
為什麼同一間醫院、同一條街,得病的人卻有「規律」?
從約翰‧斯諾的霍亂地圖出發,理解流行病學如何在族群中尋找疾病的分布、決定因子,並把證據轉化為公共衛生行動。
為什麼同一間醫院、同一條街,得病的人卻有「規律」?
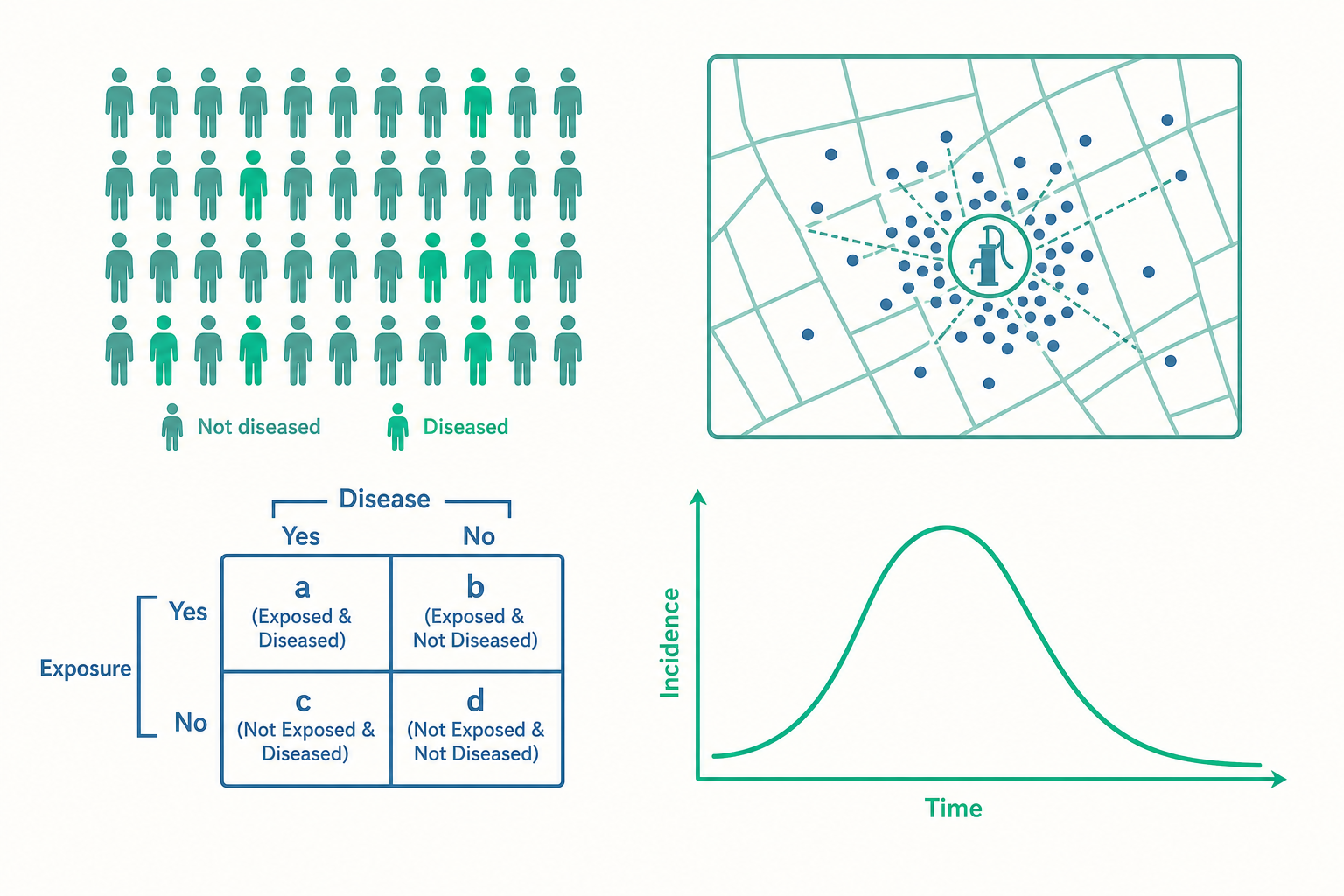
1854 年的倫敦蘇活區(Soho),霍亂(cholera)在十天內奪走五百多條人命。當時的主流理論認為疾病來自「瘴氣」(miasma)——空氣中的腐臭之氣。一位名叫約翰‧斯諾(John Snow)的醫師卻不相信。他做了一件在今天看來理所當然、在當時卻革命性的事:他拿著一張地圖,把每一個死亡個案的住址標上去。
當這些黑點疊在地圖上,一個模式浮現了——死亡個案密集地環繞著百老街(Broad Street)上的一座公用水泵。斯諾進一步追問那些「住得近卻沒病」的人,發現他們喝的是別處的水;而住得遠卻染病的人,往往恰好路過、喝過那座水泵的水。他說服當地官員拆掉水泵的把手,疫情迅速平息。
斯諾並不知道霍亂弧菌(Vibrio cholerae)長什麼樣——細菌學要再過幾十年才成熟。他靠的不是顯微鏡,而是一種思考方式:疾病不是隨機降臨,它在族群(population)中有分布(distribution),而這個分布背後有可被找出的決定因子(determinant)。 這正是流行病學(epidemiology)的核心精神。這篇文章,我們就從這個「在人群中尋找模式」的視角出發。
流行病學到底在研究什麼?
流行病學最被廣泛接受的定義,來自學者 John Last:研究特定族群中健康相關狀態或事件的分布與決定因子,並將研究成果應用於健康問題的控制。 這個定義雖然拗口,但每個詞都有重量,值得拆開來看。
- 族群(population):流行病學的眼睛永遠看著「一群人」,而不是單一病人。臨床醫師問「這位病人為什麼生病」;流行病學家問「為什麼是這群人、在這個時間、以這個比率生病」。
- 分布(distribution):疾病如何依「人、時、地」(person, place, time)三個維度散佈。誰得病多(年齡、性別、職業、社經地位)?什麼時候爆發(季節、年代趨勢)?哪裡盛行(城鄉、國家、特定建築)?這部分稱為描述性流行病學(descriptive epidemiology)。
- 決定因子(determinant):是什麼造成了這樣的分布?暴露(exposure)與結果(outcome)之間有沒有因果關聯?這部分稱為分析性流行病學(analytic epidemiology)。
- 應用於控制:流行病學不是為了求知而求知。它的終點是公共衛生行動——拆掉水泵的把手、推動疫苗、修法、調整篩檢政策。
簡言之,流行病學是公共衛生的「基礎科學」與「方法論工具」。其他公衛領域(環境衛生、健康政策、衛生教育)都仰賴它提供證據。
先學會數人頭:發生率與盛行率
流行病學最基本的功夫,是把「有多少人生病」精確地量化。最常被混淆的兩個指標是發生率(incidence)與盛行率(prevalence)。
盛行率回答的是:「在某一個時間點,族群中有多少比例的人『正處於』患病狀態?」它像是對人群拍一張快照。
$$\text{盛行率} = \frac{\text{某時點現有病例數}}{\text{該時點總人口數}}$$
