
如果「準備好了」可以被打分,這個分數為什麼救不了 COVID-19?
從 JEE、SPAR、GHSI 等整備量化框架,到排隊理論下的醫療崩潰、Rₜ 即時儀表、封城效果的反事實難題與稀缺資源分配倫理,拆解整備科學的內部機制與極限。
如果「準備好了」可以被打分,這個分數為什麼救不了 COVID-19?
2019 年底,一份名為「全球衛生安全指數」(Global Health Security Index, GHSI)的評比正式發布。它由約翰霍普金斯大學、核威脅倡議組織(NTI)與經濟學人智庫合作,用 140 多項指標為全球 195 個國家的大流行整備程度評分。排名第一的是美國,第二是英國——兩個在隨後一年裡,COVID-19 死亡率名列前茅的高所得國家。
這個刺眼的落差,把一個進階的問題推到我們面前:整備(preparedness)究竟能不能被測量?如果能,為什麼測出來「最有準備」的國家,實戰表現卻如此糟糕? 入門篇談過減災、整備、應變、復原的四階段循環,也談過脆弱度與韌性的直覺。這一篇,我們不再停留在「該做哪些事」,而要走進整備科學的內部——看它如何被量化、被建模、被評估,又在哪裡撞上了它自身的極限。對已經理解基本框架的你,真正有趣的問題不是「準備什麼」,而是:我們怎麼知道自己準備得夠不夠?而這個「知道」,本身可靠嗎?
把整備「打分」:JEE、SPAR 與指數的承諾與陷阱
要管理整備,先得測量整備。過去十餘年,全球衛生治理發展出好幾套量化框架,試圖把「一個國家準備得如何」變成可比較的分數。
- 聯合外部評估(Joint External Evaluation, JEE):在《國際衛生條例》(IHR)架構下,由外部專家團隊到一國實地評估其偵測、通報、應變等核心量能,針對如監測、實驗室、人力資源、風險溝通等十餘個技術領域逐項評分(通常 1 到 5 分)。它的特點是外部、同儕、半透明。
- 國家自評年報(State Party Self-Assessment Annual Reporting, SPAR):各國每年自行向 WHO 申報 IHR 核心量能的達成度。優點是涵蓋率高、年年更新;缺點是自評——分數來自被評者自己。
- 全球衛生安全指數(GHSI):學術機構主導的綜合指數,資料來源以公開文件與政策存在與否為主。
這些工具確實有用:它們讓「整備」從模糊的形容詞變成可追蹤的數列,讓資源不足的國家能指認自己的缺口,也讓國際援助有了瞄準的依據。但 COVID-19 給了它們一記響亮的耳光,也教給整備科學三個深刻的教訓。
第一,「紙面量能」不等於「實戰量能」。多數指標衡量的是「制度、計畫、文件是否存在」(capacity on paper),而非「危機當下這些制度是否真的被啟動、被遵循、被有效執行」(capacity in action)。一份寫得完美的大流行應變計畫,若從未演練、政治領導不願啟動,分數很高卻毫無作用。
第二,指標漏掉了最關鍵的軟變項。政治意志、社會信任、領導決斷、治理品質——這些在 COVID-19 中被反覆證明攸關存亡的因素,極難被標準化問卷捕捉。一個高分國家若在關鍵數週裡因政治考量而猶豫、因不信任而政策反覆,再好的硬體量能也會空轉。
