
為什麼一通電話、一張表單,能讓整座城市提前一週備戰?
從通報、監測到疫情調查,認識公共衛生如何在族群層次「看見」疾病動向,並把異常訊號轉化為提前一步的行動。
為什麼一通電話、一張表單,能讓整座城市提前一週備戰?
2003 年初,一位曾在中國廣東行醫、出差到香港的醫師入住九龍一家旅館。他不知道自己已經感染了一種前所未見的病毒。短短數日內,同一樓層的房客把這個後來被命名為「嚴重急性呼吸道症候群」(SARS, severe acute respiratory syndrome)的病原帶往越南、新加坡、加拿大。一場跨洲際的疫情,就在這個沒有人察覺的「指標個案」(index case)身上展開。
事後回顧,真正讓世界稍稍跟上病毒腳步的,不是某種特效藥,而是一套機制:越南河內一位世界衛生組織(WHO)的醫師卡洛‧厄巴尼(Carlo Urbani)注意到一群不尋常的非典型肺炎病例,立刻向上通報;WHO 隨即發出全球警示。這個「察覺異常—通報—示警」的流程,正是公共衛生最不起眼、卻最關鍵的基礎建設——疾病監測(disease surveillance)。
監測不是把病人治好,也不是發明疫苗。它做的事更前置:在族群(population)的層次上,持續地「盯著」疾病的動向,讓我們在疫情失控之前就看見它的影子。這篇文章,我們就從這個「為行動而觀察」的視角,認識監測、通報與疫情調查如何運作。
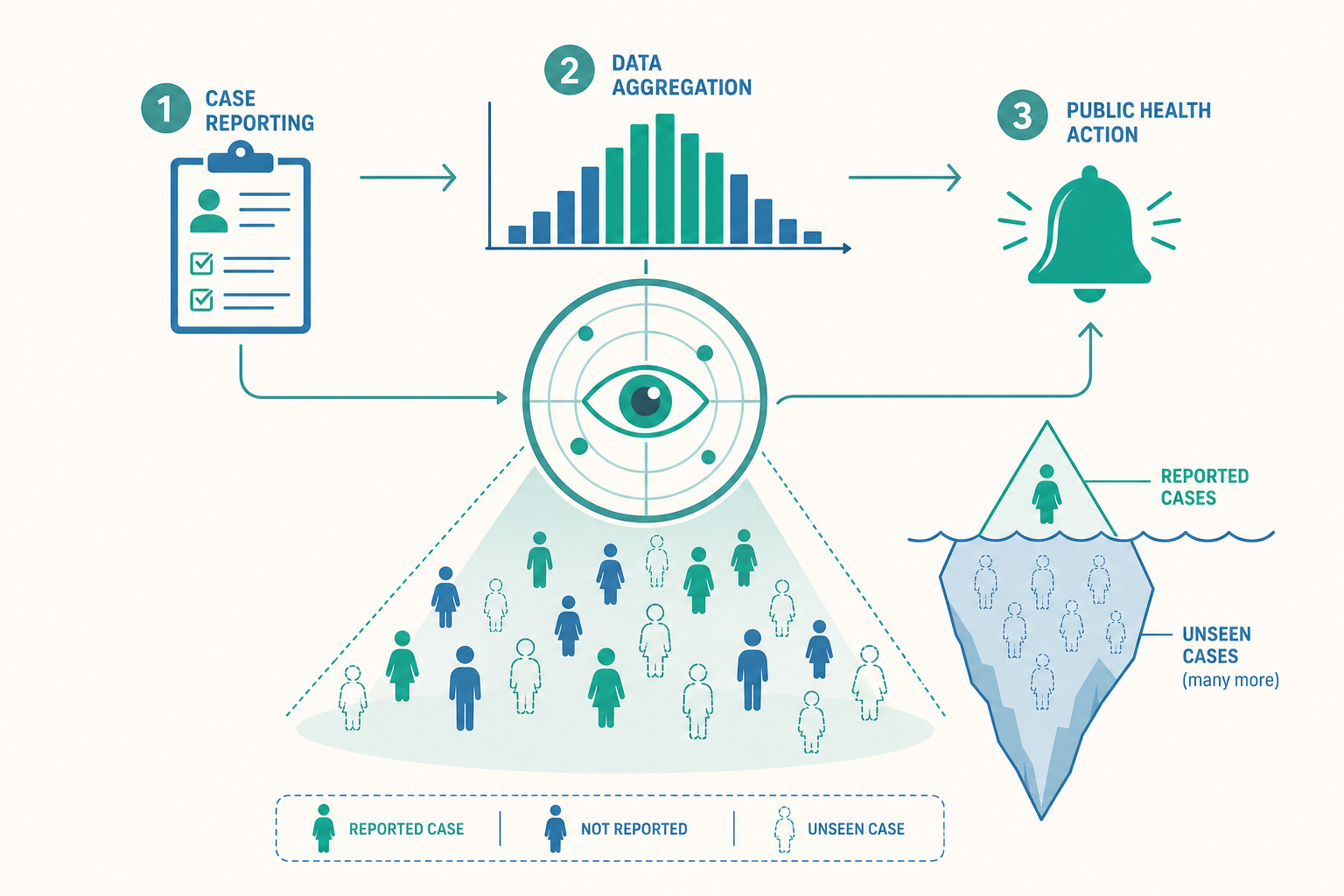
監測到底是什麼?一個被反覆引用的定義
公共衛生領域對監測最經典的定義,來自美國疾病管制與預防中心(CDC)的學者 Alexander Langmuir,後經多次精煉,核心精神是:對健康相關資料進行持續、系統的收集、分析與解讀,並將結果即時回饋給需要採取行動的人。
這個定義有四個關鍵詞,值得逐一拆開:
- 持續且系統(continuous and systematic):監測不是疫情爆發時才臨時去數人頭,而是一套常態運轉的制度。就像血壓計需要長期量測才能看出趨勢,疾病資料也必須長期、用一致的方法收集,異常才有「基準線」(baseline)可比對。
- 資料的收集與分析:監測收的不只是確診數,還包括發病日期、地點、年齡、職業、暴露史等。光有原始資料還不夠,必須經過分析(比如和歷年同期比較、計算發生率),數字才會「說話」。
- 解讀與回饋:這是最容易被忽略、卻定義了監測成敗的一環。Langmuir 有一句名言:監測的資料若沒有回到能採取行動的人手上,整套系統就失去意義。 收集了卻沒人看、看了卻沒人行動,等於沒做。
- 為了行動(for action):監測的終點永遠是公共衛生決策——要不要啟動疫調、要不要發布警示、疫苗該往哪裡配送、防疫物資該如何調度。
換句話說,監測是公共衛生系統的「神經末梢」與「預警雷達」。它本身不直接介入疾病,卻是所有介入的前提。
監測的種類:被動、主動,與它們之間的光譜
監測不是只有一種做法。依照「資料是被動地等上門,還是主動地去挖」,可以分成兩大類型,理解這個差異,是看懂防疫制度的關鍵。
