
那條步道真的「有效」嗎?——當你必須向審稿人證明它
在無法隨機分派的真實世界裡,如何用類實驗設計建構反事實、用族群機制解釋效果放大,並以人口可歸因分數量化健康促進的政策效益。
那條步道真的「有效」嗎?——當你必須向審稿人證明它
入門篇留下了一個漂亮卻危險的故事:城市鋪了一條步道,兩年後周邊居民血壓整體下降了一點。聽起來很有說服力。但如果你是那份報告的審稿人,或是要決定是否再撥三億預算複製這項計畫的市議員,你應該立刻追問一句:你怎麼知道是步道讓血壓降的,而不是這兩年剛好景氣變好、健保推了減鹽政策、或是河岸本來就住著比較有錢、比較愛運動的人?
這一句追問,就是健康促進從「感人故事」升級為「公衛科學」的分水嶺。進階篇不再重述什麼是渥太華憲章或上游思維——你已經懂了。我們要處理的是更硬的問題:當你無法做隨機分派時,如何用流行病學的設計與測量,逼近一個可信的因果結論?一項介入又是透過哪些族群層次的機制,把效果從少數人擴散到整座城市? 這正是研究所訓練與真實政策評估每天在搏鬥的核心。
健康促進的「原罪」:你幾乎永遠不能隨機分派
藥物試驗的黃金標準是隨機對照試驗(randomized controlled trial, RCT):把人隨機分到實驗組與對照組,因為隨機化,兩組在所有已知與未知的干擾因子上都會趨於平衡,事後的差異就能歸因於介入。
但健康促進的介入對象常常是整個地理單位、整個社區、整套政策。你不可能把步道「只蓋給隨機抽中的一半市民」;你不可能把菸品稅「只課給隨機選中的縣市」;含糖飲料標示一旦上路,就是全國同時生效。介入單位是地方(place),不是個人(person)。這帶來兩個結構性難題:
- 無法個人隨機分派:採用步道的人,本來就可能更年輕、更健康、社經地位更高。這種選擇性(selection)會讓「步道有效」的結論被自我選擇汙染。
- 群聚與外溢:同一社區的人會互相影響(鄰居一起去走、彼此分享),個人之間並非獨立。標準的個人層次統計會嚴重低估標準誤、誇大顯著性。
於是健康促進的證據幾乎全部建立在類實驗設計(quasi-experimental designs)之上。它的任務是:在沒有隨機化的世界裡,建構一個可信的「反事實(counterfactual)」——也就是「如果沒蓋這條步道,這群人的血壓會變成怎樣」。整個方法論的戰場,就是這個看不見的反事實之爭。
三把建構反事實的利器
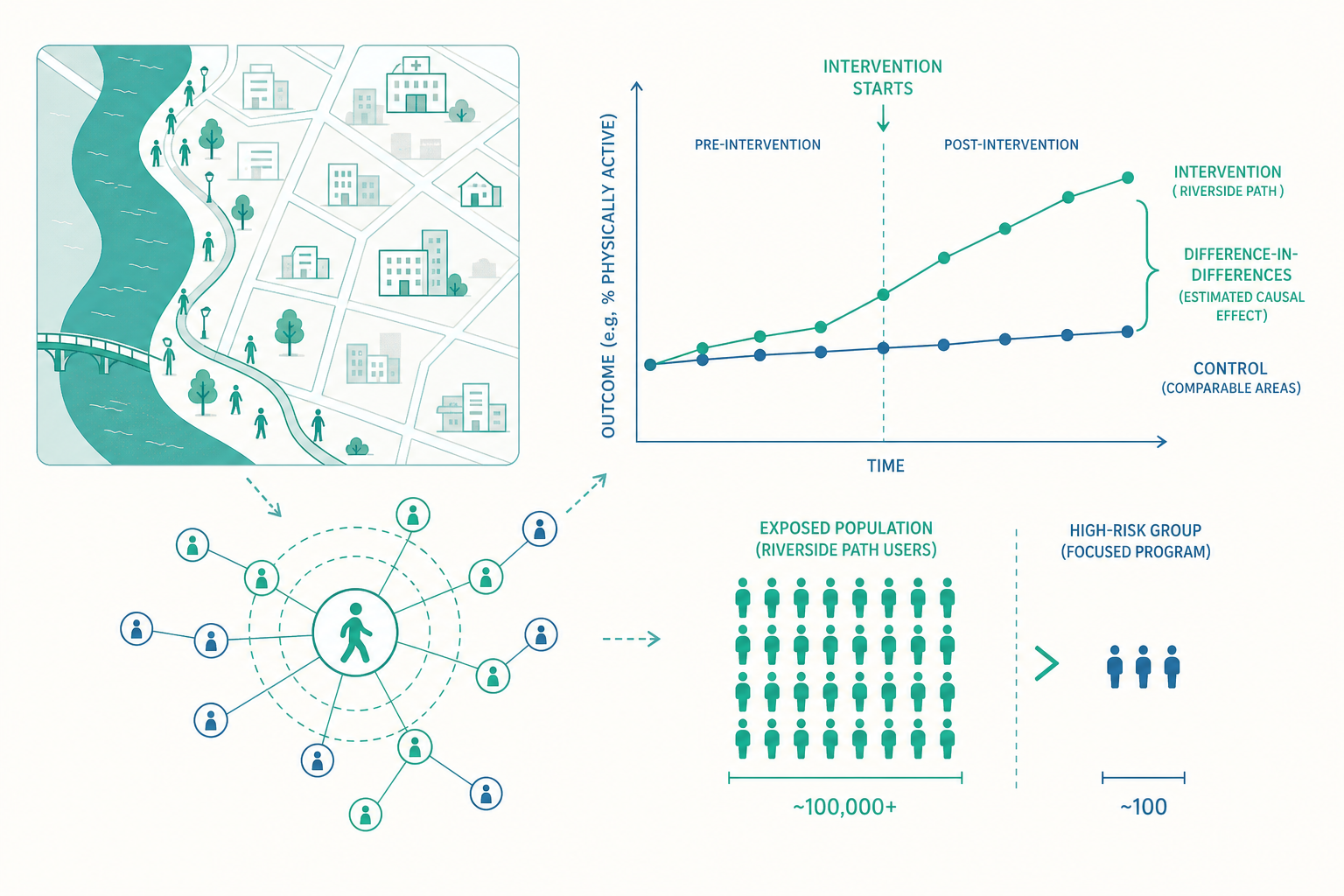
一、差異中之差異(Difference-in-Differences, DiD)
這是健康促進評估最常用的設計。核心直覺:與其單純比較「介入後 vs. 介入前」(會被時間趨勢汙染,例如全國本來就在變健康),不如比較兩個差異的差異。
假設 A 市鋪了步道(介入組),鄰近沒鋪步道、條件相近的 B 市當對照組。我們測量四個量:A 市的前後(A前、A後)、B 市的前後(B前、B後)。
$$\text{DiD} = (A_{後} - A_{前}) - (B_{後} - B_{前})$$