發生率回答的是:「在一段觀察期間內,原本沒病的人當中,有多少『新發生』了疾病?」它像是一段影片,記錄新事件冒出來的速度。
$$\text{累積發生率} = \frac{\text{觀察期間新發病例數}}{\text{期初有風險的人口數}}$$
兩者的關係可以用一個經典比喻:想像一個浴缸。發生率是水龍頭流入的新水(新病例),盛行率是浴缸裡現有的水量(現有病例),而排水口則是「痊癒」或「死亡」(病例離開患病狀態)。一個粗略但實用的關係式是:
$$\text{盛行率} \approx \text{發生率} \times \text{平均病程}$$
這解釋了一個常見的迷思。假設醫學進步讓某慢性病的死亡率下降,病人活得更久——這時盛行率會上升(浴缸的水放得慢,水位變高),但這並不代表病「變多了」或預防失敗。事實上,治療成功反而推高了盛行率。所以評估預防成效要看發生率,評估醫療與照護負擔則常看盛行率。混淆兩者,會做出完全相反的政策判斷。
衡量關聯:相對風險與勝算比
描述完分布,流行病學家想知道暴露與疾病之間有沒有關聯,以及關聯有多強。這裡有兩個核心測量。
相對風險(relative risk, RR),又稱風險比(risk ratio):暴露組的發病風險,是非暴露組的幾倍。
$$RR = \frac{\text{暴露組發生率}}{\text{非暴露組發生率}}$$
RR = 1 代表暴露與疾病無關;RR > 1 代表暴露增加風險(可能是危險因子);RR < 1 代表暴露降低風險(可能具保護作用,如疫苗)。例如「吸菸者罹患肺癌的風險是不吸菸者的 15–30 倍」,就是用相對風險表達。
勝算比(odds ratio, OR):在無法直接計算發生率的研究設計(特別是後面會講的病例對照研究)中使用,比較的是「暴露的勝算」而非「發病的風險」。當疾病很罕見時,OR 是 RR 的良好近似。
要特別提醒一個常見錯誤:相對風險大,不代表絕對影響一定大。 若某暴露讓一個罕見疾病的風險從十萬分之一變成十萬分之二,相對風險是 2(翻倍,聽起來嚇人),但絕對風險差(absolute risk difference)只增加十萬分之一,實際衝擊極小。新聞標題常只報「風險增加一倍」而隱去基準值,這是解讀健康資訊時要保持警覺的地方。
看一個例子:用 2×2 表算一次
假設我們追蹤一群人,想知道「常吃加工肉品」與「大腸癌」的關聯。整理成流行病學最常用的 2×2 列聯表:
| 罹患大腸癌 | 未罹患 | 合計 | |
|---|---|---|---|
| 常吃加工肉品 | 90 | 910 | 1000 |
| 不常吃 | 30 | 970 | 1000 |
暴露組(常吃)的發病風險 = 90 / 1000 = 0.09(9%) 非暴露組(不常吃)的發病風險 = 30 / 1000 = 0.03(3%)
相對風險 $RR = 0.09 / 0.03 = 3.0$。
解讀:在這份假想資料中,常吃加工肉品者罹患大腸癌的風險是不常吃者的 3 倍。而絕對風險差 = 9% − 3% = 6%,意味著每 100 位常吃者中,「多出」約 6 位因暴露而罹病(若關聯為因果)。