被動監測(passive surveillance) 是最普遍、成本最低的形式。衛生機關事先公告一份「法定傳染病」清單,要求醫師、醫院、實驗室在診斷到這些疾病時,主動向衛生單位通報。資料像河水一樣自動流入系統,公衛人員「被動」地接收。台灣的法定傳染病通報、美國的 National Notifiable Diseases Surveillance System(NNDSS)都屬於這一類。
被動監測的優點是省人力、能廣泛覆蓋;缺點則是嚴重低估真實病例數。許多輕症病人從不就醫,就醫了醫師也未必想到該病、未必記得通報。流行病學界有個生動的比喻——監測金字塔(surveillance pyramid):被報告上來、出現在統計數字裡的病例,只是金字塔頂端的一小角;底下還有龐大的「就醫未通報」「有症狀未就醫」「無症狀感染」層層疊疊,構成看不見的冰山。
主動監測(active surveillance) 則反過來:衛生機關主動派人去醫院、實驗室、社區「找」病例,定期打電話或調閱紀錄詢問「最近有沒有某某疾病的個案」。它資料完整、準確,但耗費大量人力與經費,通常只在特定時期啟動——例如某疾病進入根除(eradication)最後階段(如小兒麻痺),或重大疫情爆發、需要精確掌握每一個個案時。
在這兩端之間,還有許多變形,反映出監測制度近數十年的演化:
- 哨點監測(sentinel surveillance):不追求蒐集「所有」病例,而是選定一批具代表性的「哨點」醫療院所,密切監測特定疾病。流感(influenza)的類流感(influenza-like illness, ILI)監測就是典型——少數哨點診所每週回報門診中類流感的比例,雖非全面普查,卻能靈敏地反映流行趨勢。
- 症候群監測(syndromic surveillance):不等確診,而是即時監測「症狀群」資料,例如急診的發燒、腹瀉、呼吸道症狀主訴數,甚至藥局的止瀉藥銷量。它犧牲了診斷的精確,換來速度——能在實驗室確診之前數天就察覺異常,特別適合生物恐怖攻擊或新興傳染病的早期預警。
- 實驗室監測(laboratory-based surveillance):以檢驗結果為核心,並進一步做病原體基因定序,追蹤病毒株的變異與傳播鏈。COVID-19 期間各國的變異株(如 Alpha、Delta、Omicron)追蹤,靠的就是這套「基因體監測」(genomic surveillance)。
- 事件型監測(event-based surveillance):相對於上述以個案數字為主的「指標型監測」(indicator-based),事件型監測廣泛掃描新聞、社群媒體、網路論壇、民眾通報中的「疫情訊號」。WHO 的 EIOS 系統、加拿大的 GPHIN 都是案例——它們能在官方統計尚未成形前,從一則地方新聞裡嗅到苗頭。
沒有哪一種監測「最好」。一個健全的防疫體系,往往是被動、哨點、症候群、實驗室、事件型多種監測並行,互相補位——被動監測廣而粗,哨點與症候群快而靈,主動與實驗室深而準。
一個好的監測系統,該長什麼樣子?