第一個括號是 A 市的變化,但裡面混了「步道效果+全國時間趨勢」;第二個括號是 B 市的變化,代表「純粹的全國時間趨勢」。兩者相減,時間趨勢被抵銷,剩下的就是步道的淨效果。
DiD 成立的關鍵假設是「平行趨勢(parallel trends)」:若 A 市沒鋪步道,它的血壓變化軌跡會與 B 市平行。這個假設無法被完全證明,但可以用「介入前若干年兩市的趨勢是否平行」來增強或削弱信心。一旦介入前兩條線就已經分岔,DiD 的結論就站不住腳。研究所層級審查一篇 DiD 論文,第一個要看的圖永遠是「介入前的平行趨勢檢定」。
二、中斷時間序列(Interrupted Time Series, ITS)
當你找不到合適的對照地區,但手上有介入前後一長串連續的時間點資料(例如每月的心肌梗塞住院數),ITS 是利器。它不比較兩地,而是比較「同一群人介入前的趨勢」與「介入後的趨勢」。
ITS 估計兩種效果:
- 水平改變(level change):介入瞬間,指標是否陡降或陡升(例如菸害防制法上路那一刻,急性心肌梗塞住院數立即下跌)。
- 斜率改變(slope change):介入後,長期趨勢的方向或速度是否改變。
ITS 最經典的應用之一,是各國無菸環境法(室內公共場所禁菸)上路後,急性冠心症住院率的變化。多項研究觀察到法令生效後住院數出現可辨識的水平下降,且這個下降與菸稅、經濟波動等其他變因在時間上難以混淆,因為「政策在某個明確日期一刀切」這件事,本身就提供了強而有力的識別力道。
三、合成控制法(Synthetic Control)
這是近二十年最受重視的方法之一,專門解決「只有一個介入單位、找不到單一完美對照」的窘境。它的巧思是:不靠單一對照地區,而是用一組未介入地區的加權組合,合成出一個量身打造的「假想對照」。
舉例:要評估加州 1988 年的菸害防制計畫對人均香菸消費的影響,你找不到任何單一州和加州一模一樣。合成控制法會在數十個未推動類似計畫的州之中,自動計算一組權重(例如 0.16×猶他、0.20×內華達、0.11×蒙大拿……),讓這個加權合成出來的「合成加州」在介入前的香菸消費軌跡幾乎完全貼合真實加州。介入後,真實加州與合成加州一旦分岔,那道缺口就是計畫的估計效果。這個方法把「對照組的選擇」從研究者的主觀判斷,變成資料驅動的最佳化問題,大幅提升透明度。
機制問題:效果是怎麼從少數人「長成」整座城市的?
證明了「有效」之後,研究所層級會追問更深的一層:為什麼有效?效果透過什麼族群層次的機制被放大? 健康促進之所以能用相對少的介入點撼動整群人,靠的不是把訊息塞給每一個人,而是幾種非線性的擴散機制。
一、社會網絡的擴散(social contagion)。 行為會沿著人際網絡傳遞。著名的 Framingham 心臟研究衍生分析發現,肥胖、戒菸、快樂等狀態,會在朋友、朋友的朋友之間呈現可觀察的群聚與擴散。這意味著一項介入若能改變網絡中的關鍵節點(意見領袖、高連結度的人),效果會像漣漪般外溢到從未直接接觸介入的人。這也是為什麼北卡瑞利亞計畫刻意訓練在地家庭主婦團體與合作社——它在投資網絡的擴散力,而非單向的衛教。