第三,整備是動態的,分數是靜態的。GHSI 是 2019 年的快照,但量能會折舊:演練荒廢、物資過期、人員流動、機構記憶流失。整備不是一次達標的狀態,而是必須持續維護的過程——這也是 SARS、H1N1 之後許多國家「學到又忘記」的循環。
所以,正確看待這些指數的方式不是「分數高就安全」,而是把它們當成體檢報告而非保證書:它能指出明顯的結構缺口,卻無法預測一個社會在真正的壓力下會如何反應。整備測量學自身,正是緊急應變最前沿的方法學戰場之一。
量能的數學:surge capacity 為什麼是一道排隊問題
入門篇提過「量能的可擴張性」(surge capacity),但進階地看,量能崩潰其實是一個可以用數學描述的現象——而理解這個數學,能解釋為什麼「醫療擠兌」會如此突然、如此致命。
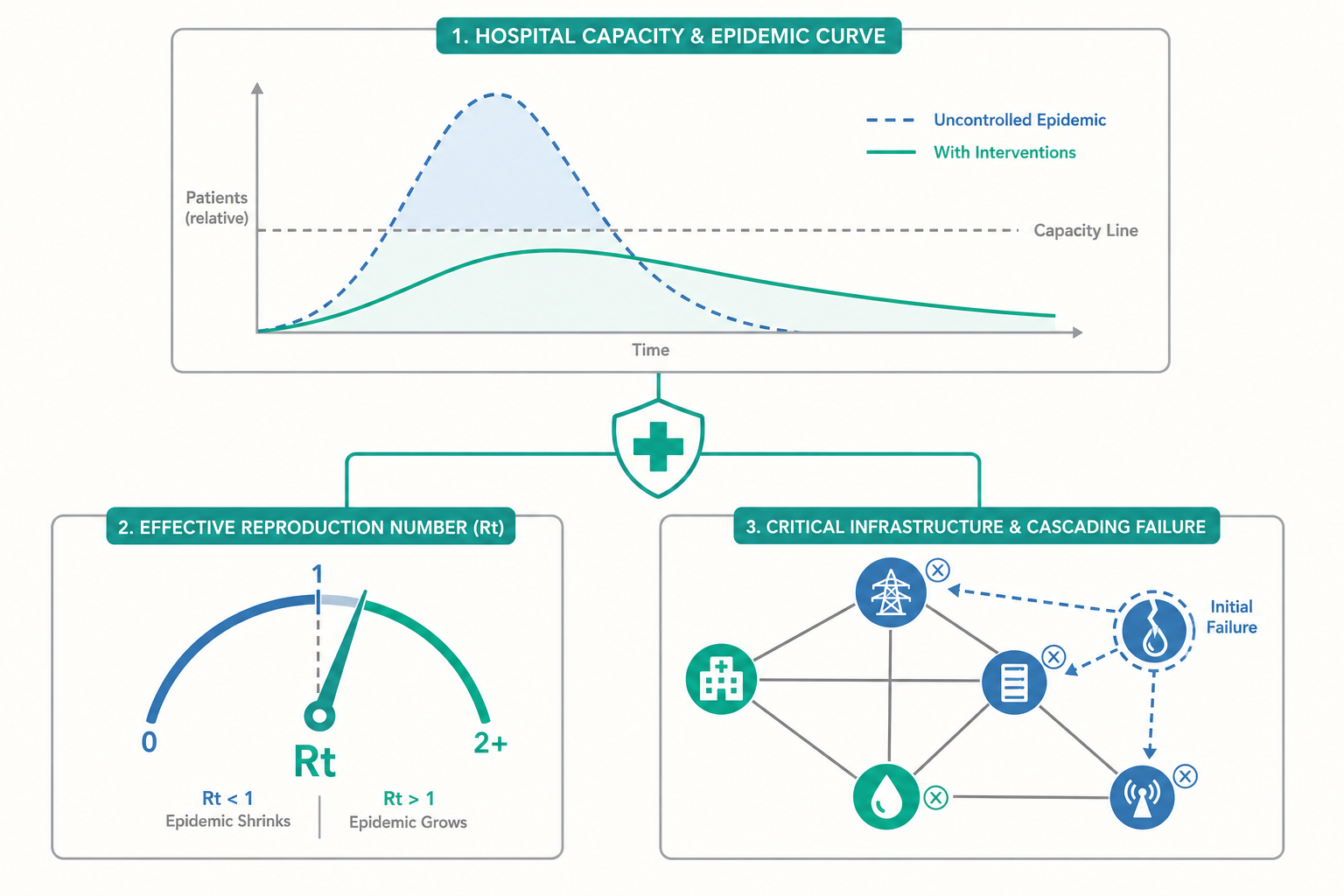
把醫院想像成一個排隊系統(queueing system):病人是「到達的顧客」,加護病房床位是「服務窗口」,住院天數是「服務時間」。排隊理論有一個反直覺卻關鍵的結論:當系統使用率(utilization)逼近 100% 時,等候時間不是線性上升,而是趨近無限地爆炸性上升。 一家平時使用率 85% 的加護病房,看起來「還有餘裕」,但只要疫情讓到達率小幅增加,使用率推到 95%、98%,平均等候時間會以非線性的方式急遽惡化——這就是為什麼醫療崩潰往往不是緩緩逼近,而是在某個臨界點上「突然」發生。
這個視角也重新詮釋了入門篇的「壓平曲線」(flatten the curve)。壓平曲線的本質,正是把「病人到達率」的峰值壓低,使它不要超過「服務量能」這條水平線。曲線下的總面積(總感染數)可能變化不大,但只要峰值被壓在量能線以下,系統就維持在排隊理論的「穩定區」,而非「爆炸區」。同樣的感染總數,分散在較長時間,與集中在短時間爆發,對死亡率的影響可能天差地別——因為後者會把系統推過那個非線性的臨界點。
量能的擴張,公衛實務上常用一個分層框架來思考,這也是「危機照護標準」(crisis standards of care)的基礎:
- 常規照護(conventional):用平時的空間、人力、物資處理增加的需求(例如延後非緊急手術、騰出床位)。
- 應急照護(contingency):開始做功能等價的替代(用恢復室當加護病房、調用其他科別人力、延長輪班)。照護品質仍力求等同常規。
- 危機照護(crisis):需求遠超量能,被迫接受次佳的照護標準(一台呼吸器多人輪用、放寬人力對病人的比例)。此時照護目標從「為每個病人爭取最好結果」轉向「為整個族群爭取最多存活」。
從常規滑向危機的過程,正是排隊系統從穩定區滑入爆炸區的臨床對應。理解這個數學,我們才會明白:surge capacity 的真正價值,不只是「多備幾張床」,而是把臨界點往後推、為其他介入(檢驗、匡列、壓平曲線)爭取時間,避免系統踩過那個不可逆的非線性懸崖。
