
如果限值是「安全線」,為什麼它每隔幾年就往下修一次?
拆解職業暴露限值背後的劑量—反應數學、閾值之爭與風險評估四步驟,看清一個數字如何內建了百倍的不確定性餘裕。
如果限值是「安全線」,為什麼它每隔幾年就往下修一次?
讀過職業衛生入門的人,都會記得一個關鍵句子:暴露限值(如 PEL、TLV)是行政管制門檻,不等於絕對安全線。但這句話如果只當成一個免責聲明背下來,就錯失了它真正的份量。真正該追問的是:這條線究竟是怎麼畫出來的? 為什麼結晶型二氧化矽(crystalline silica)的容許暴露濃度,在過去半世紀被多個國家一修再修、而且每次都是往下調?為什麼有些物質(如苯、石綿)最後的科學共識是「沒有真正安全的閾值」?
要回答這些問題,就必須走進職業衛生的兩個硬核引擎:劑量—反應關係(dose-response relationship)的數學形式,以及建立在其上的正式風險評估(risk assessment)程序。入門篇告訴你「風險 ≈ 危害 × 暴露」這個直覺式公式;進階篇要拆開這個約等號,看清楚從一筆筆暴露測值,到一條曲線,再到一個被寫進法規的數字,中間究竟發生了哪些推論、做了哪些假設、又埋了哪些不確定性。理解這條推導鏈,你才能真正讀懂——也才能合理地質疑——任何一個職業暴露標準。
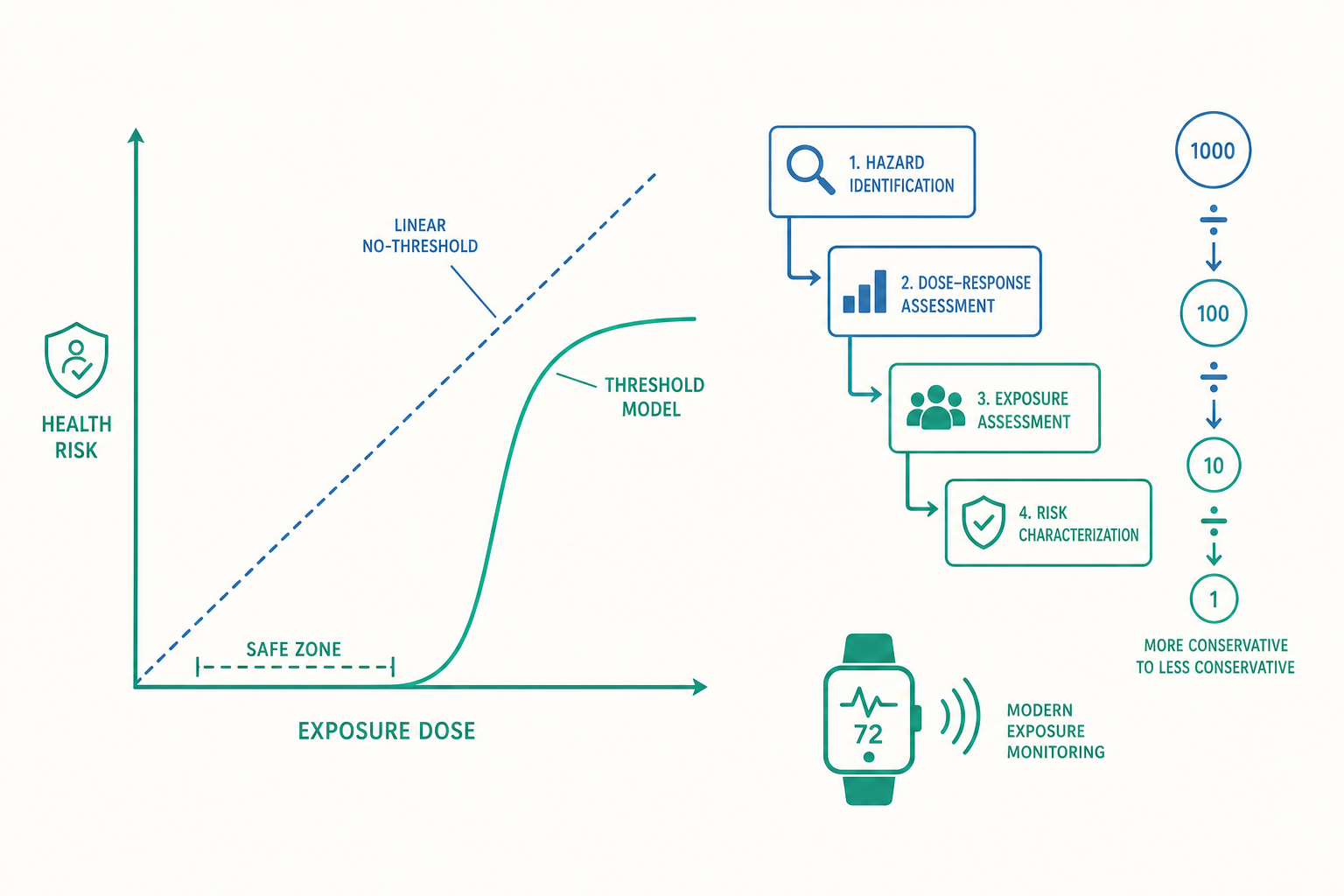
不是「有沒有暴露」,而是「暴露的形狀」:劑量—反應的數學
入門時我們把暴露簡化成一個 TWA(time-weighted average,時量平均濃度)數值,方便和限值比較。但這個簡化掩蓋了一個更深的問題:同樣的「總暴露量」,分布方式不同,傷害會一樣嗎?
