
同樣是「發生率」,為什麼一篇追蹤五年、一篇追蹤十年的研究,數字不能直接比?
從 person-time、危險函數到目標試驗模擬與時變干擾,看流行病學如何在會流動的人群與會變動的暴露下,誠實估計因果效應。
同樣是「發生率」,為什麼一篇追蹤五年、一篇追蹤十年的研究,數字不能直接比?
你已經知道發生率(incidence)衡量「新發生」、盛行率(prevalence)衡量「現存」。但這裡有一個更尖銳的問題:一份世代研究(cohort study)追蹤一萬人五年、另一份追蹤一萬人十年,各自算出累積發生率(cumulative incidence),這兩個數字可以直接相比嗎?
答案是不行——除非把「時間」這個維度老老實實地放進分母。真實世界的世代從來不是一群人整整齊齊地進來、整整齊齊地觀察到底:有人中途搬家失聯、有人因別的原因死亡、有人較晚才被收案。每個人「暴露於風險之下」的時間長短不一。把他們當成相同的分母去除,本身就是一種偷懶。
這篇進階篇不再重述基礎,而是直接走進流行病學量化與因果推論真正吃功夫的地方:如何在「會流動的人群」與「會隨時間改變的暴露」之下,得到不會自欺欺人的估計。 我們會從 person-time(人時)與率(rate)出發,談到危險函數(hazard)、標準化(standardization),最後抵達當代流行病學最熱門的兩個關鍵字——目標試驗模擬(target trial emulation)與隨時間變動的干擾(time-varying confounding)。
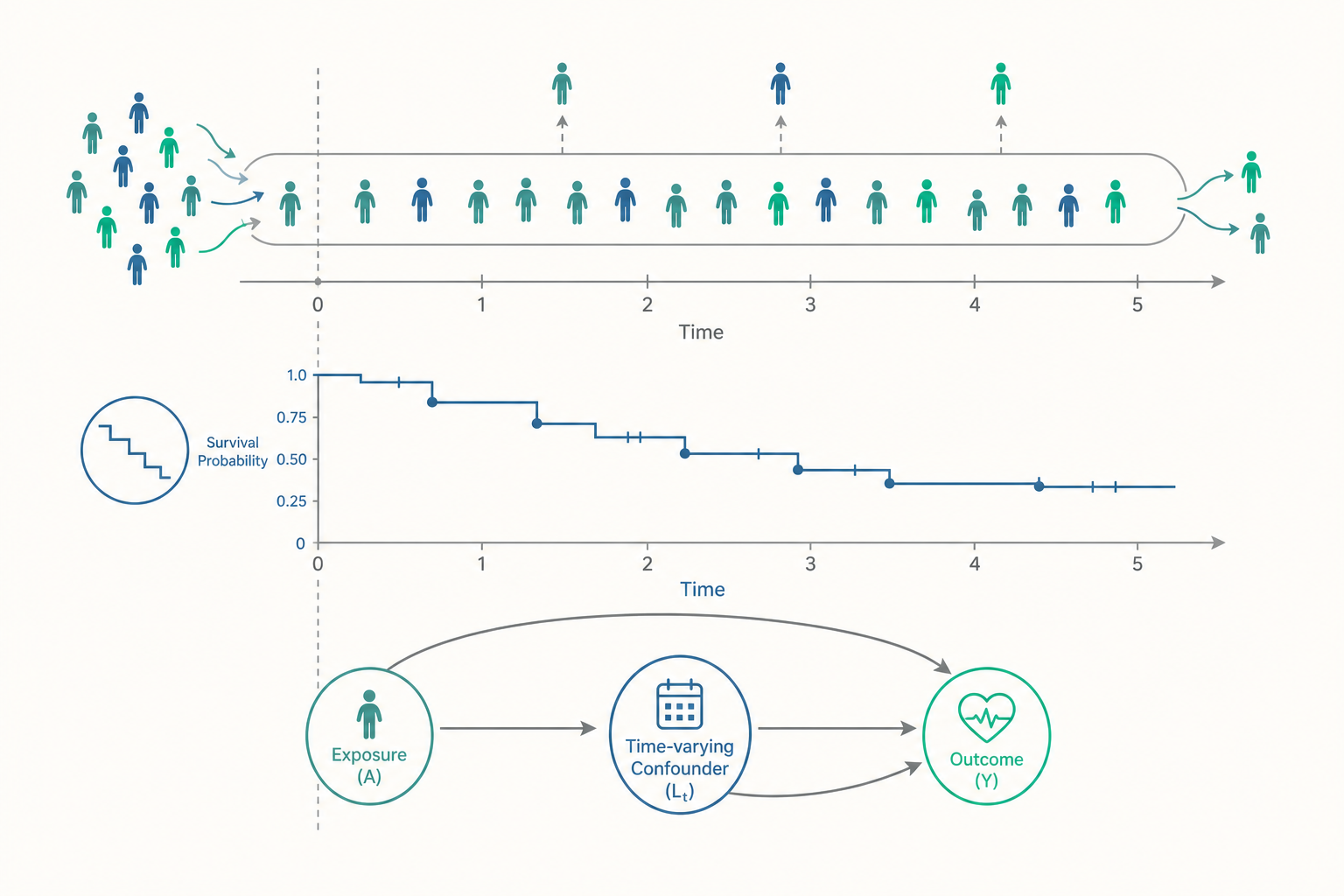
從「比例」到「率」:person-time 為什麼非用不可
入門時我們把累積發生率寫成「新病例數 ÷ 期初有風險人數」。這個寫法暗藏一個假設:所有人都被完整觀察到研究結束。一旦有人提早離開(censoring,設限),這個分母就名不副實。
解法是改用發生密度(incidence density),又稱發生率(incidence rate)。它的分母不是「人數」,而是「人時」(person-time)——把每個人實際被觀察、且仍處於風險中的時間全部加總:
$$\text{發生率} = \frac{\text{觀察期間新發病例數}}{\sum_{i} \text{個體 } i \text{ 的有風險時間}}$$
舉例:甲被追蹤 5 年都沒發病,貢獻 5 人年(person-years);乙在第 2 年發病,貢獻 2 人年(發病後就離開風險集合);丙在第 3 年因車禍死亡(與研究疾病無關)而設限,貢獻 3 人年。三人共貢獻 10 人年,其中 1 例發病,發生率即 0.1 / 人年,也就是「每 10 人年發生 1 例」。