二、社會規範的轉移(norm shift)。 真正巨大的健康轉變,往往發生在「什麼是正常、可被接受的行為」這條集體標準移動的時候。室內禁菸法的長期效果,不只來自被罰款的嚇阻,更來自它重新定義了「在別人面前抽菸」這件事的社會意義——當抽菸從「瀟灑」變成「沒禮貌」,連法令管不到的私人場合,吸菸率也跟著下滑。健康促進操作的是集體規範,這是個人衛教永遠搆不到的層次。
三、選擇架構與預設值(default effect)。 行為經濟學告訴我們,人的選擇高度受「預設選項」與「環境如何擺設」影響。把員工餐廳的健康餐點放在動線最前端、把含糖飲料移到較不顯眼的位置,往往比任何「請選擇健康飲食」的標語更有效。健康促進在環境裡動的手腳,是在改變整群人面對的選擇結構,而不是逐一說服每顆腦袋。
理解這些機制,你才會明白為什麼「族群層次」不是一句口號:介入的效果不是 N 個獨立個人效果的單純加總,而是經過網絡擴散、規範轉移、環境重塑後的非線性放大。
把「省下多少病例」算清楚:人口可歸因分數(PAF)
健康促進要爭取預算,必須能回答政策制定者最現實的問題:這項措施到底能讓全人口少生多少病? 這需要一個比「相對風險」更貼近族群現實的指標——人口可歸因分數(Population Attributable Fraction, PAF)。
PAF 的意義是:假如完全消除某個危險因子的暴露,整個族群的疾病負擔可以減少幾個百分比。 它同時取決於兩件事:危險因子有多危險(相對風險 RR),以及這個族群裡有多少人暴露其中(盛行率 $P_e$)。常用的計算式為:
$$\text{PAF} = \frac{P_e (RR - 1)}{1 + P_e (RR - 1)}$$
這條式子藏著健康促進最重要的策略洞見:一個只有中等危險、但全民普遍暴露的因子,造成的整體病例數,可能遠多於一個極度危險、卻只有少數人暴露的因子。 高鹽飲食的相對風險不算驚人,但因為幾乎人人都吃太鹹($P_e$ 巨大),它的 PAF 反而很高——這就是為什麼全人口減鹽政策的潛在效益遠超過只鎖定少數重症高血壓病人。Geoffrey Rose 的人口觀,在 PAF 這條公式裡得到了量化的支撐。
看一個例子:用 PAF 比較兩種策略
假設某城市的高血壓由「飲食過鹹」這個因子驅動。流行病學調查顯示:
- 高鹽飲食者罹患高血壓的相對風險 $RR = 1.5$。
- 全城成年人中,有 $P_e = 60\%$ 屬於高鹽飲食。
代入 PAF 公式:
$$\text{PAF} = \frac{0.6 \times (1.5 - 1)}{1 + 0.6 \times (1.5 - 1)} = \frac{0.6 \times 0.5}{1 + 0.3} = \frac{0.30}{1.30} \approx 0.23$$
也就是說,若能完全消除高鹽飲食,全城高血壓病例約可減少 23%。