考慮兩位勞工,累積暴露總量相同:
- 甲:每天暴露 50 ppm、持續 40 年。
- 乙:每天暴露 200 ppm、但只做 10 年。
兩者的「濃度 × 時間」乘積相等。它們的健康風險是否等價?答案取決於這個物質遵循哪一種劑量學規律。
哈伯法則(Haber's rule) 是最早的經驗式概化:對某些(特別是急性、可逆性的氣體中毒)物質,毒性效應由 C × t(濃度 × 時間) 的乘積決定,亦即上述甲乙風險相當。這個法則源自第一次世界大戰毒氣研究,至今在急性吸入毒理仍是有用的一階近似。但它的適用範圍其實很窄。對許多慢性、累積性、或具修復機制的危害,真實關係偏離 C × t 甚遠,需要修正為 Cⁿ × t(n ≠ 1)。當 n > 1,代表「高濃度短時間」遠比「低濃度長時間」危險(濃度本身是放大因子,例如某些刺激性或腐蝕性效應);當 n < 1,則時間的角色更吃重。
對職業衛生的操作意涵很直接:只看 TWA 而忽略峰值(peak exposure),可能嚴重低估某些危害。 這正是為什麼除了 8 小時 TWA,許多標準另設短時間暴露限值(short-term exposure limit, STEL,通常 15 分鐘) 與最高容許濃度(ceiling,任何瞬間都不得超過)。一個 TWA 合規、卻反覆衝出短時高峰的作業環境,在某些毒理機制下完全不安全。學會問「這個危害的劑量學是 C×t、還是 Cⁿ×t、還是有閾值、還是無閾值」,是從入門邁向進階的分水嶺。
閾值之爭:為什麼石綿、苯沒有「安全劑量」
劑量—反應曲線的低劑量端形狀,是整個風險評估中爭議最大、政策後果最重的部分,因為現實中勞工的暴露往往落在這個低劑量區,而流行病學研究在這裡的統計檢力卻最弱。學界傳統上分兩大陣營:
- 有閾值模型(threshold model):存在一個「無可觀察不良效應劑量(no observed adverse effect level, NOAEL)」,低於它身體的修復、解毒、代償機制足以抵消傷害,效應為零。多數非致癌、系統性毒性(如器官損傷、神經毒性)被認為屬於此類——曲線呈 S 形,左下角貼著零軸有一段「安全地帶」。
- 無閾值模型(non-threshold / linear no-threshold, LNT):任何劑量、哪怕極微,都帶有按比例增加的風險,曲線從原點起就是一條向上的直線,沒有安全地帶。基因毒性致癌物(genotoxic carcinogens) 與游離輻射被廣泛採用此一保守假設——其機制是單一分子或單一光子即可造成 DNA 突變,理論上不存在「零風險劑量」。
石綿與間皮瘤(mesothelioma)、苯與白血病,正是被歸入無閾值致癌物的經典案例。這就是為什麼這些物質的管制邏輯不是「守住某個安全濃度」,而是「盡可能降到技術上可行的最低(as low as reasonably achievable, ALARA)」——因為按 LNT 假設,每降低一分暴露都還在減少風險,永遠沒有「已經夠安全、可以鬆手」的那一刻。
值得強調的是:閾值之有無,往往無法單靠流行病學資料直接證明(低劑量區的超額風險小到被背景雜訊淹沒),而是結合毒理機制、動物實驗外推與科學保守原則所做的政策性判斷。這正是文章開頭那個問題的部分答案——限值會往下修,常常是因為新證據讓「假設有閾值」變得難以維持,或低劑量端的曲線被重新估計。
從曲線到法規:風險評估的四步驟
把劑量—反應的科學,轉成一個能寫進法律的數字,靠的是一套國際通用的風險評估四步驟框架(源自美國國家研究委員會 1983 年的「紅皮書」典範,至今仍是骨幹):