person-time 的精神是:一個人被觀察十年,和十個人各被觀察一年,對分母的貢獻是等價的。 這讓不同長度、不同設限模式的研究有了共同的尺度。也因此你會在文獻中看到「每 1000 人年 X 例」這種寫法——它比裸的百分比更誠實。
但 person-time 也有它的隱含假設:它預設「風險在時間上大致恆定」,否則把早期低風險和晚期高風險的人年混在一起平均,會掩蓋真相。當風險明顯隨時間變化(如術後第一週死亡率遠高於第一年),就得改用下面更細緻的工具。
危險函數與存活分析:把「什麼時候發生」也納進來
率告訴你「平均多快」,但常常我們想知道「風險如何隨時間起伏」。這就進入存活分析(survival analysis)的領域,核心概念是危險函數(hazard function, $h(t)$):在已經存活到時間 $t$ 的條件下,「下一瞬間」發病的瞬時率。
$$h(t) = \lim_{\Delta t \to 0} \frac{P(t \le T < t + \Delta t \mid T \ge t)}{\Delta t}$$
別被符號嚇到,它的直覺很單純:hazard 是「給定你撐到現在,此刻的即時風險」。它可以隨時間升高(如老化相關疾病)、降低(如手術後逐漸康復),或先高後低(如新生兒死亡率)。
實務上最常見的呈現是 Kaplan-Meier 存活曲線——一條隨時間下降的階梯,每當有人發病就往下踏一階,妥善處理設限者(在其離開的時間點把他移出風險集合,但不算成事件)。而要比較兩組的存活差異並調整干擾,主力工具是 Cox 比例危險模型(Cox proportional hazards model):
$$h(t \mid X) = h_0(t) \cdot \exp(\beta_1 X_1 + \beta_2 X_2 + \cdots)$$
它的巧妙在於不必假設基準危險 $h_0(t)$ 長什麼形狀(semi-parametric,半參數),只估計各暴露的相對效果,輸出危險比(hazard ratio, HR)。HR = 2 代表暴露組在任一時點的瞬時風險是對照組的兩倍。
這裡要點出一個常被誤讀的地方:HR 不等於 RR,更不等於「整段期間風險翻倍」。 HR 是瞬時、條件式的比值,且 Cox 模型預設「比例危險假設」(proportional hazards,兩組 hazard 的比值不隨時間變)。若兩條存活曲線中途交叉(例如某療法早期傷身、晚期得利),比例危險假設就破裂,硬報一個 HR 會掩蓋掉「效果隨時間反轉」這個最重要的訊息。看到 HR,永遠該追問:曲線長什麼樣?
