
如果要把「髒空氣」換算成可以列進國家預算的數字,你會怎麼算?
從風險評估四步驟、人口可歸因分數與反事實,到統計生命價值——拆解環境健康風險如何從流行病學曲線一路轉譯成可被政策比較與質疑的數字。
如果要把「髒空氣」換算成可以列進國家預算的數字,你會怎麼算?
你已經知道 PM2.5(細懸浮微粒)會深入肺泡、知道暴露不等於劑量、也知道濃度—反應曲線在低濃度區間更陡。但這裡有一個更尖銳的問題:當一位部長問「如果我們把全國 PM2.5 年均從 18 μg/m³ 降到 10 μg/m³,到底能救多少人、值多少錢?」——你要如何從一條流行病學曲線,一路推導到一個可以寫進政策評估報告、和高鐵建設或健保支出放在同一張表上比較的具體數字?
這個從「機制」到「貨幣」的轉譯鏈,正是進階環境衛生與入門最大的分野。入門告訴你「環境會致病」,進階則要求你建立一套可量化、可稽核、可被質疑的估算方法,讓環境風險能與其他公共支出在同一個尺度上競爭資源。這篇文章,我們就走完這條鏈。
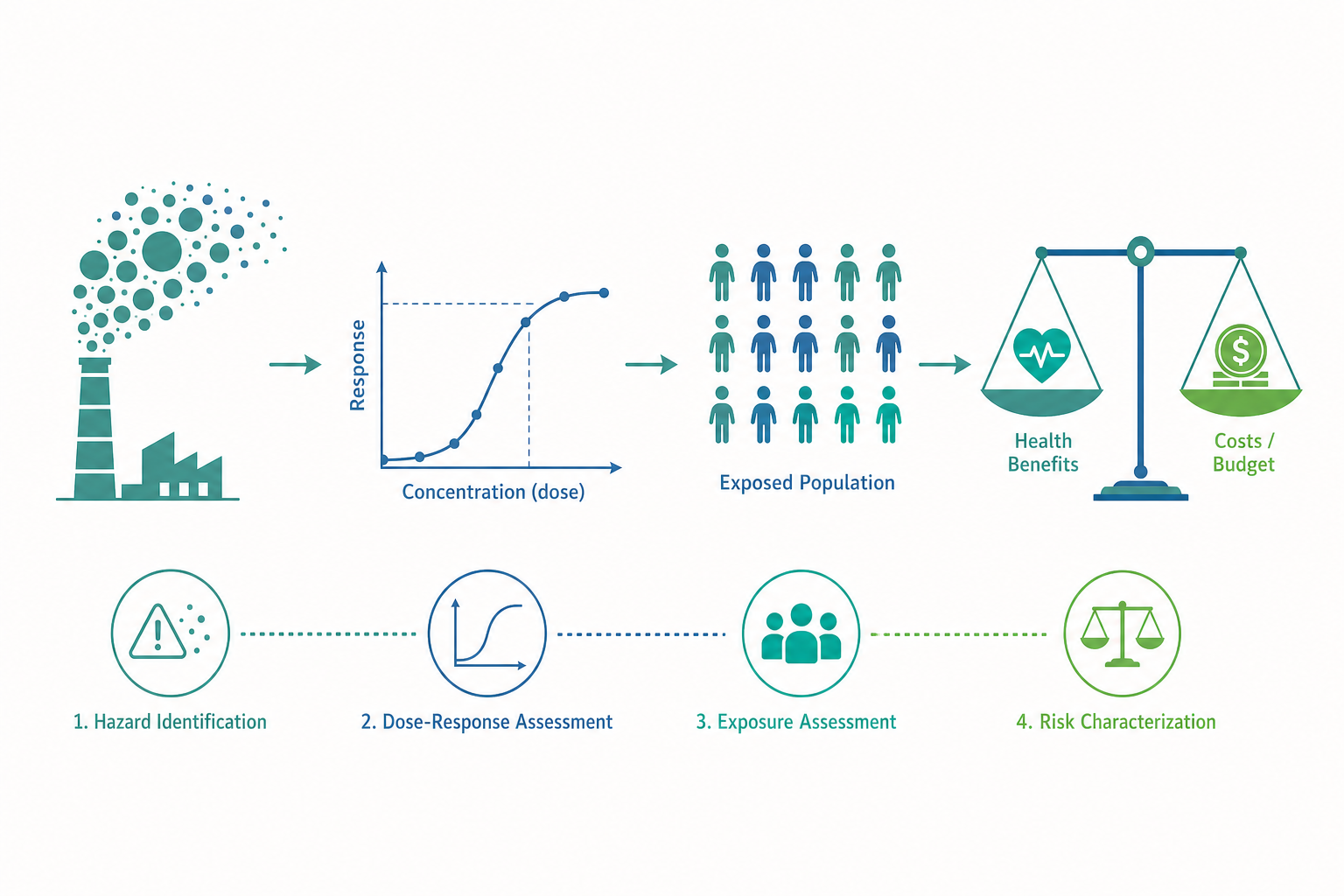
風險評估的四步驟:把不確定性拆解開來
現代環境健康風險評估(environmental health risk assessment)的骨架,源自美國國家研究委員會(NRC)1983 年的「紅皮書(Red Book)」,至今仍是國際通用的分析框架。它把一個龐雜的問題,拆成四個可以分別處理、分別檢視不確定性的步驟:
- 危害辨識(hazard identification):這個物質「會不會」造成某種健康效應?依據是毒理學動物實驗、體外試驗,以及人類流行病學證據。國際癌症研究署(IARC)的致癌物分類(Group 1 確定、2A 可能、2B 或許)就是這一步的代表性產出。
- 劑量—反應評估(dose–response assessment):暴露「多少」對應「多大」的效應?這一步要建立量化的劑量—反應函數。對非致癌效應,會找出參考劑量(reference dose, RfD)——通常從動物實驗的「無可觀察不良效應劑量(NOAEL)」除以一系列不確定性因子(種間差異、個體差異各取 10 倍)得到。對致癌物,則建立斜率因子(slope factor),描述每單位劑量對應的終生超額致癌風險。
- 暴露評估(exposure assessment):目標族群「實際」承受多少暴露?這牽涉攝入途徑、攝入率、暴露頻率與期程的整合,產出如「每公斤體重每日攝入量(mg/kg/day)」這類可與劑量—反應函數對接的量。
- 風險特徵化(risk characterization):把前三步合成,估算族群的風險大小,並誠實陳述不確定性——哪些是參數誤差、哪些是模型假設、哪些是純粹未知。
這個框架的真正價值不在於給出一個「正確答案」,而在於它強制分析者把不確定性攤開:每一步都要說明證據強度與假設。一個成熟的環境衛生工作者,看到一個風險數字時,第一反應不是問「是多少」,而是問「這四步各自做了什麼假設、最脆弱的環節在哪裡」。