- 危害辨識(hazard identification):這個物質「能不能」造成特定健康效應?證據來自人類流行病學、動物實驗、體外試驗(如致突變性測試)與結構活性分析。國際癌症研究署(IARC)將物質分為 1(確定致癌)、2A、2B、3 等級,做的就是這一步——注意它回答的是「危害有無」,不回答「在多少劑量下」。
- 劑量—反應評估(dose-response assessment):「多少劑量造成多大效應」?在這步建立前面討論的那條曲線,並決定用閾值或無閾值模型。
- 暴露評估(exposure assessment):目標族群「實際接觸了多少」?整合空氣採樣、生物偵測、工作—暴露矩陣(job-exposure matrix)與暴露窗(exposure window)設定,重建累積劑量。
- 風險特徵化(risk characterization):把前三步綜合,估計「這個族群在這個暴露下,預期會多出多少病例」,並誠實交代不確定性的方向與量級。
這個框架最關鍵的價值,在於它強制把「科學評估」與「管制決策(risk management)」分開。第二步算出的「每暴露一單位增加多少癌症風險」是科學問題;但「社會願意接受多高的殘餘風險、願意付多少成本去降它」是價值與經濟問題,屬於政策範疇。把這兩件事混為一談,是公共衛生論辯中最常見的謬誤——當有人說「科學證明這個濃度是安全的」,往往他其實是把一個夾帶了價值判斷的管制門檻,偽裝成純客觀的科學結論。
不確定性如何被「內建」進限值:基準劑量與不確定係數
風險評估不只是算曲線,更要把不確定性顯式地納入安全餘裕。現代毒理用兩個工具完成這件事。
第一,從 NOAEL 走向基準劑量(benchmark dose, BMD)。傳統做法是從實驗資料挑出最高的「無不良效應劑量」NOAEL 當起點,但它有個致命弱點:NOAEL 只能是實驗中「剛好測過」的某個劑量點,受實驗設計與樣本數左右——樣本越小,越容易因檢力不足而把有害劑量誤判為「無效應」,反而得到看似寬鬆的起點。BMD 改用全部資料點配適一條曲線,反推「使不良反應率上升某個預設幅度(如 5% 或 10%)所對應的劑量」,並取其信賴區間下限(BMDL)為起點。它更穩健、更充分利用資料,已成為國際趨勢。
第二,套用不確定係數(uncertainty factors, UF),把實驗起點除以一連串安全係數,得到供人類使用的參考劑量或可接受暴露:
參考劑量 = 起點劑量(NOAEL 或 BMDL)÷(UF₁ × UF₂ × …)
每個係數對應一種已知的不確定性來源,慣例上常各取 10 倍:
- 動物外推到人(interspecies,約 ×10):人類可能比實驗動物更敏感。
- 人群內個體差異(intraspecies,約 ×10):兒童、孕婦、慢性病者、基因易感者比「健康成年男性」脆弱。
- 視情況再加:以 LOAEL 代替 NOAEL(沒測到無效應劑量時)、資料品質不足、效應為嚴重不可逆等,各再乘上額外係數。
把這些係數相乘,總不確定係數常達 100、1000 甚至更高。這正是限值之所以「保守」的數學來源——它不是科學家對「真實危險劑量」的最佳猜測,而是在最佳猜測之下,又主動退讓了一兩個數量級當緩衝。理解這點能化解一個常見迷思:超過限值不代表「立刻中毒」,低於限值也不保證「零風險」;限值是一個內建了大量安全餘裕、且把保護未明說地擴及脆弱族群的社會約定,而非一道物理的生死線。
看一個例子:用單位風險把「合規」翻譯成「人命」
假設某無閾值致癌物,毒理與流行病學整合後估出單位風險(unit risk) 為:終生(70 年)暴露於 1 µg/m³ 環境中,超額致癌風險為 1 × 10⁻³(即每千人多 1 例癌症)。
某工廠把作業環境控制在「合規」的 0.5 µg/m³,管理階層宣稱「已符合標準,無虞」。我們用單位風險把這句話翻譯成族群語言。