現在對照一個「高風險策略」的思維:只去處理飲食最鹹的前 5% 重度族群。就算對這 5% 的人介入極為成功,他們占全城暴露的比例太小,能消去的整體病例數遠遠達不到 23%。這個算術,把入門篇的「預防弔詭」從直覺變成了可計算的決策依據——它告訴你,把資源投在哪一端,省下的病例數會差一個數量級。
(提醒:以上 RR 與盛行率為教學設定的概略數值,用以演示 PAF 的策略邏輯;真實估計需依在地族群資料校正,且「完全消除暴露」是理論上限,實務上的可達成幅度會小得多。)
從「健康促進方案」到「把健康放進每一項政策」
進階視野的最後一塊拼圖,是承認健康促進的天花板:再好的步道、再用心的社區計畫,影響力都比不上稅制、交通、住宅、教育這些非衛生部門的決策。一條馬路怎麼設計,決定了孩子能不能安全走路上學;最低工資怎麼定,影響的健康後果可能勝過十場戒菸講座。
這催生了當代健康促進的前沿框架——「將健康融入所有政策(Health in All Policies, HiAP)」。它主張:健康不該只是衛生部門的責任,每一個部門在做決策時,都應評估其對健康與健康公平的影響。對應的實務工具是健康影響評估(Health Impact Assessment, HIA):在一項重大建設或政策上路前,系統性地預測它對不同族群健康的潛在衝擊,並提出減害建議。
HiAP 也直面了入門篇結尾提到的公平難題。純粹的全人口策略可能讓資源多的人受益更多,於是 WHO 與各國政策圈逐漸採納比例普及性(proportionate universalism):服務對全民開放,但投入的力道依需要程度按比例加重——越弱勢的社區,得到的支持越多。這不是回到只服務少數高風險者的舊路,而是在「普及」與「精準縮小不平等」之間求取平衡。如何在政策中操作化這個原則,是健康促進此刻最活躍的辯論之一。
重點回顧
- 健康促進的方法論原罪是無法隨機分派:介入單位常是「地方」而非「個人」,因此整個評估科學的核心,是在沒有 RCT 的情況下,建構一個可信的反事實。
- 三把建構反事實的利器:差異中之差異(DiD,靠平行趨勢抵銷時間趨勢)、中斷時間序列(ITS,看政策上路瞬間的水平與斜率改變)、合成控制法(用未介入地區的加權組合合成假想對照)。
- 效果靠族群機制非線性放大:社會網絡擴散、社會規範轉移、選擇架構與預設值,讓介入效果不是個人效果的加總,而是經過社會放大的結果。
- PAF 把「省下多少病例」量化:人口可歸因分數同時取決於相對風險與暴露盛行率,解釋了為何「中等危險但普遍暴露」的因子(如高鹽)值得全人口介入,為 Rose 的人口觀提供算術支撐。
- 前沿是 HiAP 與比例普及性:把健康融入所有政策、用健康影響評估事前把關,並依需要程度按比例加重投入,以同時兼顧普及與公平。
深入探討(研究所視角)
把上述工具串成一條完整的研究鏈,是研究所訓練的真正目標。以下提供幾條延伸線索。