請注意「若關聯為因果」這個但書——算出 RR 只是第一步,它告訴你「有關聯」,但還不能直接斷言「是它造成的」。要跨越這道坎,得處理偏誤、干擾與因果推論,這正是流行病學最精彩也最困難的部分。
研究設計:流行病學家的工具箱
流行病學家不能像實驗室那樣隨意「指派」人去吸菸或染病——這既不倫理也不可行。於是發展出一系列觀察性與實驗性研究設計,各有長短。
- 生態學研究(ecological study):以「群體」為分析單位,比較不同國家或地區的平均暴露與平均疾病率。優點是快、便宜;致命弱點是生態謬誤(ecological fallacy)——群體層次的關聯不能直接推論到個人。例如「平均紅酒消費高的國家心臟病死亡率低」,不代表「多喝紅酒的個人就更健康」。
- 橫斷面研究(cross-sectional study):在某時間點同時測量暴露與疾病,適合估計盛行率。缺點是無法判斷時序——分不清是「先暴露後生病」還是「生病後才改變行為」。
- 病例對照研究(case-control study):先找一群有病的人(case)與一群沒病的人(control),回溯比較兩組過去的暴露。適合研究罕見疾病,省時省錢,但容易有回憶偏誤(recall bias)。只能算勝算比。
- 世代研究(cohort study):先依暴露狀態分組,往前追蹤誰發病。能確立時序、可直接算發生率與相對風險,是觀察性研究的黃金標準;但耗時、昂貴,研究罕見疾病時效率差。
- 隨機對照試驗(randomized controlled trial, RCT):研究者隨機分配介入(如疫苗 vs 安慰劑)。隨機化能平均掉已知與未知的干擾因子,是因果推論證據力最強的設計;但成本高、且許多暴露(如吸菸、空汙)基於倫理無法做 RCT。
沒有哪一種設計「最好」——選擇取決於研究問題、疾病罕見程度、時間與經費。優秀的流行病學家懂得依情境挑工具。
關聯不等於因果:偏誤與干擾
這是整個流行病學最該牢記的一句話:Correlation is not causation(相關不等於因果)。 一個觀察到的關聯,可能來自三種「假象」:
- 機遇(chance):純粹的隨機波動。這靠統計檢定與信賴區間來評估(接優統計)。
- 偏誤(bias):研究設計或執行的系統性錯誤。常見的有選樣偏誤(selection bias,研究對象不能代表母體)與資訊偏誤(information bias,暴露或結果測量不準,如回憶偏誤)。偏誤一旦發生,再大的樣本也救不回來。
- 干擾(confounding):第三個變項同時與暴露和疾病相關,混淆了真正的關聯。
干擾值得多說一點,因為它最隱蔽。經典例子:研究發現「帶打火機的人肺癌風險高」。難道打火機致癌?當然不是——吸菸才是干擾因子,它既與「帶打火機」相關,又是肺癌的真正成因。若不調整吸菸,就會得出荒謬結論。流行病學以分層分析、配對、多變項迴歸、傾向分數等方法來「控制」干擾。
為了系統性地判斷一個關聯是否為因果,流行病學家常參考 Bradford Hill 準則(1965 年提出)的幾個面向:關聯強度(strength)、一致性(consistency,不同研究是否都看到)、時序性(temporality,因必須在果之前——這是唯一不可或缺的條件)、劑量反應關係(dose-response,暴露越多風險越高)、生物合理性(biological plausibility)等。這些不是機械式的檢核表,而是幫助研判因果的思考架構。