先估個人終生超額風險:
0.5 µg/m³ × (1 × 10⁻³ 每 µg/m³) = 5 × 10⁻⁴
也就是每名長期暴露的勞工,終生超額致癌風險約為萬分之五。這個數字單看很小,但職業衛生的視角永遠是族群。若這條產線長期累計有 4,000 名勞工曾以此強度暴露:
4,000 × 5 × 10⁻⁴ = 約 2 例超額癌症
請注意三件事。其一,「合規」並不等於「零風險」——這 2 例是在完全守法的前提下被預期會發生的。多數公共衛生機構把職業情境下 10⁻³、一般環境下 10⁻⁶ 視為「可接受/需管理」風險的粗略分界,而萬分之五(5×10⁻⁴)已逼近職業可接受上限。其二,這套估算把抽象的標準爭論,轉成「2 條本可避免的人命」這種可被問責、可權衡成本的具體量。其三,所有數字都繼承了前面每一步的不確定性——單位風險本身可能有數倍誤差,暴露重建可能偏低,因此嚴謹的報告會給出一個區間(如 0.5 至 6 例),而非一個假裝精確的點估計。能讀懂並合理質疑這條從「µg/m³」到「人命」的翻譯鏈,正是進階職業衛生訓練的核心能力。
暴露評估的前沿:從一支採樣管到「職業暴露組」
入門篇談的空氣採樣與生物偵測,是暴露評估的古典骨架。進階層次的研究,正把這個骨架往兩個方向大幅延伸。
第一是時空解析度的革命。 傳統一支被動式採樣管給的是「整班一個平均值」,掩蓋了峰值、任務間差異與微環境變化。可穿戴式即時感測器(如個人 PM 感測器、揮發性有機物即時偵測、噪音劑量計、配合 GPS 與穿戴式生理裝置)讓研究者能重建「這位勞工在哪一個任務、哪一段時間、暴露衝到多高」的細粒度軌跡。這與 Educational Omics 框架裡 Environomics(環境組學)的多模態即時測量精神同源——都是把環境暴露當成可連續記錄、可與生理反應對齊的高解析資料流。
第二是「暴露組(exposome)」的視野。 單一危害的線性思維,無法解釋真實勞動現場的健康樣態,因為人從不只暴露於一種東西。暴露組的概念主張:應把一個人一生中所受的全部環境暴露總和——職業的、非職業的、化學的、物理的、心理社會的——當成一個整體來研究其與健康的關聯。對職業衛生而言,這意味著要嚴肅處理多重暴露的聯合效應:石綿與吸菸對肺癌風險接近相乘而非相加(一個吸菸又暴露石綿的勞工,風險遠超過兩者各自風險之和),這種交互作用直接改變了介入的優先序——對這群人,戒菸與除塵的綜合公衛效益會被放大。古典的「一物質、一限值」管制框架,在面對化學品混合暴露與物理—心理社會危害交織時顯得力不從心,這也是當代職業暴露科學最活躍的前沿。
動手試試:替一條產線排出控制階層的「投資順序」
挑一個你熟悉的作業情境(例如餐飲廚房的高溫與油煙、實驗室的有機溶劑、物流倉的人工搬運與噪音、或外送平台的交通與工時壓力),用進階視角做一次結構化分析:
- 辨識主要危害並追問其劑量學:這個危害的傷害是由 C×t 累積決定,還是由峰值決定?(若是峰值主導,光看 TWA 會誤判,需要 STEL 或 ceiling 思維。)
- 判斷閾值性質:它比較像「有安全閾值的系統性毒性」,還是「無閾值的致癌/突變危害」?這決定你的目標是「守住一條線」還是「ALARA 一路降到底」。
- 沿危害控制階層由上而下排序對策,並對每一層誠實標註它依賴人配合的程度——消除與工程控制裝好就持續生效;行政管理與 PPE 則每天都可能因疏忽而失守。據此排出「投資順序」:把資源優先投在高可靠度的上層。
- 加上不平等視角:在這個情境裡,誰承受最高暴露、卻享有最少保障?(常是外包、移工、零工、低教育者。)你的對策有沒有不小心把責任從雇主轉嫁到最弱勢的勞工身上?