從相對風險到歸因負擔:反事實才是關鍵
入門文章用「PM2.5 每上升 10 μg/m³,全因死亡率上升約 7%」算出了兩個城市的超額死亡。但要把這套邏輯放大到整個國家、甚至全球比較,需要一個更嚴謹的工具:比較風險評估(comparative risk assessment, CRA),這正是全球疾病負擔研究(Global Burden of Disease, GBD)估算空汙死亡人數的方法核心。
它的關鍵概念是反事實(counterfactual):我們不是問「汙染造成多少死亡」,而是問「如果暴露降到某個理論最小風險暴露水準(theoretical minimum-risk exposure level, TMREL),可以避免多少死亡」。換句話說,所有歸因負擔都是相對於一個「假想的乾淨世界」而言的。對 PM2.5,TMREL 通常設在一個極低、自然背景值附近的區間。
把這個概念量化,靠的是人口可歸因分數(population attributable fraction, PAF):
$$PAF = \frac{\sum P_i \cdot (RR_i - 1)}{\sum P_i \cdot (RR_i - 1) + 1}$$
其中 $P_i$ 是暴露於第 $i$ 個濃度級距的人口比例,$RR_i$ 是該級距相對於 TMREL 的相對風險。PAF 告訴你:「這個族群的某疾病負擔中,有多少比例可歸因於該暴露超過理論最小值的部分。」把 PAF 乘上該疾病的總負擔(總死亡數,或總失能調整生命年 DALYs),就得到可歸因的疾病負擔。
這裡有個容易踩的陷阱:多個風險因子的 PAF 不能直接相加。因為吸菸、空汙、高血壓的致病路徑彼此重疊,把各自的 PAF 加總會超過 100%。GBD 因此採用「聯合人口可歸因分數」與層級化的中介關係來避免重複計算——這也是為什麼不同機構公布的「空汙死亡人數」會有差異:差異往往不在原始資料,而在反事實的設定、相對風險曲線的選擇與重疊風險的處理方式。
看一個例子:用 PAF 估算可避免的死亡
假設某國 PM2.5 暴露分成三級,人口分布與相對於 TMREL 的相對風險如下:
| 暴露級距 | 人口比例 $P_i$ | 相對風險 $RR_i$ |
|---|---|---|
| 低(接近 TMREL) | 0.30 | 1.00 |
| 中 | 0.45 | 1.10 |
| 高 | 0.25 | 1.25 |
先算分子 $\sum P_i(RR_i-1)$: - 低:$0.30 \times 0 = 0$ - 中:$0.45 \times 0.10 = 0.045$ - 高:$0.25 \times 0.25 = 0.0625$ - 合計 $= 0.1075$
代入 PAF 公式:
