
同一盤生菜,有人沒事、有人住院:風險到底「住」在哪裡?
用定量微生物風險評估(QMRA)走完從一顆病原菌到族群健康衝擊的推導鏈:預測微生物學、劑量—反應模型、二維蒙地卡羅與源頭歸因。
同一盤生菜,有人沒事、有人住院:風險到底「住」在哪裡?
你已經知道危害(hazard)不等於風險(risk)、知道「劑量決定毒性」、也知道一場群聚要用相對風險(relative risk, RR)與潛伏期去揪出載具。但這裡有一個更尖銳的問題:當衛生主管機關問「如果這批生菜每公克帶有平均 10 個腸道出血性大腸桿菌(E. coli O157:H7),全國有 200 萬人吃下肚,會有多少人住院、多少人併發溶血性尿毒症候群(HUS)?」——你要如何從「每公克幾個菌」這個微觀數字,一路推導到一個可以寫進政策、決定要不要全面下架的族群層次風險估計?
入門告訴你「食品會集體出事」,進階則要求你把這句話拆解成一條可量化的因果鏈:菌量會隨時間溫度變化、吃進去的劑量是一個機率分布、每個劑量對應一個感染機率、感染再分支成發病、住院、死亡。這條從一顆菌到一個族群健康衝擊的推導鏈,正是定量微生物風險評估(Quantitative Microbial Risk Assessment, QMRA)的核心,也是進階食品安全與入門最大的分野。這篇文章,我們就走完這條鏈。
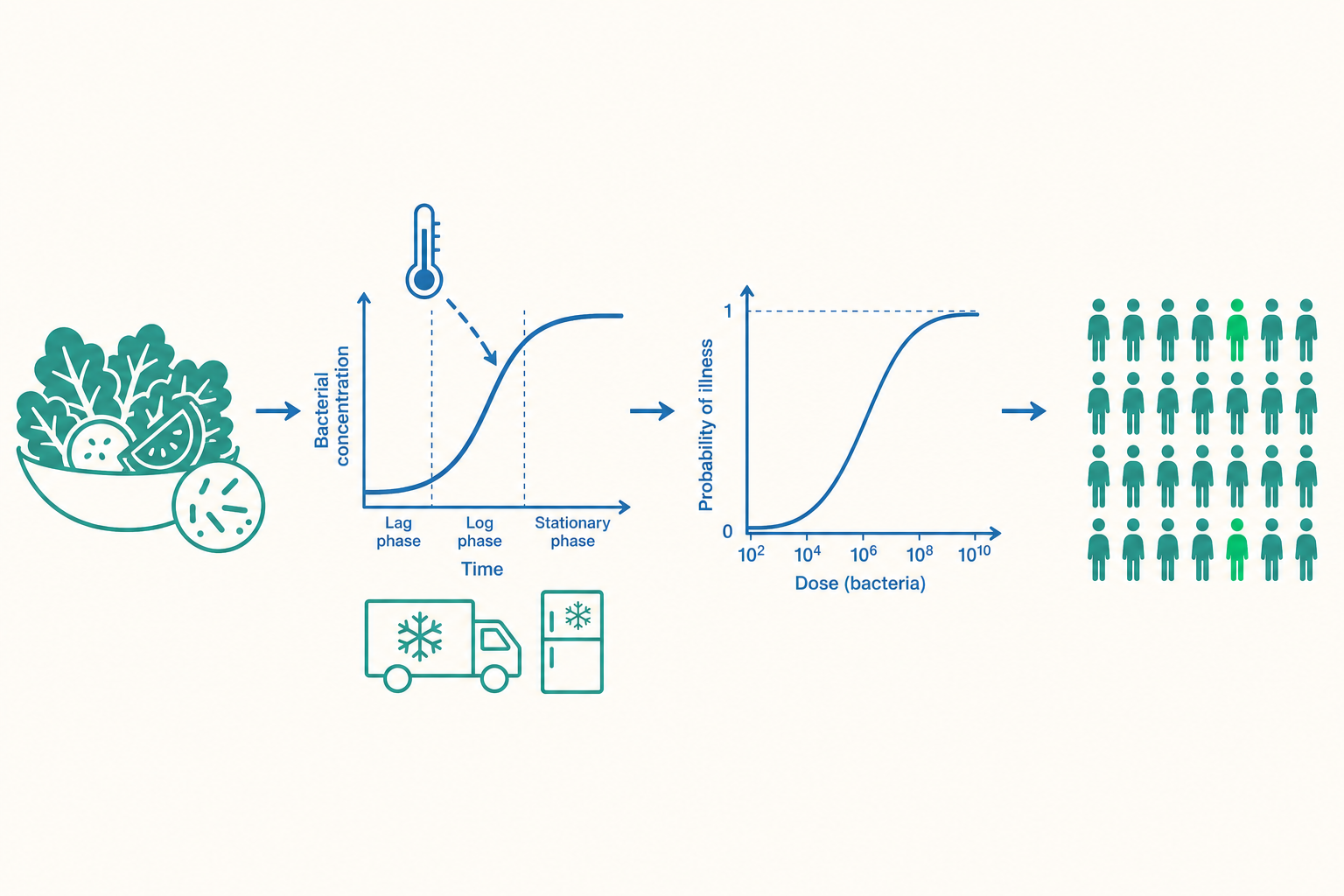
為什麼微生物風險需要一套和化學品不同的數學
入門文章用 NOAEL 除以不確定係數得出每日可容許攝取量(ADI),那是化學性危害的典範。但生物性危害有兩個化學品沒有的特質,使得整套數學必須改寫。
第一,微生物會增殖也會死亡。一塊放在 4°C 的雞肉,菌數可能緩慢上升;同一塊放在 25°C 的廚房檯面兩小時,菌數可能暴增千倍。化學汙染物的濃度在儲存運送過程中大致恆定,但微生物的「劑量」是一個隨時間與溫度動態變化的量。這意味著風險不只取決於「原料汙染了多少」,更取決於「從產地到餐桌這段路,菌有沒有機會長大」。