走完這四步,你會發現自己已經不是在「背防護措施」,而是在用劑量學、閾值判斷、可靠度排序與健康公平四套語言,系統性地拆解一個真實的勞動健康問題——這正是進階職業衛生與入門最大的差別。
重點回顧
- 暴露有「形狀」,不只有總量:哈伯法則(C × t)只是一階近似,許多危害遵循 Cⁿ × t,峰值暴露可能比平均濃度更致命;這正是 STEL 與 ceiling 限值存在的理由,光看 8 小時 TWA 會漏判。
- 低劑量端的曲線形狀決定管制邏輯:有閾值(多數系統性毒性,存在 NOAEL 安全地帶)對上無閾值(基因毒性致癌物與游離輻射,採 LNT、走 ALARA),閾值之有無常是結合機制與保守原則的政策判斷,而非純流行病學能定論。
- 風險評估四步驟強制分離科學與決策:危害辨識 → 劑量反應 → 暴露評估 → 風險特徵化;「殘餘風險可不可接受」是價值與經濟問題,把它偽裝成科學結論是常見謬誤。
- 限值的保守來自內建的不確定係數:以 BMD/BMDL 取代 NOAEL 為起點,再除以動物外推、個體差異等各約 10 倍的係數,總餘裕常達百倍以上;故超標不等於立刻中毒,達標也不等於零風險。
- 前沿在高解析暴露與暴露組:可穿戴即時感測重建細粒度暴露軌跡,暴露組視野處理多重暴露的聯合效應(如石綿×吸菸近乎相乘),古典「一物質一限值」框架正被多重交互暴露的現實挑戰。
深入探討(研究所視角)
進入研究所層次,職業衛生的劑量—反應與風險評估會從「套用既定框架」升級為「質問框架本身的統計與生物假設」。
第一條主線是滯後與累積劑量的建模選擇如何左右結論。 許多職業癌症潛伏期長達數十年,分析時必須明確設定暴露窗(exposure window)與滯後(lag)結構——是用終生累積劑量、近期暴露、還是某段「關鍵窗」最相關?不同設定會給出截然不同的劑量—反應斜率。當代研究借助分布滯後非線性模型(distributed lag non-linear models)等工具,讓滯後與劑量—反應形狀同時被資料估計,而非預先武斷指定。這與環境流行病學處理空汙急慢性效應的滯後問題完全同源,也呼應 Environomics 把暴露當成隨時間連續展開之資料流的取向。建模者必須意識到:一條曲線的形狀,往往不是「資料說的」,而是「你問資料的方式決定的」。
第二條主線是暴露錯分如何系統性地扭曲風險估計,以及如何校正。 以工作職稱粗略代表暴露,會引入暴露錯分(exposure misclassification)。關鍵在於分辨其性質:非差異性錯分(與疾病結果無關) 通常使效應趨向虛無(bias toward the null),讓真正有害的暴露看起來無害——這在低劑量、無閾值致癌物的研究中後果尤其嚴重,因為本就微弱的訊號更容易被抹平到統計顯著性之下;而差異性錯分(如病例比對照更努力回憶暴露的回憶偏誤)則可能往任一方向偏。當代方法以測量誤差模型(measurement error models) 與校正子研究(validation substudy) 量化並反推真實斜率,並用機率式偏誤分析(probabilistic bias analysis) 把錯分、選擇偏誤、未測混淆的不確定性,整合進一個比傳統信賴區間更誠實的風險區間。這套思維把「健康工作者效應」「選擇偏誤」「混淆」從入門時的定性警語,升級為可被量化、可被部分校正的建模對象。
第三條主線是風險評估典範本身的政治與倫理張力。 不確定係數該取 10 還是 3?閾值假設能否成立?可接受風險該定在 10⁻³ 還是 10⁻⁶?——這些看似技術的選擇,每一個都暗藏價值判斷,且其後果不均勻地落在不同族群身上。職業健康不平等(occupational health inequality) 的研究顯示,高危害、低保障的工作系統性集中於移工、少數族裔與經濟弱勢者身上,與環境正義(environmental justice) 的命題遙相呼應;而非典型與平台勞動(gig economy)的興起,更讓大批勞工落在傳統暴露限值、勞動檢查與職災補償體制的涵蓋邊緣,承受演算法管理壓力等古典框架未曾編碼的新型危害。對立志深耕此領域的學生而言,真正的訓練不在於記住某個物質的 PEL 數值,而在於同時掌握三套語言——劑量學與毒理機制(傷害如何隨暴露展開)、因果與測量推論(我們的估計可信到什麼程度、偏向哪一邊),以及分配正義(風險與保障如何不均地落在不同人身上)——並能在三者交會處,提出那個既古典又被每一種新型工作形態重新逼問的問題:勞動如何在族群尺度上塑造健康,而我們又能在哪一個環節、用哪一層控制、為哪一群人,最可靠地介入。