標準化:當兩個人群「年齡結構不同」就不能直接比
族群層次的比較有個古老但致命的陷阱。假設 A 國的粗死亡率(crude death rate)高於 B 國,能說 A 國人比較不健康嗎?不能——如果 A 國是高齡社會、B 國是年輕移民國家,那麼 A 國死得多,可能純粹因為老人多,而非每個年齡層的死亡風險真的較高。年齡是這裡典型的干擾因子。
標準化(standardization)就是為了拆掉這個干擾。它分兩種:
- 直接標準化(direct standardization):把兩國「各年齡層的死亡率」套用到同一個「標準人口」的年齡結構上,算出假設兩國年齡分布相同時的死亡率。這樣比較才公平。得到的數字稱為年齡標準化死亡率(age-standardized rate)。
- 間接標準化(indirect standardization):當研究人群分層後人數太少、各層率不穩時,反過來把「標準人口的各層率」套到研究人群的結構上,算出「期望事件數」,再用實際 ÷ 期望得到標準化死亡比(standardized mortality ratio, SMR)。SMR = 1.3 代表該人群死亡數比同年齡結構下的標準人口高三成。
標準化的意義遠超過技術細節:它是一個提醒——任何跨人群、跨時代的健康比較,都必須先問「人口結構可比嗎」。 媒體上「某縣癌症死亡率全國最高」的標題,若沒做年齡標準化,很可能只是反映了那個縣的人口老化,而非環境或醫療出了問題。
看一個例子:粗率騙了你
| 年齡層 | A 國人口 | A 國死亡 | A 國分層率 | B 國人口 | B 國死亡 | B 國分層率 |
|---|---|---|---|---|---|---|
| 年輕(<50) | 2,000 | 10 | 0.5% | 8,000 | 48 | 0.6% |
| 年長(≥50) | 8,000 | 720 | 9.0% | 2,000 | 200 | 10.0% |
| 合計 | 10,000 | 730 | 7.3% | 10,000 | 248 | 2.5% |
乍看 A 國粗死亡率 7.3%、B 國僅 2.5%,A 國像是健康災區。但逐層看:在每一個年齡層,A 國的死亡率其實都比 B 國低(0.5% < 0.6%,9.0% < 10.0%)。差別純粹來自 A 國老人佔八成、B 國老人僅佔兩成。
現在做直接標準化。取一個各佔 50% 的標準人口:
- A 國標準化率 = 0.5×0.5% + 0.5×9.0% = 4.75%
- B 國標準化率 = 0.5×0.6% + 0.5×10.0% = 5.30%
結論完全翻轉:扣掉年齡結構的干擾,A 國反而比 B 國健康。這正是入門篇講的「干擾」在族群層次最具體的呈現,也是辛普森悖論(Simpson's paradox)的一個版本——未調整與調整後的方向相反。每一次看到「粗率」,都該警惕背後的人口結構。
目標試驗模擬:把觀察性研究「假裝成」一場 RCT
入門篇說過,RCT 是因果證據力最強的設計,但許多暴露因倫理或可行性無法隨機分配。當代流行病學近十年最有影響力的思想,是 Miguel Hernán 等人推動的目標試驗模擬(target trial emulation)框架:與其把觀察性資料當成「次等品」隨意分析,不如先明確寫下「如果能做一場理想的隨機試驗,它的方案(protocol)長什麼樣」,再用觀察性資料盡力去模擬這個目標試驗的每一個成分。
這個框架要求研究者一開始就講清楚:合格條件(eligibility)、處理策略(treatment strategies)、分派時點(assignment)、結果定義(outcome)、追蹤起點與終點、以及最關鍵的——「時間零點」(time zero):合格、分派、開始追蹤這三件事必須對齊在同一刻。