並非有了通報表單就叫監測。CDC 曾提出一組評估監測系統的屬性,幫助我們判斷一套系統的優劣。其中幾個彼此往往「魚與熊掌」,理解這些張力,才能看懂監測制度設計上的取捨。
- 靈敏度(sensitivity):能否抓到真正的病例?漏掉太多,預警就失靈。
- 及時性(timeliness):從發病到資料進入系統、再到示警,要多久?對急性傳染病而言,慢一天可能就差很多。
- 代表性(representativeness):報上來的病例,能否正確反映真實族群中的分布(人、時、地)?若某地區、某族群系統性地少報,會誤導資源分配。
- 陽性預測值(positive predictive value):被系統判定為「病例」的,有多少是真的?太多假警報會耗盡防疫人力的信任與精力。
- 簡單性(simplicity)與可接受性(acceptability):通報流程若太繁瑣,第一線醫護就不願配合,再精美的設計也是空談。
- 彈性(flexibility):面對全新的疾病(像當年的 COVID-19),系統能否快速調整定義、新增欄位?
這裡有個核心張力值得記住:靈敏度與及時性,常常和精確度(陽性預測值)相互拉扯。 症候群監測為了搶快、為了不漏接,會把警報門檻調低,代價是更多假警報;實驗室確診監測雖然準,卻慢。沒有完美的系統,只有「為了當前目的而做出的合理取捨」。設計監測制度,本質上是在這些屬性之間做工程權衡。
從通報到行動:疫情調查與流行曲線
監測像雷達,當它偵測到異常訊號——某地某病的病例數突然超過預期基準線——下一步就是疫情調查(outbreak investigation)。這是流行病學家把抽象數字轉化為具體行動的現場功夫。
教科書通常把疫情調查拆成大致這幾個步驟(順序可依情境調整,有時需同步進行):
- 確認疫情是否真的存在:先排除「假性增加」——是不是因為換了新的檢驗方法、加強了通報、或人口移入,才讓數字看起來變多?
- 確立並核實診斷:確認這些病例真的是同一種病。
- 建立病例定義(case definition)並找出病例:用「人、時、地、臨床表現」訂出明確標準(例如「某月某日後、某社區內、出現發燒合併腹瀉者」),據此系統性地搜尋所有符合的個案。病例定義太鬆會混入雜訊,太嚴會漏掉真個案。
- 描述性流行病學:依「人、時、地」整理病例——這就帶出疫調最核心的工具,流行曲線(epidemic curve)。
- 形成並檢驗假設:推測可能的傳染來源與途徑,常用病例對照或世代分析比較「有暴露」與「無暴露」者的發病差異。
- 採取控制與預防措施:移除汙染源、隔離病例、施打疫苗、發布衛教。
- 溝通與後續監測:向大眾與決策者說明,並持續監測確認疫情平息。
流行曲線是疫調的招牌工具:橫軸是發病日期、縱軸是病例數,把每個個案依發病時間堆疊成柱狀圖。曲線的「形狀」會洩漏疫情的傳播模式:
- 單一來源(point source):所有人在同一短時間內暴露於同一汙染源(如一場聚餐的受汙染食物),曲線會迅速竄升又快速回落,呈現單一陡峭高峰。高峰的時間,往往就是大家共同暴露的時刻。
- 持續共同來源(continuous common source):汙染源持續存在(如一口長期被汙染的水井),曲線會維持一段高原期,直到汙染被移除。
- 人傳人擴散(propagated):病原在人與人之間傳遞,曲線會出現一波接一波、間隔約等於潛伏期(incubation period)的數個高峰,像漣漪般擴大。
更巧妙的是,流行病學家可以反過來用流行曲線回推暴露時間。若已知某病的潛伏期(從暴露到發病的時間),把流行曲線的高峰往前推一個平均潛伏期,往往就能鎖定共同暴露事件發生的時段——這正是斯諾時代以降,流行病學「從結果倒推原因」的經典思路。
看一個例子:一場社區腹瀉疫情的解讀
讓我們用一個簡化的假想案例,把上面的概念串起來。
某縣市衛生局的症候群監測系統,在某週發現轄區內三家醫院急診的「急性腹瀉」主訴數,連續兩天超過歷年同期基準線的兩倍。這是雷達上的一個異常訊號——監測系統發揮了它「預警」的功能。