第二,單一顆病原菌就可能致病。化學毒理學的主流假設是「有閾值」——低於某劑量不會有可見效應。但對許多腸道病原(如 O157:H7、諾羅病毒),主流模型假設無閾值:理論上即使只吃進一顆有活性的病原,仍有非零的感染機率。這把問題從「平均濃度有沒有超標」徹底轉向「每一份食物裡,剛好有幾顆菌、剛好被哪個人吃到」的機率問題。
這兩個特質合起來,逼出了 QMRA 的四個模組:暴露評估(exposure assessment)要追蹤菌數的動態變化、危害特徵描述(hazard characterization)要建立病原的劑量—反應模型、再整合成風險特徵描述。下面逐一拆解。
預測微生物學:把「菌會長大」寫成方程式
QMRA 的暴露評估之所以困難,是因為要回答「這份食物送到嘴邊時帶有多少菌」,就得預測微生物在整條供應鏈中的生長與死亡。這門學問叫預測微生物學(predictive microbiology)。
最基礎的工具是描述菌落生長的 S 型曲線。一個常用的形式是 Gompertz 模型或 Baranyi 模型,它們把菌數對數值 $\log N(t)$ 描述成:先有一段幾乎不生長的遲滯期(lag phase),接著進入近似指數的對數生長期(exponential phase),最後因養分耗竭與代謝物累積進入靜止期(stationary phase)。其中對數生長期的斜率,就是比生長速率(specific growth rate, $\mu$)。
關鍵在於:$\mu$ 不是常數,它強烈受溫度、pH 值、水活性(water activity, $a_w$)與防腐劑濃度共同決定。描述這層關係的叫二級模型(secondary model),例如 Ratkowsky 平方根模型:
$$\sqrt{\mu} = b \,(T - T_{min})$$
其中 $T$ 是儲存溫度、$T_{min}$ 是該菌種理論上能生長的最低溫度、$b$ 是菌種特定的常數。這條看似簡單的式子有巨大的政策含義:因為 $\mu$ 與 $(T - T_{min})^2$ 成正比,溫度只要小幅上升,生長速率就以平方倍率加速。這就是為什麼「冷鏈(cold chain)斷一小時」遠比直覺中嚴重——它不是線性的小失誤,而是把整條生長曲線往左平移、讓菌提早進入爆發性生長。
看一個例子:冷鏈中斷讓菌數翻幾倍?
