
如果把全台灣的菸全部戒掉,到底能少死多少人?——一個比「相對風險」更難回答的問題
深入慢性病次段預防的量化核心:族群歸因分數、篩檢三大偏誤、過度診斷,以及風險預測模型如何把預防變成需要校準的精算學。
如果把全台灣的菸全部戒掉,到底能少死多少人?——一個比「相對風險」更難回答的問題
入門篇你已經學會用相對危險(relative risk, RR)與歸因危險度(attributable risk, AR)描述「吸菸者個人」承擔多少額外風險。但公共衛生決策者真正想知道的,往往是另一個尺度更大的問題:「如果整個族群都不再暴露於某危險因子,整體疾病負擔會下降幾成?」 這不是把個人的 RR 直接乘起來就能回答的——因為一個族群裡,暴露的人只佔一部分,而政策的效益取決於「風險有多強」與「暴露有多普遍」這兩件事的相乘。
更棘手的是,當我們從「移除危險因子」轉向「靠篩檢早期發現」這條次段預防路線時,數字會變得詭異到反直覺:有些篩檢明明讓病人「活得更久」,卻可能一條命也沒救到。這篇進階篇不重述自然史與三段五級預防,而是直接走進慢性病預防真正吃功夫的量化核心——族群歸因分數(population attributable fraction)、篩檢的三大偏誤、過度診斷(overdiagnosis),以及風險預測模型如何把「預防」變成一門需要校準的精算學。
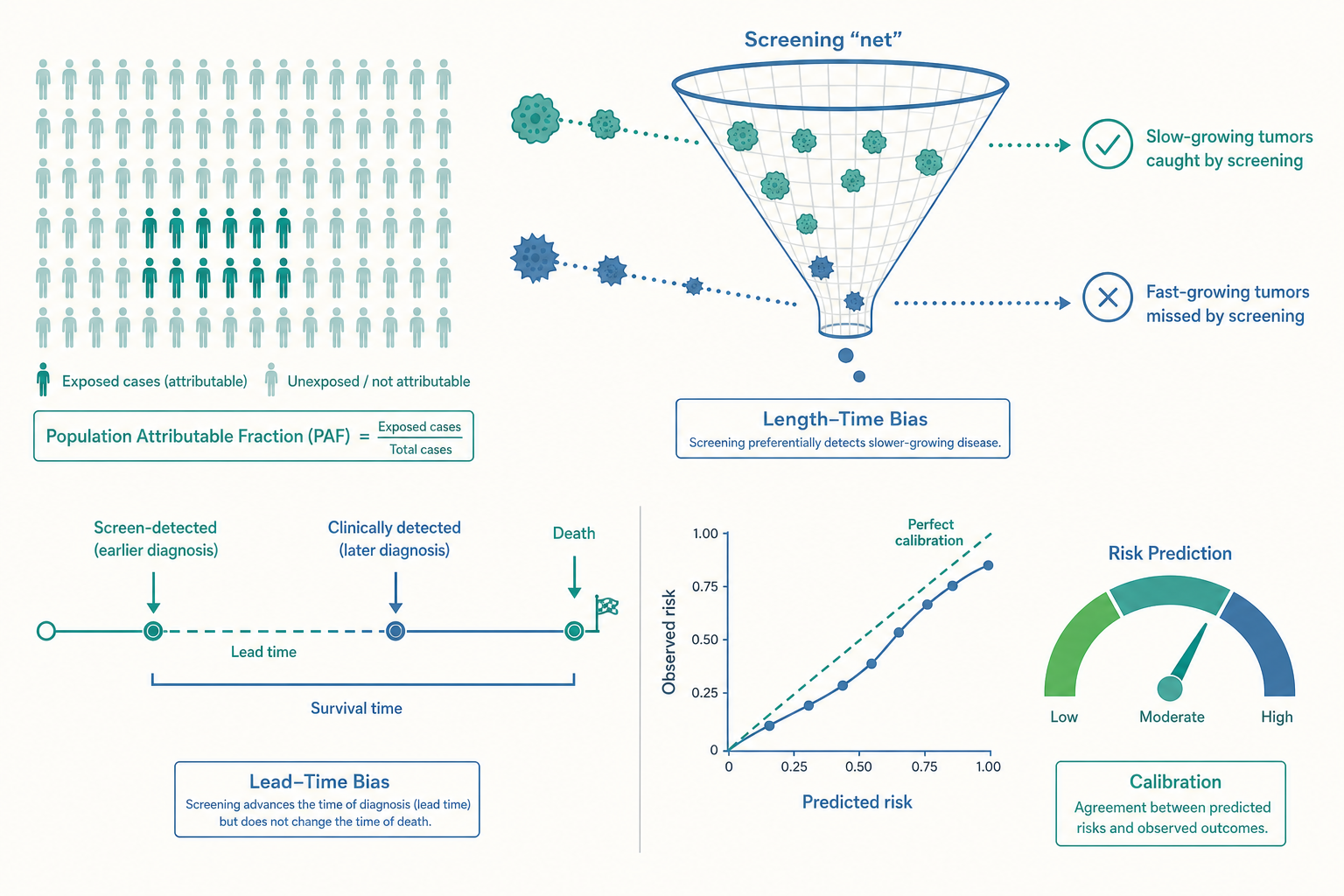
族群歸因分數:把「個人風險」翻譯成「族群可預防比例」
入門篇的 AR 處理的是「暴露者個人」的可歸因風險。但站在衛生部長的位置,他要問的是整個社會:在所有肺癌病例中,有多少比例「可歸因於吸菸」、因而理論上可隨吸菸消失而消失?這個量叫族群歸因分數(population attributable fraction, PAF),又稱族群可歸因危險度百分比。
PAF 最直覺的公式長這樣(Levin 公式):
$$\text{PAF} = \frac{P_e (RR - 1)}{1 + P_e (RR - 1)}$$
其中 $P_e$ 是族群中暴露的盛行率,$RR$ 是該暴露的相對危險。這條式子的靈魂在於:PAF 同時被「風險強度(RR)」與「暴露普及度($P_e$)」拉扯。 一個 RR 高得嚇人的危險因子,若全族群只有極少數人暴露,PAF 仍然很小;反之一個 RR 只是中等、卻人人都碰的因子,PAF 可以大得驚人。這正是入門篇「全人口策略 vs. 高危險群策略」張力的數學版本。
看一個例子:兩個危險因子,誰更值得管?
假設某縣市要在兩個介入方案之間擇一投入有限預算,流行病學資料如下:
| 危險因子 | 相對危險 RR | 暴露盛行率 $P_e$ | PAF |
|---|---|---|---|
| 罕見職業致癌物 | 20 | 1%(0.01) | ? |
| 身體活動不足 | 1.4 | 50%(0.5) | ? |
代入 Levin 公式:
- 職業致癌物:$\dfrac{0.01 \times (20-1)}{1 + 0.01 \times 19} = \dfrac{0.19}{1.19} \approx 0.16$,即 PAF ≈ 16%。
- 身體活動不足:$\dfrac{0.5 \times (1.4-1)}{1 + 0.5 \times 0.4} = \dfrac{0.20}{1.20} \approx 0.17$,即 PAF ≈ 17%。