用數字看傳播:R₀、Rₜ 與整備決策的即時儀表板
緊急應變要「即時」決策,需要一個能反映「疫情此刻在加速還是減速」的儀表板。流行病學提供的核心儀表,是再生數(reproduction number)。
基本再生數(basic reproduction number, $R_0$) 是在一個完全沒有免疫、沒有任何介入的族群中,一個感染者平均會傳染給幾個人。$R_0 > 1$,疫情會指數成長;$R_0 < 1$,會自然衰退。但 $R_0$ 是個「理論初始值」,對正在進行的應變幫助有限——因為現實中族群會逐漸產生免疫、人們會改變行為、政府會介入。
真正驅動即時決策的,是有效再生數(effective reproduction number, $R_t$):在「此時此刻、考慮了既有免疫與所有介入之後」,一個感染者實際傳給幾個人。$R_t$ 是應變的核心儀表——
- $R_t > 1$:疫情仍在擴大,介入力道不足。
- $R_t \approx 1$:疫情持平,處於微妙的平衡。
- $R_t < 1$:疫情正在收縮,介入正在生效。
把 $R_t$ 持續壓到 1 以下並維持住,是幾乎所有圍堵策略的共同目標。 而 $R_0$ 還帶出另一個整備上的關鍵數字——群體免疫門檻(herd immunity threshold)。當族群中具免疫力的比例夠高,連鎖傳播就會自然斷裂。這個門檻的概念可用一個簡潔的關係表達:免疫人口比例需達到約 $1 - 1/R_0$。代入數字會很有感覺:若某病原 $R_0 = 3$,門檻約為 $1 - 1/3 \approx 67\%$;若傳播力更強、$R_0 = 6$,門檻飆到約 $83\%$。這個簡單算式直接決定了疫苗接種的整備目標——傳播力越強的病原,需要越高的接種覆蓋率才擋得住,留給「猶豫」與「破口」的空間就越小。
但這裡有個進階的細節,常被忽略:$R_t$ 從來不是「即時」可知的。一個今天被通報的病例,其實是好幾天前被感染的;估計 $R_t$ 必須回推「世代間隔」(generation interval,從一個人被感染到他傳染給下一個人的時間)與通報延遲。這意味著我們看到的 $R_t$,永遠是過去式——當你確認 $R_t$ 已經超過 1,疫情可能已經默默加速了一兩個潛伏世代。這個「永遠落後於真相」的時滯(lag),正是緊急應變必須「寧可早動、不可等到確定」的數理理由。
看一個例子:同樣 R₀,不同整備,截然不同的命運
設想兩個族群,面對同一種 $R_0 = 2.5$ 的新興呼吸道病原。
X 族群有靈敏的監測與快速反應量能。在病例數仍是兩位數時,它就估出 $R_t$ 約為 2.4(接近 $R_0$,因為幾乎還沒有免疫與介入),立即啟動匡列、檢驗擴張與早期的非藥物介入。一兩週後,$R_t$ 被壓到 0.8——疫情開始收縮。整個過程中,每日新增病例始終遠低於醫療量能,醫院維持在排隊理論的穩定區,照護標準停留在「常規」層級。