衛生局啟動疫調。流行病學家先確認這不是檢驗方式改變造成的假象,接著訂出病例定義:「該週內、居住於 A 社區、出現水樣腹瀉合併嘔吐者」。據此清查,共找到 68 例。把這 68 例依發病日期畫成流行曲線,呈現一個陡升陡降的單峰——典型的單一來源型態。
已知此類腸胃炎的平均潛伏期約 24 至 48 小時。把高峰往前推約一至兩天,剛好落在社區某活動中心舉辦聯誼餐會的日期。流行病學家接著做了一個小型回溯性世代分析,比較「有參加餐會」與「沒參加」者的發病率:
| 發病 | 未發病 | 合計 | 發病率 | |
|---|---|---|---|---|
| 有吃涼拌菜 | 60 | 40 | 100 | 60% |
| 沒吃涼拌菜 | 8 | 92 | 100 | 8% |
吃了涼拌菜者的發病率(60%)是沒吃者(8%)的 7.5 倍——這個相對風險(relative risk)強烈指向該道菜是嫌疑來源。檢體送驗後,在涼拌菜與部分病人糞便檢體中驗出同一種病原,傳播鏈就此閉合。
於是控制措施隨之而來:追查食材供應與保存流程、要求改善廚房衛生、對社區發布衛教。後續監測顯示一週後急診腹瀉數回到基準線,疫情判定平息。
請注意這整個流程的邏輯:監測偵測異常 → 疫調建立病例定義 → 流行曲線判斷傳播模式 → 分析性比較鎖定來源 → 採取行動 → 持續監測確認。 每一環都不能少。少了監測,疫情可能拖到很大才被發現;少了疫調的分析,就只能知道「有很多人拉肚子」卻找不出元凶。
監測的限制與倫理:被看見的代價
監測是強大的工具,但不是萬能,也不是沒有代價。一位成熟的公衛工作者必須同時看見它的力量與它的邊界。
資料品質的天花板。前面提過的監測金字塔提醒我們:通報數字幾乎永遠低估真實疫情。通報的完整性、及時性、各地一致性,都會影響數字的可信度。通報數上升,有時反映的是「監測加強」而非「疫情惡化」——疫情初期擴大篩檢,確診數自然跳升,這時把它直接解讀成病毒大爆發,可能誤判。看監測數字,永遠要問「分母是什麼、通報行為有沒有改變」。
隱私與自主的張力。監測本質上是國家對個人健康資訊的系統性收集。法定傳染病通報往往不需要病人個別同意——因為公共衛生的集體利益,在法律上被認為可以正當地限縮個人的資訊自主。但這份權力必須謹慎行使:資料去識別化、嚴格限定使用目的、明確的保存與銷毀規範,都是維繫社會信任的底線。一旦民眾擔心通報會帶來歧視或不利後果(例如愛滋、性病的污名化),就可能隱匿病情、迴避就醫,反而讓監測失靈。信任,是監測系統看不見卻最珍貴的基礎建設。
公平性的盲點。監測若系統性地「看不見」某些族群——沒有健保、不敢就醫的移工,醫療資源匱乏地區的居民——這些族群的疾病負擔就會在數字上被低估,連帶在資源分配上被忽略。監測呈現的「疾病地圖」,某種程度上也是「醫療可近性的地圖」。讀監測資料時保持這份警覺,是公共衛生倫理素養的一部分。
從河內那位醫師的一通通報電話,到今日跨國的基因體監測網絡,疾病監測始終在做同一件事:讓族群層次的疾病動向變得「可見」,好讓人類能夠提前一步行動。 它安靜、不起眼,卻是守在公共衛生最前線的那雙眼睛。
重點回顧
- 監測是對健康資料的持續、系統收集、分析與回饋,終點是公共衛生行動——資料若沒回到能行動的人手上,整套系統就失去意義。
- 被動監測廣而省力但低估病例,主動監測準確但昂貴;哨點、症候群、實驗室、事件型監測各有所長,健全體系靠多種並行互補。
- 好的監測系統在靈敏度、及時性與精確度之間權衡——搶快不漏接(如症候群監測)就得容忍更多假警報,精確(如實驗室確診)就得忍受較慢。
- 疫情調查靠流行曲線判讀傳播模式:單峰指向單一來源、高原期指向持續來源、多波次指向人傳人;高峰往前推一個潛伏期可回推暴露時間。
- 監測數字永遠是冰山一角,且承載隱私與公平的倫理張力——通報增加可能來自監測加強,看不見的族群可能正是疾病負擔最重的族群。