$$PAF = \frac{0.1075}{0.1075 + 1} = \frac{0.1075}{1.1075} \approx 0.097$$
也就是說,這個族群的相關疾病死亡中,約 9.7% 可歸因於 PM2.5 暴露超過理論最小值。若該疾病每年死亡 4 萬人,則 $0.097 \times 40000 \approx 3{,}880$ 人/年的死亡,理論上可透過把暴露全面降到 TMREL 來避免。
請特別注意這個數字的性質:它是一個反事實的、族群層次的、帶有模型假設的估計,不是「現場可數出的屍體」。理解這一點,你才不會被新聞標題「空汙害死 X 萬人」誤導成精確計數,也才有能力追問那個 X 是怎麼算出來的。
整合暴露—反應函數:當低濃度與高濃度必須共用一條曲線
要做全球比較,還有一個技術難題:人類暴露於 PM2.5 的範圍極廣——從北歐的個位數,到南亞、撒哈拉以南非洲因家戶固體燃料燃燒造成的數百 μg/m³。沒有任何單一世代研究能涵蓋如此寬廣的濃度。
GBD 的解法是建構整合暴露—反應函數(integrated exposure-response, IER;後續版本演進為 GEMM 等模型),把來自不同來源的證據縫合在同一條曲線上:戶外空汙的世代研究(低到中濃度)、二手菸暴露、家戶空汙、乃至主動吸菸的劑量(提供高濃度端的錨點)。這個做法背後的假設是:對心肺終點而言,微粒就是微粒,無論它來自柴油廢氣還是香菸煙霧,達到相同的肺部劑量就帶來可比的風險。
這條整合曲線在低濃度端通常呈現超線性(supra-linear)形狀——斜率比高濃度端更陡,這在生物學上呼應了入門提到的「找不到安全閾值」現象,也在政策上強化了「改善已經不錯的空氣仍有可觀邊際效益」的論點。但這個縫合假設本身也是爭論點:批評者質疑跨暴露來源的可比性、以及用吸菸資料外推非吸菸族群的效度。這提醒我們,愈是漂亮的全球數字,背後縫合的假設往往愈多——進階學習者的責任,是看見那些縫線。
易感窗、混合暴露與累積風險:當現實比單一物質複雜
風險評估的古典框架假設「一次一個物質、效應隨劑量平滑變化」,但真實環境給我們的是更棘手的三重複雜性:
易感窗(windows of susceptibility):暴露的「時機」可能比「總量」更關鍵。胎兒神經發育期對鉛與甲基汞、肺臟發育期對空汙、青春期對內分泌干擾物,都存在特別脆弱的發育窗。同樣的累積劑量,落在敏感窗內與窗外,效應可能天差地別。這使得單純的「終生累積劑量」指標不足以描述風險,研究設計必須明確界定暴露窗(exposure window)並對應發育時程——這也是生命歷程流行病學與「健康與疾病的發育起源(DOHaD)」假說的方法學核心。
混合暴露(mixtures):人不會只暴露於一種化學物質。多種汙染物可能呈現相加(additive)、協同(synergistic,效應大於各自相加)或拮抗(antagonistic)作用。傳統「一次評估一個」的監管模式會系統性低估真實風險。當代統計方法如加權分位數和迴歸(WQS regression)、貝氏核機器迴歸(BKMR),就是為了在高維度的化學混合資料中,估計整體混合效應並辨識主要驅動成分而發展的。