結論耐人尋味:那個「RR 高達 20」的恐怖致癌物,對整體族群可預防的疾病比例(16%),竟和「RR 只有 1.4」的久坐不動(17%)差不多。差別全在暴露盛行率——前者只困擾 1% 的人,後者卻拖累一半人口。這就是為什麼公共衛生常把資源押在那些「看起來不嚴重、卻無所不在」的危險因子上。
不過 PAF 有兩個學生必須警惕的陷阱。第一,多個危險因子的 PAF 不能直接相加——因為同一個病例可能同時可歸因於多個因子(吸菸又肥胖的大腸癌病人),各因子的 PAF 加總常超過 100%,這不是算錯,而是「可歸因」本身允許重疊。第二,Levin 公式預設 RR 沒有受到干擾因子污染;若 RR 本身是被低估或高估的觀察值,PAF 會跟著偏掉。當代做法會改用「調整後 PAF」並交代清楚反事實情境(「如果暴露降到某個理論最低水準」而非「歸零」)。
次段預防的暗面:為什麼「早期發現」不一定等於「救命」
入門篇把篩檢(screening)列為次段預防的利器——血壓量測、乳房攝影、糞便潛血、低劑量電腦斷層(low-dose CT)篩肺癌……直覺上,越早抓到越好。但流行病學最反直覺、也最重要的教訓之一是:篩檢能讓統計數字「變好看」,卻未必真的延長壽命或減少死亡。 這背後有三大系統性偏誤。
一、前導時間偏誤(lead-time bias)。 假設一個人本來會在 60 歲因症狀就醫確診、65 歲過世,存活 5 年。現在篩檢讓他提前在 55 歲被診斷,但若治療其實無法改變病程,他仍在 65 歲過世——表面上「存活 10 年」,比沒篩檢的 5 年「翻倍」了。可是他一天也沒多活,只是提早知道自己生病、多當了 5 年病人。存活時間被「前移的診斷時點」灌水,這就是前導時間偏誤。它告訴我們:評估篩檢成效不能看「確診後存活期」,必須看族群死亡率這個不受診斷時點影響的硬指標。
二、病程長度偏誤(length-time bias)。 定期篩檢就像在河裡撒網——進展緩慢、停留在臨床前期較久的腫瘤,比起惡性、快速進展的腫瘤,更容易在某次篩檢的網目中被撈到。惡性腫瘤可能在兩次篩檢之間就爆發成有症狀的疾病,反而漏網。結果是篩檢揪出來的,系統性地偏向「本來就比較溫和、預後比較好」的病灶,讓篩檢看似讓病人活得更久——但這部分是「抽樣偏差」而非療效。
三、過度診斷(overdiagnosis)——病程長度偏誤的極端。 當「進展極慢」推到極致,就出現一種診斷上的悖論:篩檢揪出了一輩子都不會造成症狀、也不會致死的病灶。病人若不篩檢,會帶著它無事終老(多半死於其他原因);一旦篩檢發現,就背上癌症診斷、接受手術、放療、化療,承擔治療副作用——卻得不到任何延命好處。過度診斷是「真陽性」(病灶確實存在),卻是「無益甚至有害」的發現,它和偽陽性(false positive)是兩回事,也更難察覺。甲狀腺癌、攝護腺癌(PSA 篩檢)與部分早期乳癌、肺結節,都是過度診斷的常見戰場。
這三者合起來解釋了一個讓初學者震驚的現象:一項篩檢可以同時提高「五年存活率」、增加「早期癌症發現數」,卻對「族群死亡率」毫無貢獻。 因此判斷篩檢值不值得做,黃金標準仍是隨機對照試驗(RCT)以「特定疾病死亡率」甚至「總死亡率」為終點,而非任何形式的存活率或發現率。