深入探討(研究所視角)
進入研究所層次,疾病監測從「一套通報制度」升級為一個融合統計學、計算科學與決策理論的研究領域。其核心問題可以濃縮成一句:如何從不完整、有偏誤、且持續更新的資料流中,及時且穩健地推斷疫情的真實狀態。
異常偵測的統計化。「病例數超過預期」這句話需要嚴謹的統計定義。傳統的 CUSUM(累積和管制圖)、EWMA(指數加權移動平均)源自工業品管,被移植來偵測症候群監測中的異常激增;Farrington 演算法及其後續改良,則考慮了季節性、長期趨勢與過去爆發的污染,成為歐洲多國症候群監測的標準工具。這裡的核心張力是統計檢定的老問題——第一型與第二型錯誤的權衡:警報門檻訂太低,假警報淹沒防疫人力(alarm fatigue);訂太高,則錯失早期介入的黃金窗口。
即時估計與右設限(right censoring)。疫情進行中所看到的監測曲線,最近幾天的數字幾乎一定被低估,因為許多個案尚未通報完成——這就是通報延遲(reporting delay)造成的「右設限」問題。直接拿最新數字解讀,會誤以為疫情正在下降。回填(nowcasting) 方法(如貝氏階層模型、廣義加成模型 GAM)試圖根據歷史延遲分布,估計「最終會被通報上來的真實數字」,是當代即時流行病學(real-time epidemiology)的關鍵技術。COVID-19 期間,有效再生數(effective reproduction number, $R_t$) 的即時估計即深受此問題困擾——它對通報延遲、檢驗量能變化、序列間隔(serial interval)假設都極為敏感,這也是為何同一波疫情、不同團隊估出的 $R_t$ 可能有所差異。
多重來源整合與數位流行病學。當代監測不再只靠單一管道。資料融合(data fusion) 試圖整合臨床通報、實驗室、廢水監測(wastewater-based epidemiology,無視通報行為直接量測社區病原載量)、乃至搜尋引擎與社群媒體訊號。Google Flu Trends 的興衰是經典教案:它一度展示了搜尋資料預測流感的潛力,卻也因「大數據傲慢」(big data hubris)與演算法漂移,在某些季節大幅高估疫情,提醒我們數位代理指標(digital proxy)必須與傳統監測校準、不可取而代之。廢水監測則在 COVID-19 後快速成熟,因其不受就醫與通報行為影響,能繞過監測金字塔的低估問題,成為極具前景的「客觀」社區指標。
基因體監測與系統發生學。次世代定序(next-generation sequencing)讓監測從「數人頭」進入「讀傳播鏈」。分子流行病學(molecular epidemiology) 透過病原基因序列的系統發生樹(phylogenetic tree),重建誰傳給誰、病毒何時何地起源、變異株如何擴散。GISAID 這類全球共享平台,使各國得以近乎即時地追蹤 SARS-CoV-2 變異。但這也帶出新的倫理與治理難題:定序資料的跨國共享、智慧財產、以及對來源國的公平回饋(如過往對伊波拉、流感病毒樣本主權的爭議),都是全球衛生治理的前沿議題。
從預警到決策的最後一哩。監測研究的終極價值,在於連接到行動。資訊價值分析(value of information) 與決策理論被用來回答:投入多少資源加強監測、把警報門檻訂在哪裡,才能在「漏報的代價」與「假警報的成本」之間取得最適平衡。這讓監測從一門「觀察的技術」,提升為一門「決策的科學」。
回到那通通報電話。值得深思的是,無論統計模型多麼精巧、定序多麼快速,2003 年阻止 SARS 進一步失控的關鍵,仍是一位臨床醫師「覺得不對勁」並選擇通報的判斷。最先進的監測系統,第一個感測器始終是第一線醫護的專業警覺與通報意願。技術可以放大訊號、加速分析、整合來源,卻無法取代那份「察覺異常、願意說出來」的人為起點。疾病監測的未來,是讓人的警覺與機器的運算彼此增益——而非用後者取代前者。