累積風險評估(cumulative risk assessment):把化學暴露與非化學壓力源(社會經濟劣勢、慢性壓力、醫療可近性)一併納入。這在概念上把入門談到的「環境正義」從描述性觀察,升級為可建模的框架——弱勢族群的「雙重負擔」不只是巧合的疊加,而是壓力源之間可能存在效應修飾(effect modification):同樣的鉛暴露,對處於慢性社會壓力下的兒童,神經毒性可能被放大。
從健康效應到政策決策:把生命放進成本效益表
走完前面所有步驟,我們得到了「可避免的疾病負擔」。最後一哩路,是把它轉成決策者能用的語言——通常是成本效益分析(cost–benefit analysis, CBA)。
這裡會碰到一個讓許多學生不安、卻無法迴避的概念:統計生命價值(value of a statistical life, VSL)。它常被誤解為「替某個人的命標價」,但其實是基於族群對「微小死亡風險變化」的支付意願(willingness to pay)所推導——例如,若 10 萬人各自願意付 100 元換取每人死亡風險降低十萬分之一,這個族群整體願意付 1,000 萬元來「避免一個統計上的死亡」,VSL 即為 1,000 萬元。它衡量的是風險的邊際價值,而非個體生命的尊嚴或內在價值。
有了 VSL(以及醫療成本、生產力損失等),就能把「可避免 3,880 死/年」乘上單位價值,得到空汙管制的健康效益貨幣值,再與管制的成本(產業改裝、能源轉型支出)相比。美國 1990 年《清淨空氣法》修正案的回溯評估是經典案例:分析估計其健康效益(主要來自 PM2.5 相關早死的減少)數十倍於成本——這類分析正是環境法規得以在政治經濟壓力下站穩腳跟的量化基礎。
但這條鏈也充滿價值判斷:VSL 該不該因國家所得不同而異(這會讓窮國的命「比較便宜」,引發嚴重倫理爭議)?未來世代的健康效益該用多高的折現率(discount rate)換算成現值?這些都不是純技術問題。進階環境衛生的成熟,正在於同時掌握量化工具,又清醒地看見工具背後的價值預設——並把這些預設攤在陽光下,接受民主審議,而非藏進一個看似客觀的數字裡。
動手試試:拆解一則「空汙死亡」新聞
下次你看到「研究指出空汙每年害死全國 X 千人」的報導時,試著用這套進階框架追問五個問題:
- 反事實是什麼? 這個 X 是相對於哪個 TMREL 算出來的?是相對於零暴露、自然背景值,還是現行標準?
- 相對風險曲線從哪來? 用的是本地世代研究,還是套用整合暴露—反應函數(含吸菸資料外推)?
- 重疊風險怎麼處理? 有沒有和吸菸、職業暴露的 PAF 重複計算?
- 暴露評估的解析度如何? 是用最近測站代表全縣市(高暴露錯分),還是時空模型?
- 不確定區間多寬? 點估計旁邊那條信賴區間,是 ±10% 還是 ±50%?