動手試試:找出可能的干擾因子
下次你看到一則健康新聞——「研究發現每天喝咖啡的人比較長壽」——別急著去囤咖啡豆。試著問自己三個問題:
- 這是什麼研究設計? 是追蹤多年的世代研究,還是只看某一時點的橫斷面?能不能確立時序?
- 有沒有可能的干擾因子? 會固定喝咖啡的人,是不是也比較可能有穩定收入、規律作息、就醫方便?這些「健康使用者」特質本身就影響壽命。
- 報導的是相對風險還是絕對風險? 「降低 X% 風險」的基準值是多少?
光是養成這套提問習慣,你解讀健康資訊的能力,就已經超越大多數人了。這也正是流行病學素養(epidemiological literacy)的價值——它不只服務研究者,更是每位公民面對排山倒海的健康訊息時的防身術。
從個案到政策:流行病學的公衛應用
回到斯諾的水泵。流行病學最終要回答「所以我們該做什麼」。幾個族群層次的應用值得認識:
- 疾病監測(surveillance):持續、系統地收集疾病資料,及早偵測異常。COVID-19 期間的每日確診數、Rt 值(有效再生數)都是監測產物。
- 疫情調查(outbreak investigation):當疫情爆發,流行病學家會繪製流行曲線(epidemic curve,以時間為橫軸、病例數為縱軸),從曲線形狀推斷是單一來源(共同暴露)還是人傳人擴散,並回推可能的暴露時間。
- 族群歸因危險度(population attributable risk):估計「若消除某暴露,族群中可避免多少疾病」,這直接指引預防資源該投向哪裡。
- 篩檢評估:流行病學提供敏感度、特異度、陽性預測值等指標,判斷一項篩檢值不值得大規模推行——並警惕前導時間偏誤(lead-time bias)等陷阱,避免把「提早診斷」誤認為「延長壽命」。
從吸菸與肺癌的世代研究,到食品安全、空氣汙染、慢性病防治、乃至全球大流行的應對,流行病學一次次把零散的個案,轉化為可以行動的族群層次證據。
重點回顧
- 流行病學研究疾病在族群中的分布與決定因子,並將證據用於健康問題的控制——它是公共衛生的方法論基礎。
- 發生率衡量「新發生」、盛行率衡量「現存」;盛行率 ≈ 發生率 × 病程,混淆兩者會做出相反的政策判斷。
- 相對風險表達關聯強度,但要同時看絕對風險差,否則容易被「風險翻倍」的標題誤導。
- 研究設計各有取捨:生態、橫斷面、病例對照、世代到 RCT,證據力與成本/可行性需權衡。
- 關聯不等於因果:機遇、偏誤、干擾是三大假象來源;判斷因果要靠研究設計與 Bradford Hill 準則,其中時序性不可或缺。
深入探討(研究所視角)
進入研究所層次,流行病學的核心張力可以濃縮為一句話:如何從觀察性資料中,逼近一個本質上屬於「反事實」(counterfactual)的因果問題。