篩檢的決策算式:靈敏度、特異度,與被盛行率玩弄的陽性預測值
就算一項篩檢真能降低死亡率,它仍要面對一道冷酷的數學。任何篩檢工具都有兩個固有特性:
- 靈敏度(sensitivity):真正有病的人中,被檢出陽性的比例(抓得到病人)。
- 特異度(specificity):真正沒病的人中,被正確判為陰性的比例(不誤傷健康人)。
但臨床現場與民眾最關心的,其實是另一個量:「我檢出陽性,到底有多大機率真的生病?」 這叫陽性預測值(positive predictive value, PPV)。而 PPV 的致命之處在於——它不只取決於工具好不好,更被疾病的盛行率(prevalence)狠狠左右。
動手試試:同一台機器,為什麼在篩檢時「失準」
假設一項篩檢靈敏度 99%、特異度 95%,聽起來相當優秀。我們用它去篩一個盛行率只有 0.5%(每 1000 人有 5 人真的有病)的族群,拿 10 萬人來算:
- 真有病者:100,000 × 0.5% = 500 人。其中檢出陽性(真陽性)= 500 × 99% = 495 人。
- 無病者:99,500 人。其中被誤判陽性(偽陽性)= 99,500 × 5% = 4,975 人。
- 所有陽性 = 495 + 4,975 = 5,470 人。
- PPV = 495 ÷ 5,470 ≈ 9.0%。
讀到這裡你應該愣住:一台靈敏度 99%、特異度 95% 的「好機器」,在低盛行率族群裡篩出陽性,竟然只有 9% 真的有病,另外 91% 是虛驚一場的偽陽性。原因是健康人實在太多了,即使只有 5% 被誤判,絕對數量(4,975)也遠遠淹沒了真正的病人(495)。
這個現象(基率謬誤,base rate fallacy 的醫學版本)對慢性病次段預防有深遠意涵:在盛行率很低的一般族群「全面普篩」,往往製造海量偽陽性,帶來後續確認檢查的成本、侵入性切片的風險與當事人的焦慮。這正是為什麼許多篩檢指引強調「鎖定高危險群」——把篩檢用在盛行率較高的次族群(如針對重度吸菸史者做肺癌 LDCT),能大幅拉高 PPV,讓每一個陽性結果更有意義。盛行率,是把「全人口策略」與「高危險群策略」分開的隱形槓桿。
需要篩檢多少人才救一命?NNS 與預防的「規模感」
在治療研究中,我們用益一需治數(number needed to treat, NNT)——「平均要治療多少人,才能避免一個不良結局」——來表達療效的實際規模。NNT 是絕對風險下降(absolute risk reduction, ARR)的倒數:$NNT = 1 / ARR$。預防領域有對應的概念:需篩檢人數(number needed to screen, NNS),意指「平均要篩檢多少人,才能避免一例該病死亡」。
NNS 之所以重要,是因為它把抽象的「相對風險下降」翻譯成決策者與民眾都能感受的規模。舉例,若某癌症篩檢在十年追蹤中把該癌死亡率從每千人 7 例降到 5 例,ARR = 2/1000 = 0.002,NNS ≈ 500——意思是要篩 500 人十年,才換回一條命。這個數字本身不分好壞,重點是它讓我們能和代價放在同一個天平上比較:這 500 人裡,有多少人經歷偽陽性、多少人被過度診斷而白白手術、整體成本多少?唯有把「救回的命」與「付出的傷害」用同一把尺(每千人、每人年)量出來,預防決策才不會淪為「早期發現一定好」的口號。