Y 族群監測遲鈍,等到醫院急診開始爆滿才警覺。此時通報病例雖是數百,但因為前述的時滯,真實感染者可能已是數千;估出來的 $R_t$ 仍在 2 以上。介入啟動得太晚,疫情已衝過量能線:加護病房使用率從 90% 在數日內飆破 100%,照護標準被迫滑入「危機」層級,開始出現呼吸器分配的倫理抉擇。間接死亡(心肌梗塞、車禍重傷者因無床可收而延誤)開始累積。
兩個族群的 $R_0$ 完全相同,病毒也一樣。決定命運的,是X 族群在 $R_t$ 還來得及被壓下時就動手,把感染曲線的峰值穩穩壓在量能線之下。請注意這個因果鏈如何串起前幾節:靈敏監測(縮短時滯)→ 早期估出高 $R_t$ → 及時介入把 $R_t$ 壓到 1 以下 → 峰值低於量能、系統留在排隊穩定區 → 照護標準不滑入危機層級 → 間接死亡被避免。每一環都是量化的,每一環的失守都會被下一環放大。
「封城救了多少人」:反事實為何如此難證
緊急應變最尖銳的進階爭論之一是:那些代價高昂的非藥物介入(封城、停課、口罩令),究竟有沒有效、效果有多大?這看似實證問題,卻是因果推論(causal inference)最棘手的戰場。
困難的根源是反事實(counterfactual)無法觀察。我們看得到「實施了封城、然後疫情下降」,卻永遠看不到「同一個社會若沒封城會怎樣」——而後者才是評估效果真正需要的對照。把這道難題拆開,至少有四重糾纏:
- 同時介入難以拆分:封城、口罩令、停課、邊境管制常在同一週內一起上路,統計上幾乎無法分離各自的獨立貢獻(共線性,collinearity)。
- 自發行為改變的干擾:即使政府什麼都不做,民眾看到疫情惡化也會自己減少外出。把這部分「自發降載」誤算成政策效果,會嚴重高估介入的作用。
- 反向因果與內生性:政府往往是「因為疫情變嚴重才封城」,而非隨機決定。這使得「介入」與「疫情嚴重度」互為因果,違反了單純前後比較的前提。
- 測量本身在變動:檢驗量能、通報定義、篩檢策略在疫情中不斷改變,使得「病例數下降」可能部分是「驗得少了」而非「真的少了」。
正因如此,學界發展出較嚴謹的準實驗(quasi-experimental)方法來逼近因果——例如比較「政策時點不同的鄰近地區」(差異中之差異,difference-in-differences)、利用政策門檻的不連續(斷點回歸)、或以數理模型建構反事實情境。但這些方法各有假設,沒有一種能完全消除上述偏誤。結果就是:「封城究竟救了多少人」這個問題,在頂尖期刊上至今沒有單一定論,估計值跨越很大的區間。
這對整備科學的啟示,不是「介入無用」,而是更謙遜的態度:在深度不確定下,我們很難在事中精確知道每一項措施的效益與代價,因此決策必須建立在「穩健」而非「精準」之上——選擇在多種可能真相下都不至於釀成大錯的策略,並隨著證據更新而調整。把「我們其實不完全知道」這件事誠實納入決策與溝通,本身就是成熟整備的一部分。
當量能耗盡:稀缺資源分配的演算法與倫理
當排隊系統徹底崩潰、照護標準滑入「危機」層級,緊急應變會逼出公共衛生最不願面對、卻必須事先準備的問題:當救命資源不夠分給所有人,該怎麼分?
