度提升樹、深度學習)正被用於整合更高維度的變項。然而,模型的「鑑別力(discrimination,以 C-statistic / AUC 衡量)」與「校準度(calibration,預測機率與實際發生率是否相符)」必須分開評估——一個 AUC 很高卻校準不良的模型,會系統性高估或低估某族群的風險,反而誤導決策。如何把模型從衍生世代(derivation cohort)外推到不同族群(external validation),以及如何避免演算法放大既有的健康不平等,是當前熱議的議題。
第二個方向是競爭風險(competing risks)與個體化治療效應。一位 85 歲長者「10 年心血管風險」的意義,與一位 45 歲者截然不同,因為前者可能因其他原因先離世——這正是競爭風險分析(如 Fine-Gray 模型)要處理的問題。更前沿的是「異質性治療效應(heterogeneous treatment effects, HTE)」研究:同一個藥對不同次族群的效益可能差異極大,傳統 RCT 報告的「平均治療效應」可能掩蓋了「有些人大幅獲益、有些人毫無好處甚至受害」的真相。因果推論(causal inference)方法與目標試驗模擬(target trial emulation)正試圖從觀察性大數據中逼近這些個體化答案。
第三個方向呼應本平台 Educational Omics 的精神:多模態資料下的「軌跡」而非「快照」。單次健檢是一張快照,但疾病是一條軌跡。透過縱貫追蹤血壓、血糖、發炎指標、甚至穿戴裝置的連續生理訊號(如 HRV、睡眠),研究者試圖捕捉個體偏離恆定的「動態過程」,在風險真正升高前就辨識出來。這與教育研究從「期末成績」走向「學習歷程分析」的轉向如出一轍——醫學與教育都在學習如何閱讀「時間中的人」,而非只看某一刻的截面。
對研究所階段的學習者而言,最重要的素養或許是:能讀懂一篇臨床試驗,分清它報告的是相對還是絕對風險、NNT 多少、外推到你的病人是否成立。掌握生理機制是地基,而能用機率與證據的語言審視每一個治療宣稱,才是把醫學從「權威說了算」推向「可被檢驗的科學」的關鍵能力。
(本文僅為醫學知識與統計推理的教育說明,所有數值均為示意性舉例,不構成個人醫療建議。任何檢驗判讀、用藥與篩檢決策,請與您的醫師討論。)