一、因果識別的圖形語言(DAG)。 DiD、ITS、合成控制都在對抗同一個敵人——混淆(confounding)。但「該校正哪些變項、不該校正哪些變項」並非憑直覺,而是可以用有向無環圖(Directed Acyclic Graph, DAG)系統推導。DAG 能清楚區分混淆因子(要校正)、中介因子(校正了反而會擋掉你想看的機制效果)、對撞因子(collider,校正了會憑空製造偏誤)。一個常見的初學者錯誤,是把「步道使用」這個中介變項當混淆因子去校正,結果把真正的效果路徑也一併抹掉。能畫對 DAG,是批判任何觀察性健康促進研究的先決能力。
二、群聚隨機與多層次結構。 當介入真的能隨機分派,但分派單位是社區、學校、診所而非個人時,正確設計是群聚隨機對照試驗(cluster RCT)。它的統計核心是組內相關係數(intraclass correlation, ICC):同一群聚內的人彼此相似,會降低有效樣本數,因此事前的檢力計算(power analysis)必須納入設計效應(design effect),否則會嚴重低估所需樣本量。分析端則對應到多層次模型(multilevel models),與本平台優統計讀本中的 hierarchical model 主題直接相連——忽略巢套結構會誇大顯著性,是審稿時最常被退稿的硬傷。
三、複雜介入的評估典範。 健康促進方案常是「複雜介入(complex intervention)」:多個交互作用的成分、多層次的作用對象、結果隨脈絡而變。英國 Medical Research Council(MRC)的複雜介入評估指引,主張除了問「有沒有效(outcome evaluation)」,更要做過程評估(process evaluation):介入是否真的被忠實執行(fidelity)、透過哪些中介機制起作用、在不同脈絡下為何效果不同。這把評估從黑箱式的「有效/無效」二分,推進到「在什麼條件下、對誰、透過什麼機制有效」的實境主義(realist evaluation)取向。
四、外推性與情境依賴。 北卡瑞利亞的成功能不能複製到台灣的偏鄉?合成控制估出的加州效果能不能套用到別州?這是外部效度(external validity)的問題。健康促進的效果高度依賴在地的社會規範、網絡結構與制度脈絡,因此「在 A 地有效」不保證「在 B 地有效」。成熟的研究者會明確界定介入的作用機制與邊界條件,而非把單一場域的效果量直接搬運。
五、跨領域與資料前沿。 評估的未來正被多模態資料重塑。穿戴裝置讓「身體活動」「睡眠」「壓力」從問卷自陳升級為連續客觀量測;行政與地理資料讓暴露(綠地、空氣、可步行性)能與健康結果在細緻的時空尺度上連結;這正是本平台環境組學(Environomics)與 Educational Omics 框架想承載的視角——讓「上游」的監測更即時、更可被因果地分析。當你日後讀到任何一項健康促進證據,請同時用四把尺去衡量它:反事實建構得夠不夠可信、混淆有沒有用 DAG 排乾淨、效果機制能不能被過程評估打開、結論能外推到多遠。這套批判眼光,正是研究所希望你內化、也是真實世界政策決策最稀缺的能力。