這不是可以臨場即興的決定。一個負責任的整備體系,會在平時就制定透明、可問責的稀缺資源分配協定(crisis triage protocol),原因有三:臨場決策易受情緒與偏見扭曲;事先公開的規則能減輕第一線人員的道德創傷(不必獨自承擔「選誰」);透明的標準也是社會信任的基礎。
但「怎麼分才對」沒有純技術的答案,因為它牽動彼此衝突的倫理原則:
- 效益最大化(救最多的人 / 救最多的生命年):傾向把資源給最可能存活、預期能活最久的人。爭議在於它可能系統性地不利於高齡者與慢性病患。
- 平等(人人機會均等):以抽籤或先到先得處理同等病況者,避免用「社會價值」評斷生命。爭議在於可能造成可避免的死亡。
- 優先照顧最弱勢(priority to the worst-off):把資源給病情最重或最弱勢者。爭議在於可能把資源投入存活機會渺茫的人。
- 工具價值(instrumental value):在大流行中,醫護人員可能被適度優先——不是因為他們命更貴,而是救回他們能讓更多人獲救。
真實的危機照護協定,通常是這些原則的加權混合,並刻意設計多項程序保障:明確排除種族、財富、身分等不相關因素;用客觀的臨床評分而非主觀印象;設立獨立的檢傷團隊(讓做決定的人與照顧病人的人分開,減輕利益衝突與情緒負荷);並建立爭議的覆核機制。
更宏觀地看,這個分配難題會從病床放大到全球。COVID-19 的「疫苗民族主義」本質上是同一個問題的國際版:當疫苗稀缺,是該按各國「先搶先贏」,還是按全球需要(最脆弱族群、醫護優先)公平分配?這把緊急應變從醫院推向全球治理,也說明了為什麼整備的倫理框架必須在平時就辯論清楚——等到資源耗盡那天才吵,往往已經來不及,也最不公正。
重點回顧
- 整備可以被測量,但分數不等於安全:JEE、SPAR、GHSI 等框架能指出結構缺口,卻測不出政治意志、社會信任與「紙面量能 vs 實戰量能」的落差——COVID-19 中高分國家的失利就是明證。整備是須持續維護的動態過程,不是一次達標的狀態。
- 醫療崩潰是一道排隊問題:當使用率逼近 100%,等候時間非線性爆炸;壓平曲線的本質是把感染峰值壓在量能線下,讓系統留在排隊理論的穩定區,避免踩過不可逆的臨界點。
- $R_t$ 是應變的即時儀表,但永遠是過去式:把 $R_t$ 壓到 1 以下並維持是圍堵的共同目標;群體免疫門檻約為 $1 - 1/R_0$,傳播力越強所需覆蓋率越高。時滯使我們看到的疫情永遠落後於真相,這正是「寧可早動」的數理理由。
- 介入的因果效應極難證明:同時介入、自發行為改變、反向因果與測量變動,使「封城救了多少人」至今無定論。對策不是放棄評估,而是改採穩健決策——在多種可能真相下都不至於釀大錯。
- 稀缺資源分配必須事先、透明、可問責地準備:危機檢傷協定混合效益、平等、扶弱與工具價值等衝突原則,並以程序保障(獨立檢傷團隊、排除不相關因素)守住公正;疫苗民族主義是同一難題的全球版。
深入探討(研究所視角)
進階到研究層次,緊急應變的前沿問題,幾乎都圍繞著一個張力打轉:我們用越來越精密的量化工具去逼近一個本質上深度不確定、且充滿價值衝突的對象,這份「精密」究竟帶來了真知識,還是帶來了虛假的確定感?