因果推論的形式化框架。當代流行病學的理論支柱是 Rubin 的潛在結果(potential outcomes)框架與 Pearl 的結構性因果模型(structural causal model)。「某暴露對某人的因果效應」被定義為:同一個體在「暴露」與「未暴露」兩種平行世界下結果的差。問題在於,任一個體只能被觀察到一種狀態(the fundamental problem of causal inference),另一半永遠是反事實的。隨機化之所以強大,是因為它讓暴露組與非暴露組在期望上可交換(exchangeability),使群體平均的反事實得以估計。觀察性研究則必須靠「可測量的干擾因子皆已調整」這個無法被驗證的假設(conditional exchangeability / no unmeasured confounding)來逼近。
DAG 與後門準則。有向無環圖(directed acyclic graph, DAG)讓我們把因果假設畫成圖,並依 Pearl 的後門準則(back-door criterion)系統性地判斷「該調整哪些變項、不該調整哪些」。這帶出一個違反直覺、卻極其重要的陷阱——對撞因子偏誤(collider bias):若一個變項是暴露與結果共同的「果」(collider),對它做調整或選樣,反而會憑空製造出虛假關聯。著名的「肥胖悖論」與部分 COVID 早期住院資料中「吸菸者重症較少」的反常發現,都被認為可能源於 collider bias(以「住院」為選樣條件,而住院同時受暴露與結果影響)。這說明「調整越多變項越好」是錯的——調錯變項會引入偏誤。
中介與效應修飾。研究所階段會進一步區分干擾(confounding,要調整)、中介(mediation,在因果路徑上,調整它等於擋住部分效應,不該盲目調整)與效應修飾/交互作用(effect modification,效應大小隨第三變項而變,要呈現分層結果而非消去)。因果中介分析(causal mediation analysis)把總效應分解為直接效應與間接效應,是當代社會流行病學探討「機制」的利器。
進階方法與跨領域連結。當「無未測量干擾」假設站不住腳時,流行病學借助計量經濟學的工具箱:工具變項(instrumental variable,如孟德爾隨機化 Mendelian randomization,以基因變異作為暴露的天然隨機分配工具)、雙重差分(difference-in-differences)、斷點迴歸(regression discontinuity)、傾向分數(propensity score)等。生物統計則貢獻了存活分析(Cox 比例風險模型)、廣義估計方程(GEE)與處理時變干擾的邊際結構模型(marginal structural model)。近年,因果機器學習(如 targeted maximum likelihood estimation, TMLE;causal forests)試圖在高維資料中estimating異質性處理效應,把流行病學、統計學習與資料科學進一步交織。
回到斯諾。值得玩味的是,斯諾在沒有 RCT、沒有迴歸、甚至不知病原的情況下,已經直覺地運用了時序性、劑量反應(喝水多寡)、以及一個近乎「天然實驗」的設計——蘇活區後續另一項研究中,他比較兩家供水公司(一家取自汙染河段、一家取自上游)的用戶死亡率,這在今天看來幾乎就是工具變項或自然實驗的雛形。一百七十年後,流行病學的數學工具已遠超當年,但那個最初的提問始終未變:這群人為什麼生病,而我們能做些什麼? 從一張標滿黑點的地圖,到結構性因果模型,流行病學始終是一門「為了行動而求真」的科學。