假設某即食沙拉初始帶有李斯特菌(Listeria monocytogenes)$N_0 = 100$ CFU/g。物流規範要求全程維持 4°C,此時比生長速率極低、近乎不長。但某次配送冷藏故障,產品在 15°C 下停留了 8 小時。
由 Ratkowsky 模型,李斯特菌 $T_{min} \approx -1.5°C$。粗略估計,4°C 與 15°C 的生長速率差距約為:
$$\frac{\mu_{15}}{\mu_4} = \frac{(15 - (-1.5))^2}{(4 - (-1.5))^2} = \frac{16.5^2}{5.5^2} = \frac{272}{30} \approx 9$$
也就是說,同樣的時間,15°C 下菌長得約是 4°C 的 9 倍快。若在 15°C、8 小時內李斯特菌約增殖 1.5 個對數值(即 $\times$ 32 倍),則出貨時菌數已從 100 CFU/g 攀升到約 3,200 CFU/g。對一般人或許仍在可接受範圍,但對孕婦、新生兒、免疫低下者,李斯特菌症(listeriosis)的致死率可高達 20–30%——同一份產品,因為脆弱次族群的存在,風險評估的結論完全不同。這也呼應了入門提過的核心倫理:公共衛生要保護的不是「平均人」,而是分布尾端最脆弱的人。
劑量—反應模型:從「吃進幾顆」到「感染機率」
預測微生物學告訴我們入口時的菌數分布,下一步是把「吃進的劑量 $d$」轉換成「感染機率 $P_{inf}$」。這是 QMRA 與化學風險評估數學上最不同之處。
對無閾值的病原,最常用的是指數模型(exponential model)。它的核心假設是:每一顆吃進去的病原,獨立地以機率 $r$ 成功存活並引發感染("single-hit" 假設)。若吃進 $d$ 顆,則「沒有任何一顆成功」的機率是 $(1-r)^d$,因此至少感染一次的機率為:
$$P_{inf}(d) = 1 - e^{-r d}$$
其中 $r$ 是單一病原的感染效率,由人體餵食實驗(human feeding study)或爆發資料反推。但指數模型假設「人人對病原的易感性相同」,這在現實中太理想。更普遍的是 Beta-Poisson 模型,它允許 $r$ 在人群與菌株間有變異(用 Beta 分布描述),形式近似為:
$$P_{inf}(d) = 1 - \left(1 + \frac{d}{\beta}\right)^{-\alpha}$$
其中 $\alpha$、$\beta$ 是擬合參數。$\alpha$ 越小,代表族群易感性的異質性越大。諾羅病毒之所以惡名昭彰,部分原因正是它的 $\alpha$ 極小——意味著極低的劑量(幾十顆病毒顆粒)對某些人就足以致病,而這正是它在郵輪、學校、安養機構反覆爆發的數學根源。
要特別澄清一個常見誤解:劑量—反應模型給出的是感染(infection)機率,不是發病(illness)機率,更不是重症或死亡。完整的 QMRA 必須再串接條件機率:
$$P_{ill} = P_{inf} \times P(ill \mid inf), \quad P_{death} = P_{ill} \times P(death \mid ill)$$
每一個箭頭都是一層流行病學參數,且都隨年齡、免疫狀態、病原毒力而變。把這些機率乘起來,再乘上暴露人口數,才得到族群層次的預期病例數、住院數與死亡數。
整合不確定性:二維蒙地卡羅與「變異 vs. 無知」
入門的研究所視角提過用蒙地卡羅模擬處理族群異質性。進階要更進一步區分兩種本質不同的不確定性,這是 QMRA 方法論的精華。
- 變異性(variability):是世界本身的真實差異——不同人吃不同份量、不同產品帶不同菌數、不同個體易感性不同。再多研究也消不掉它,只能更精細地描述其分布。
- 不確定性(uncertainty):是我們知識的不足——我們不確定 $r$ 到底是 0.001 還是 0.005,因為人體實驗樣本太少。這種不確定性原則上可以靠更多資料縮小。
成熟的 QMRA 用二維蒙地卡羅模擬(two-dimensional Monte Carlo)把兩者分開:內層迴圈抽樣變異性(模擬一個真實族群的個體差異),外層迴圈抽樣參數的不確定性(模擬「如果我們對參數的估計是錯的」)。最後得到的不是單一風險數字,而是一整片風險的可能分布——既告訴決策者「最可能的病例數」,也誠實標示「我們的估計有多不確定」。
這個區分的政策意義極大:如果風險很高但不確定性很小,該果斷管制;如果風險估計很高但不確定性巨大,理性的回應可能是「先投資研究把參數釘住」,而非貿然花大錢全面管制。把「世界的隨機」和「我們的無知」分開,是科學誠實的最高形式之一。
源頭歸因:全國的食源性疾病,該怪誰?