測量的反身性與古德哈特定律。 當整備被指數化、被排名,被測量的對象就會開始「為分數而最佳化」——這正是古德哈特定律(Goodhart's law):「當一個測量變成目標,它就不再是好的測量。」國家可能投資於「容易得分」的項目(寫計畫、建文件)而非「真正有用卻難以量化」的能力(演練的紮實度、跨部會的協調默契、領導層的決斷文化)。整備測量學的研究前沿,正在於設計抗操弄、能捕捉動態與軟變項、且能驗證「實戰量能」的指標——例如以情境演練的實測表現、而非紙面存在與否來評分。GHSI 在 COVID-19 後的修訂,正是這場方法學反省的產物。
模型的認識論地位:決策支援還是預測工具? SIR/SEIR 倉室模型、個體基礎模型(agent-based models)、接觸網絡模型在大流行中扮演核心角色,但研究社群對它們的「定位」有深刻辯論。把模型當成精確預測(明天會有幾例)往往令人失望——參數不確定、行為內生、結構假設脆弱,使長期點預測極不可靠。較成熟的立場是把模型當成結構化推理與情境比較的工具:它的價值不在於告訴我們「會發生什麼」,而在於釐清「在不同假設下,不同介入會把系統推向哪個方向」。這也帶出集成預測(ensemble forecasting) 與不確定性量化(uncertainty quantification) 的方法論——與其相信單一模型,不如整合多個模型並如實呈現預測的不確定區間。「所有模型都是錯的,但有些是有用的」這句統計學箴言,在大流行決策中有了生死攸關的份量。
級聯失效與關鍵基礎設施的系統科學。 入門篇點到了「醫療擠兌」是系統性崩潰;研究層次則用複雜系統與網絡科學的工具來剖析它。關鍵基礎設施——電力、供水、通訊、醫療、物流——彼此高度耦合,形成「網絡的網絡」(network of networks)。一個節點的失效可能透過相依關係級聯(cascade) 到整個系統:停電癱瘓供水,供水中斷迫使醫院撤離,醫院撤離壓垮鄰近院所。這類研究借用滲流理論(percolation)、網絡韌性與相變(phase transition)的數學,試圖辨識系統中的「關鍵節點」與「臨界閾值」,並設計冗餘(redundancy)與去耦(decoupling)以阻斷級聯。緊急整備因而從「備物資」升級為「設計能在局部失效下仍維持核心功能的韌性系統架構」。
深度不確定下的決策與整備的政治經濟學。 緊急整備的終極難題,在決策理論上屬於深度不確定(deep uncertainty) ——我們連事件的機率分布都無法可靠估計。傳統的期望值最佳化在此失靈,因為它需要可靠的機率,且系統性低估極端事件的尾部風險(tail risk)。前沿因而轉向穩健決策(robust decision making)、「不後悔策略」與「真實選項」(real options)的思維:投資於保留未來彈性的能力(可快速擴張的量能、可重新部署的人力、模組化的協定),而非賭單一最可能情境。但所有技術方法的背後,都有一個更難的政治經濟學問題:整備是一種典型的「隱形公共財」——它做得最成功時,成果恰恰是「什麼都沒發生」,而沒有發生的災難無法被看見、被計票、被感激。這造成系統性的投資不足與「恐慌—遺忘循環」(panic-neglect cycle):疫情當下大量投入,承平之後迅速荒廢。緊急應變研究最深層的課題,或許不是技術上的「如何準備」,而是制度設計上的——如何讓一個短視的政治週期,願意持續為一場看不見回報的災難買單。這需要把整備的價值「可視化」(例如以避免的損失、保險精算的尾部風險來呈現)、把它制度化為不隨政治更迭而中斷的常設量能,並在文化上重建對「為最壞做準備」這件事的集體記憶。