這也呼應入門篇的歸因危險度精神:流行病學的價值,在於把模糊的『好』與『壞』逼成可以相減、相除、相互權衡的具體數字。
從危險因子清單到風險預測模型:預防的精算化
傳統慢性病預防把危險因子當成一張「清單」逐項打勾(有沒有抽菸?血壓高不高?)。但當代心血管預防已經走向整合式風險預測模型——把多個因子餵進一條方程式,輸出「未來十年發生心血管事件的機率」。最有名的例子是 Framingham 風險評分與後續的 pooled cohort equations(PCE)、歐洲的 SCORE2。
這代表一種思維轉變:預防不再問「你有沒有危險因子」,而問「綜合起來,你未來十年的絕對風險是百分之幾」,再據此決定是否啟動藥物(如他汀類 statin)介入。這把預防變成一門精算學,而精算學最在乎兩件事:
- 區辨力(discrimination):模型能不能把「將來會發病的人」和「不會的人」分開?常用 C-statistic(即 AUC)衡量,0.5 等於瞎猜,越接近 1 越好。
- 校準度(calibration):模型說「這群人十年風險 10%」,實際追蹤下來真的約有 10% 發病嗎?一個區辨力高但校準差的模型,會系統性高估或低估風險,導致該吃藥的沒吃、不必吃的吃了。
這裡有個對台灣學生極切身的提醒:美國世代建立的 PCE 直接套到亞洲族群,往往高估風險——因為基準發病率與危險因子的效應在不同族群並不相同(呼應流行病學進階篇講的「可遷移性/transportability」)。因此本地化的校準(recalibration)不是學術潔癖,而是攸關「會不會讓一整個族群被過度用藥」的公共衛生問題。
近年更前沿的方向是把多基因風險評分(polygenic risk score, PRS)併入模型,試圖在出生時就標定遺傳易感性。但 PRS 目前面臨兩個結構性難題:一是多數 PRS 來自歐洲血統的全基因組關聯研究(GWAS),在非歐洲族群預測力顯著衰減,可能加劇而非縮小健康不平等;二是「知道自己基因高風險」是否真能促成行為改變、又是否帶來保險歧視與心理負擔,仍是倫理與實證的開放問題。這提醒我們:更精準的預測,不自動等於更好的健康,端看它如何被使用、被誰使用。
重點回顧
- 族群歸因分數(PAF)由「相對風險」與「暴露盛行率」相乘決定,這解釋了為何 RR 中等卻普遍的危險因子(如久坐)值得投入;多因子的 PAF 不能直接相加。
- 「早期發現」不等於「救命」:前導時間偏誤讓存活期灌水、病程長度偏誤讓溫和病灶被優先撈出、過度診斷揪出一輩子無害的病灶——三者都讓存活率與發現數變好看卻不降死亡率。
- 判斷篩檢成效的黃金標準是 RCT 以「疾病死亡率」為終點,而非任何存活率或發現率。
- 陽性預測值(PPV)被盛行率主宰:再好的工具在低盛行率族群普篩,也會製造大量偽陽性,這是「鎖定高危險群篩檢」的數學依據。
- 預防正走向精算化:風險預測模型須同時兼顧區辨力與校準度,且歐美模型直接套用亞洲族群常高估風險,本地化校準與 PRS 的族群偏差都是公平性議題。
深入探討(研究所視角)
把上述工具收束起來,研究所層次的慢性病預防其實在處理一個共同主題:如何在「個人層次的機率」與「族群層次的負擔」之間正確地來回翻譯,並讓每一次翻譯都對得起證據與公平。