入門講的是「單一群聚怎麼揪兇手」。但站在國家層級,主管機關面對的是另一個尺度的問題:每年全國數十萬例食源性疾病,分別該歸因於哪些食物、哪些病原、哪些環節? 沒有這個答案,就無法決定把有限的稽查與研究資源投到哪裡。這叫源頭歸因(source attribution)。
常用的取徑有三類:
-
微生物次分型法(microbial subtyping):把人類病例分離到的菌株,用全基因體定序(WGS)和各種食品/動物來源的菌株庫比對,依相似度把病例「分配」回最可能的動物宿主。丹麥的沙門氏桿菌歸因模型就是經典範例,它能估出「今年的人類沙門氏桿菌病例中,約幾成來自雞肉、幾成來自豬肉」。
-
流行病學分析法:整合大量爆發調查資料(哪些爆發由哪種食物引起),外推到散發病例(sporadic cases)的食物來源比例。
-
專家誘出法(expert elicitation):在資料不足的領域,用結構化方法蒐集多位專家的判斷並量化其不確定性。
這些方法的共同精神,與入門提過的 WGS「把分散個案拼回族群事件」一脈相承,只是尺度從「一場婚宴」放大到「一整個國家、一整年」。源頭歸因的產出,最終會餵進前面說的 QMRA 與 DALY 排序,形成完整的風險治理閉環(risk governance loop):監測 → 歸因 → 評估 → 管制 → 再監測。
動手試試:用劑量—反應模型比較兩種介入
假設某病原符合指數模型,單顆感染效率 $r = 0.001$。現有一份食品平均帶有 $d = 500$ 顆活菌。
先算現況的感染機率:
$$P_{inf} = 1 - e^{-0.001 \times 500} = 1 - e^{-0.5} \approx 1 - 0.607 = 0.393$$
約 39.3% 的食用者會被感染。現在比較兩種介入方案:
- 方案 A(源頭減量):改善農場衛生,使初始菌數降為原本的 1/10,即 $d = 50$。 $$P_{inf} = 1 - e^{-0.001 \times 50} = 1 - e^{-0.05} \approx 0.049$$
- 方案 B(末端加熱):增加一道殺菌步驟,使菌數降為原本的 1/100,即 $d = 5$。 $$P_{inf} = 1 - e^{-0.001 \times 5} = 1 - e^{-0.005} \approx 0.00499$$
解讀:方案 A 把感染機率從 39.3% 降到約 4.9%(降幅約 8 倍),方案 B 降到約 0.5%(降幅約 79 倍)。注意一個反直覺之處——菌數減為 1/10,感染機率卻沒有同步減為 1/10。這是因為在高劑量區($P_{inf}$ 接近 1),曲線已飽和;只有把劑量壓到夠低,每減少一個對數值的菌量才能換來成比例的風險下降。這正是 HACCP 強調「在關鍵管制點做到足夠對數削減(log reduction)」的數學理由:減菌要減到曲線陡峭的那一段,才划算。試著想想:若這個病原改用 Beta-Poisson 模型且 $\alpha$ 很小(高異質性),同樣的減菌策略效果會更好還是更差?