能流暢問完這五題,你就已經站在進階環境衛生的門檻上了——重點從來不是背下某個數字,而是有能力評估這個數字值不值得相信。
重點回顧
- 風險評估的四步驟框架(危害辨識、劑量—反應、暴露評估、風險特徵化)的核心價值,在於強制把不確定性攤開,讓每一步的假設都可被檢視,而非追求單一「正確答案」。
- 歸因負擔的本質是反事實:所有「空汙害死多少人」的數字,都是相對於一個假想的低暴露世界(TMREL)而言;PAF 把相對風險與人口暴露分布轉成可歸因比例,但多風險因子的 PAF 不可直接相加。
- 整合暴露—反應函數縫合了從乾淨空氣到吸菸的寬廣證據,使全球比較成為可能,但縫線(跨來源可比性、吸菸外推)本身就是假設與爭論點。
- 真實風險有三重複雜性:易感窗(時機重於總量)、混合暴露(協同/拮抗)、累積風險(化學與社會壓力源交互),單一物質、單一劑量的古典模型會系統性失真。
- 從健康效應到政策需經成本效益分析與統計生命價值(VSL),這把生命風險放進可比較的貨幣尺度,但 VSL 的跨國差異與折現率選擇是價值判斷,必須攤開接受公共審議。
深入探討(研究所視角)
進入研究所層次,前述每一個環節都會展開為一個方法學戰場,核心是量化不確定性與逼近因果這兩條主線的深化。
機率式風險評估與不確定性傳播取代了點估計思維。成熟的分析不會說「風險是 3,880 死」,而是用蒙地卡羅模擬(Monte Carlo simulation),讓暴露分布、相對風險係數、TMREL 等每個輸入各自帶著機率分布,反覆抽樣傳播,產出風險的整條後驗分布與信賴區間。更進一步,要區分偶然性不確定性(aleatory,族群內個體差異的本質隨機)與認識性不確定性(epistemic,源於知識不足、原則上可透過更多資料縮小)——兩者在決策上的意涵截然不同:前者要求穩健設計,後者指向值得投資的研究方向。價值資訊分析(value of information)甚至能量化「再多做一個研究、減少某項不確定性,對決策的期望價值有多大」,把研究經費配置本身也納入理性框架。
暴露評估的因果效度是慢性效應研究的阿基里斯腱。入門提過暴露錯分會使估計趨向虛無(bias toward the null),但研究所層次要進一步區分非差異性錯分(non-differential,通常稀釋效應)與差異性錯分(differential,可能朝任一方向偏倚,更危險),並用回歸校準(regression calibration)或貝氏測量誤差模型主動校正。同時,當暴露面本身是用統計模型(如土地利用迴歸、機器學習)「預測」出來的,把預測值當真值代入第二階段健康模型會低估標準誤——這需要兩階段測量誤差校正或貝氏階層模型把預測不確定性一路傳遞下去。
因果推論在環境脈絡的前沿,是把潛在結果框架(potential outcomes)與環境暴露的連續、空間自相關、無法隨機指派等特性結合。負對照(negative controls) 用來偵測殘餘混淆——若某個理論上不該受空汙影響的結果,卻和空汙呈現關聯,就暴露了未測量混淆的存在。差異中的差異(difference-in-differences)、斷點迴歸與合成控制法(synthetic control)在評估政策性自然實驗(如某城市突然的燃煤禁令)時各有適用情境與平行趨勢假設需要檢驗。對連續暴露,廣義傾向分數(generalized propensity score)可估計整條劑量—反應的因果曲線,而非僅僅二元的「暴露 vs 未暴露」對比。
跨尺度整合與行星健康則把環境衛生推向更大的系統。氣候變遷使暴露評估必須納入未來情境的不確定性(排放路徑、社會經濟發展),把流行病學的歸因模型與地球系統模式、整合評估模型(integrated assessment models)耦合,估算如熱浪超額死亡、病媒分布北移、糧食系統衝擊的健康負擔。這時,環境衛生與 Educational Omics 框架中的 Environomics(環境組學)形成清晰呼應——把光照、溫濕度、空品、社會壓力等多模態環境暴露,視為一個可長期追蹤、可與生理與認知資料整合的暴露面。對立志深耕此領域的學生而言,真正的訓練不在於記住任一個風險數字,而在於掌握一套從機制到貨幣、從點估計到不確定性分布、從關聯到因果的共通推理語言,並始終保有對「數字背後價值預設」的清醒——因為環境衛生最終要回答的,是一個既是科學、也是倫理與政治的問題:我們願意為了誰、付出多少,換取一個更健康的環境?