為什麼這麼斤斤計較時間零點?因為它直接堵住一個臭名昭著的偏誤——不死時間偏誤(immortal time bias)。
考慮一個真實出現過的錯誤分析:「有領藥的病人比沒領藥的活得久,所以這個藥有效。」聽起來合理,但藏著陷阱:一個人要「能領到藥」,前提是他至少得活到去領藥的那天。換句話說,從追蹤起點到他領藥之間那段時間,他「註定不會死」(否則就被歸到沒領藥組了),這段被錯誤算給用藥組的時間就是「不死時間」(immortal time)。它人為地讓用藥組看起來更長壽,純屬統計假象,與藥效無關。
目標試驗框架透過「強制時間零點對齊」直接消解這個偏誤——在 time zero 當下就依當時的處理策略分組,不容許用「未來才發生的事」(如後來有沒有領藥)回頭定義組別。這個看似哲學的紀律,救回了無數會誤導政策的錯誤結論。
隨時間變動的干擾:當「調整」反而出錯
現在進入這篇文章的最深處,也是入門篇完全沒碰的領域。
入門篇教過:遇到干擾因子就「調整」它(迴歸放進去、分層、配對)。這在干擾固定不變時是對的。但如果暴露和干擾因子會隨時間互相影響,傳統調整法會徹底失靈。
舉醫學上的經典情境:研究抗病毒藥(暴露)對愛滋病患存活(結果)的效果。病人的 CD4 免疫指數是一個棘手變項——
- CD4 低(病情重)會促使醫師開更多藥 → CD4 是用藥的干擾因子(影響暴露)。
- 但用藥又會反過來改善後續的 CD4 → CD4 也在用藥與存活之間的因果路徑上(是中介,mediator)。
於是 CD4 同時是「干擾」又是「中介」(術語稱 time-varying confounder affected by prior treatment,受先前處理影響的時變干擾)。這時你陷入兩難:
- 若用標準迴歸把 CD4 放進去調整 → 你擋掉了「用藥→改善 CD4→延長存活」這條真實的有益路徑,低估了藥效(過度調整中介)。
- 若不調整 CD4 → 又留下「病重的人本來就容易死、也剛好被多開藥」的干擾,造成假象。
兩條路都錯。出路是 James Robins 提出的 g-methods(g-formula、邊際結構模型 marginal structural model、g-estimation)。其中最常用的邊際結構模型(marginal structural model, MSM)採用一個漂亮的構想——逆機率加權(inverse probability weighting, IPW):
不去「調整」CD4,而是依「在當下的 CD4 等變項下,這個人實際接受該處理的機率」給每個人一個權重,機率越低的觀察給越大的權重。這等於用統計手法重建一個假想的人群,在這個人群裡,CD4 不再決定用不用藥(就像隨機分配那樣),於是干擾被斷開,而中介路徑卻完整保留。MSM 估出來的,就逼近「若全體都用藥 vs 全體都不用藥」的因果對比。
這個轉折的深意值得停下來體會:「把變項丟進迴歸調整」不是萬靈丹,在時變情境下甚至會引入偏誤。 該調整什麼、用什麼方法調整,取決於你對因果結構(最好用 DAG 畫出來)的判斷,而不是「能放就放」。這也呼應入門篇結尾提到的對撞因子偏誤——它們都在說同一件事:因果推論的前提是因果假設,統計只是執行假設的工具。
動手試試:替一則研究找出時間結構的破綻
下次讀到觀察性研究的因果宣稱,除了入門篇教的「設計?干擾?相對還是絕對風險?」,再加三個進階提問:
- 時間零點對齊了嗎? 分組的依據,會不會用到「追蹤開始之後才發生的事」?若會,當心不死時間偏誤。例如「完成整個療程的人活得久」——能完成療程本身就需要先活著。
- 干擾因子是固定的,還是會隨時間和暴露互動的? 如果暴露會改變後續的某個變項,而那個變項又影響下一步的暴露與最終結果,標準迴歸可能不夠,要看作者有沒有用 g-methods 或 IPW。
- 報的是 HR 嗎?比例危險假設站得住嗎? 有沒有附存活曲線?兩條線會不會交叉?