重點回顧
- 微生物風險的數學和化學不同:病原會隨時間溫度增殖、且常假設無閾值(單顆即可能致病),因此不能套用 ADI 那一套,要用 QMRA。
- 預測微生物學用生長模型(Gompertz/Baranyi)與二級模型(Ratkowsky)描述菌數動態,且生長速率與 $(T-T_{min})^2$ 成正比——冷鏈中斷的危害是非線性放大的。
- 劑量—反應模型(指數、Beta-Poisson)把吃進的劑量轉成感染機率;模型給的是「感染」,要再乘條件機率才得到發病、住院、死亡。
- 二維蒙地卡羅刻意分開「變異性(世界的隨機)」與「不確定性(我們的無知)」,前者只能描述、後者可靠更多資料縮小,兩者導向不同的政策回應。
- 源頭歸因用 WGS 次分型、爆發外推或專家誘出,回答「全國的食源性疾病該歸因於哪些食物與病原」,餵進風險排序形成治理閉環。
深入探討(研究所視角)
1. 全基因體定序如何重寫整個監測與歸因典範。 過去十年,WGS 成本的崩跌讓食安監測從「表型分型(血清型、脈衝場電泳 PFGE)」全面轉向基因體流行病學(genomic epidemiology)。其關鍵指標是核心基因體多位點序列分型(cgMLST)與 SNP 距離:兩個分離株若僅差數個單核苷酸多型性(SNP),即可高度確信它們源自同一汙染事件,即使病例相隔數月、橫跨數國。這把「群聚定義」從流行病學的時空鄰近性,重構為演化樹上的親緣距離,使得過去無法偵測的「低度、長期、跨境」散發爆發得以現形。但它也帶來新的統計挑戰:多大的 SNP 距離才算「同源」並非固定值,而隨病原的突變速率與分析窗口而變,需要建立貝氏(Bayesian)框架的分子時鐘模型來校準,避免過度連結(over-linkage)造成的假性群聚。
2. 抗藥性的定量風險評估與 One Health 建模。 入門提到抗生素抗藥性(AMR)透過食物鏈流動,進階則要問:能不能把它量化?這是一個比病原 QMRA 更難的問題,因為要追蹤的不只是菌,還有抗藥基因(ARG)的水平基因轉移(horizontal gene transfer)——抗藥質體(plasmid)可在不同菌種間跳躍傳遞。新興的取徑是把總體基因體學(metagenomics)的 ARG 豐度資料,整合進 One Health 的傳輸動力學模型,估計「畜牧用藥量的變化,多久、以多大幅度反映到人類感染的抗藥比例」。這是一個橫跨獸醫、環境、人類醫學與演化生物學的耦合系統建模問題,也是 WHO 將 AMR 列為全球十大健康威脅後,食品安全研究最前沿的戰場之一。
3. 氣候變遷作為食品安全的長期驅動力。 多數 QMRA 假設環境參數穩定,但氣候變遷正在系統性改變這些假設。氣溫上升直接拉高沙門氏桿菌、弧菌(Vibrio)的生長速率與地理分布;海水暖化使原本侷限於熱帶的腸炎弧菌北擴;極端降雨增加農田逕流,把畜牧糞便中的病原沖入灌溉水與生鮮蔬果供應鏈。這要求風險評估從「靜態快照」走向情境化的動態建模,把氣候投影(climate projection)耦合進預測微生物學與暴露評估,估算未來數十年的食源性疾病負擔趨勢。這與 Educational Omics 強調的「環境維度(Environomics)」精神相通——脫離環境脈絡的風險評估,終究只是某個瞬間的近似。
4. 機器學習與全食物鏈數據整合的潛力與陷阱。 隨著供應鏈感測器、零售掃描、社群媒體症狀通報、基因體資料庫的累積,機器學習被寄望能即時預測爆發、追溯汙染源。已有研究用搜尋引擎查詢與電商評論偵測未通報的食物中毒。但這條路有兩個必須警惕的陷阱:其一,相關不等於因果——模型可能學到的是通報行為的偏差(哪些族群會上網抱怨),而非真實的疾病分布;其二,可解釋性與問責,當一個黑箱模型建議下架某批產品,造成的經濟損失需要科學上站得住腳的理由。因此食品安全領域的共識是:機器學習是強大的訊號偵測(signal detection)輔助,但風險的因果判定與管制決策,仍須回到 QMRA 與爆發調查那套可稽核、可被質疑的科學框架。這也再次呼應入門的核心命題——食品安全是一門融合自然科學、流行病學與社會決策的綜合工程,而非任何單一技術能獨力承擔。