一、PAF 的因果重述與「可介入性」。 現代流行病學(Greenland、Hernán 等)主張把 PAF 重新定義為一個反事實的介入效果——「若全族群的暴露分布被移到某個理論最小風險暴露(theoretical minimum risk exposure)」下,疾病負擔會下降的比例。這種寫法的好處是逼研究者講清楚「移除暴露」具體是什麼介入(戒菸到零?還是降到某盛行率?),並讓 PAF 可以納入時變暴露與競爭風險(competing risks)的處理。全球疾病負擔研究(Global Burden of Disease, GBD)正是以這套比較風險評估(comparative risk assessment)框架,產出各國各危險因子的可歸因死亡與失能調整生命年(DALY)。
二、篩檢評估的進階偏誤與停止規則。 除了三大偏誤,研究所層次還須處理健康志願者偏誤(healthy volunteer bias)(會來篩檢的人本就較健康)、重疊診斷與過度診斷的量化估計(用 excess incidence 法或長期追蹤的累積發生率差)。當代爭論的核心已從「篩不篩」轉向「對誰、多久篩一次、何時該停」,以及如何把「過度診斷造成的傷害」正式納入決策分析——這催生了以品質調整生命年(QALY)為單位、納入偽陽性與過度診斷負效用的成本效用分析(cost-utility analysis)。
三、競爭風險與「預防的目標到底是什麼」。 慢性病預防有一個常被忽略的哲學難題:在高齡族群,降低某病死亡風險,可能只是讓人改死於另一種病(競爭風險)。若一項介入大幅降低心血管死亡卻不影響總死亡,它的公共衛生價值該如何評價?這迫使研究者區分「特定病因死亡率」與「全因死亡率」,並引入健康餘命(healthy life expectancy)、壓縮病態(compression of morbidity)等概念——預防的終極目標或許不是「不死」,而是「把失能與病痛壓縮到生命最末端」。
四、精準預防與公平的張力。 風險預測模型、PRS、乃至以穿戴裝置與電子病歷驅動的精準公共衛生(precision public health),承諾把預防資源更精準地投向高風險者。但 Geoffrey Rose 的古典警告依然有效:過度聚焦高危險群,會錯過「預防弔詭」指出的、來自低風險多數的大量病例,也可能讓「全人口環境改造」(菸稅、食物環境、都市設計)這條最公平、最有效的路線被邊緣化。更深的隱憂是,若預測模型的訓練資料、PRS 的 GWAS 樣本系統性偏向特定族群,精準工具反而會把既有的健康不平等寫進演算法。前沿研究因此把演算法公平性(algorithmic fairness)、模型在弱勢族群的校準、與可近性(誰用得到這些工具)視為與預測準確度同等重要的評估維度。
五、跨領域的綜合視野。 把這一切串起來,慢性病預防的進階研究是流行病學方法(PAF、存活分析、因果推論)、決策科學(成本效用分析、NNS/NNT、價值取捨)、遺傳與分子流行病學(PRS、發炎與代謝機制)、資料科學(風險模型、校準、演算法公平)、與健康政策/倫理(社會決定因素、可近性、保險歧視)的交會點。對有志深入的學生,一個值得反覆叩問的整合性問題是:當我們手握越來越精細的個人風險預測,公共衛生「以群體為念、以最弱勢為先」的初衷,要如何不被『精準』之名稀釋? 這既是方法論的前沿,也是這門學科的良心所在。