能問出這三題,你對流行病學證據的鑑別力,已經跨進研究所的門檻了。
重點回顧
- person-time(人時)讓會流動、會設限的人群有了公平的分母;發生密度比裸百分比誠實,但預設風險在時間上大致恆定。
- 存活分析以危險函數刻畫「風險隨時間的起伏」;Cox 模型輸出的 HR 是瞬時條件比值,預設比例危險,看到 HR 要追問存活曲線會不會交叉。
- 標準化是族群比較的前提:粗率會被人口結構(尤其年齡)這個干擾誤導,未標準化的跨人群健康排名常不可信,辛普森悖論可能讓方向整個翻轉。
- 目標試驗模擬要求對齊「時間零點」,從源頭堵住不死時間偏誤——別讓「未來才發生的事」回頭定義組別。
- 時變干擾下「把變項丟進迴歸」會出錯:當干擾同時是中介時,需用 g-methods/逆機率加權(MSM),而非盲目調整。
深入探討(研究所視角)
把上述線索收束起來,研究所層次的流行病學其實在追問一個統一的問題:如何讓觀察性資料合法地承載「介入」(intervention)的語意。
估計目標(estimand)優先於估計方法。 當代方法論(受 ICH E9(R1) addendum 與 Hernán–Robins 教科書影響)強調:動手算之前,先把「你到底想估什麼因果量」用反事實語言定義清楚——是平均處理效應(ATE)、處理組的處理效應(ATT),還是某種動態處理策略(dynamic treatment regime,「CD4 跌破某閾值才開始用藥」)的效果?許多文獻爭議,根源不在統計方法錯,而在不同研究偷偷估了不同的 estimand 卻拿來互比。先講清楚 estimand,方法的選擇(IPW、g-formula、g-estimation、TMLE)才有意義。
g-methods 三件套與雙重穩健。 Robins 的三種 g-methods 各有適用面:參數式 g-formula 直接對結果建模並沿時間遞迴積分,效率高但對模型設定敏感;MSM + IPW 對處理機制建模,直覺強但極端權重會使變異數爆炸(需 stabilized weights 與 truncation);g-estimation 適合結構巢狀模型。近年主流是雙重穩健估計(doubly robust estimation),如 TMLE(targeted maximum likelihood estimation)與 AIPW:只要「結果模型」或「處理模型」其中之一設定正確,估計就一致——這給了高維、易設定錯誤的真實資料一層保險,並讓因果機器學習(以 super learner 等彈性演算法估計干擾參數,再做一步 targeting 修正)得以在保有有效推論(valid inference)的前提下登場。
可遷移性與外部效度。 即使內部效度(internal validity)無懈可擊,研究結論能否遷移到另一個人群(transportability)是另一道關卡。同樣的處理效應在不同人群可能因效應修飾因子分布不同而改變,因果結構的可遷移性理論(Pearl 與 Bareinboim 的 selection diagram)正試圖形式化「什麼條件下、要重加權哪些變項,一個人群的因果結論才能搬到另一個人群」。這對台灣這類「研究多半引用歐美世代資料」的處境格外切身——一個在白人世代估出的 HR,未必能原封不動套到本地族群。
回到一張會流動的人群圖。 從入門篇斯諾標滿黑點的靜態地圖,到這篇隨時間流動、暴露與干擾互相纏繞的動態人群,流行病學量化的歷史,是一部不斷把「時間」與「反事實」逼進方程式的歷史。person-time 把時間放進分母,存活分析把時間放進風險,目標試驗把時間零點釘死,g-methods 把時間變動的干擾拆解——每一步都在回答同一個古老而謙卑的問題:面對一群會變化的人,我們究竟能不能、以及如何,誠實地說出「做這件事會有什麼後果」? 這既是流行病學的方法論前沿,也是它作為「為了行動而求真」之科學的終極承諾。