
當「病例數超過預期」需要一條公式:監測訊號背後的數學
深入疾病監測水面之下的三大引擎——異常偵測演算法、通報延遲與右設限回填、以及有效再生數的即時估計與假設陷阱。
當「病例數超過預期」需要一條公式:監測訊號背後的數學
入門篇我們說過,疾病監測(disease surveillance)像一座雷達——當某地某病的病例數「突然超過預期」,就會亮起警報。但請停下來想一個更尖銳的問題:「超過預期」的「預期」,到底是誰算的?多出多少才叫「異常」? 一個城市每天本來就有上百例腹瀉就醫,今天多了三十例,是雜訊還是疫情的第一道漣漪?
在入門層次,這個判斷往往交給經驗豐富的公衛人員「看圖說故事」。但當監測系統要同時盯著數百種疾病、數千個地理單元、每天自動更新,人眼根本看不過來。於是「異常偵測」必須被寫成一條可以讓電腦每天執行的統計規則。這篇進階文章,我們不再重述監測「是什麼」,而是潛入水面之下,看清三件事的數學骨架:警報怎麼自動產生(aberration detection)、進行中的曲線為什麼會騙人(nowcasting 與通報延遲)、以及傳播速度怎麼即時量化(有效再生數 $R_t$)。這三者,正是當代「即時流行病學」(real-time epidemiology)的核心引擎。
從「看圖」到「演算法」:異常偵測的統計化
把「超過預期」變成公式,第一步是定義預期值(expected count)。最樸素的做法,是用歷史同期資料估一個基準線。美國疾病管制與預防中心(CDC)早期推廣的 EARS(Early Aberration Reporting System) 系列演算法,就用了極簡單的「移動視窗」思路。以其中的 C1 為例:
對第 $t$ 天的觀測病例數 $x_t$,取前 7 天(不含今天)算出平均 $\bar{x}$ 與標準差 $s$,定義統計量
$$ C_1 = \frac{x_t - \bar{x}}{s} $$
當 $C_1 > 3$(也就是今天的數字超過近期平均加三個標準差)就觸發警報。這其實就是工業品管裡的「3-sigma 管制圖」搬到流行病學上——直覺、好算、第一線單位容易接受(呼應入門篇提過的「簡單性」屬性)。
但這個樸素做法藏著三個致命弱點,正是進階監測必須處理的:
- 季節性(seasonality):流感冬天高、夏天低,腸胃炎暑假一波。用「前 7 天」當基準,等於假設疾病沒有季節律動,會在流行季每天都誤報、在淡季又過於遲鈍。
- 長期趨勢(secular trend):人口成長、醫療可近性改變,都會讓基準線本身緩慢漂移。
- 過去爆發的污染(past outbreaks):如果去年同期剛好有疫情,把它納入「預期」的計算,會把今年真正的爆發給「正常化」掉,等於用一場舊疫情掩護一場新疫情。
歐洲多國採用的 Farrington 演算法 就是為了解決這三點而生:它不用簡單平均,而是對「過去數年、同月份前後數週」的歷史資料配一個過度離散的廣義線性模型(over-dispersed Poisson / 準帕松迴歸),同時放入長期趨勢項,並用殘差加權把歷史上的異常高點「降權」,避免舊疫情污染基準。算出的預期值會附帶一個上界(threshold),今天的觀測一旦超過上界就示警。從 EARS 到 Farrington,正是監測從「看圖」走向「演算法」的縮影。
看一個例子:同一筆資料,兩條基準線
假設某市過去一年每週類流感(influenza-like illness, ILI)門診比例如下(簡化):夏季約 1.5%、冬季高峰約 6%。現在是 11 月初,本週觀測到 4.2%。
- 樸素 C1 視角:取「前 7 週」平均。但 11 月初正處於秋冬爬升期,前 7 週平均可能才 2.0%、標準差 0.4%。於是 $C_1 = (4.2 - 2.0)/0.4 = 5.5$,遠超過 3——警報大響。
- Farrington 視角:它會去看「過去三、四年每年 11 月初」的水準。若歷史上每年此時本來就會爬到 4% 上下,那麼 4.2% 落在預期區間內,不示警。
同一個 4.2%,一個演算法尖叫、一個演算法淡定。差別不在資料,而在「預期」如何被建模。這正是進階監測的精髓:警報的可信度,取決於基準線有沒有誠實地納入季節、趨勢與歷史污染。在族群層次上,一個忽略冬季季節性的監測系統,每年都會在入冬時對全人口「狼來了」,最終訓練出對警報無感的防疫團隊——也就是下一節要談的代價。
第一型錯誤、第二型錯誤,與「警報疲勞」
任何自動警報系統,本質上都是一個反覆進行的統計假設檢定。虛無假設 $H_0$ 是「沒有疫情,今天的數字只是隨機波動」。於是我們無可迴避地撞上統計學最古老的兩難:
- 第一型錯誤(type I error,偽陽性):其實沒疫情,卻發出警報。代價是防疫人力空跑、資源浪費,更隱性的代價是警報疲勞(alarm fatigue)——當系統一天到晚誤報,第一線人員會逐漸學會無視它,於是某天真正的警報響起時,沒有人當一回事。
- 第二型錯誤(type II error,偽陰性):其實有疫情,卻沒警報。代價是錯過早期介入的黃金窗口,疫情坐大。
把警報門檻(如前面的 $C_1 > 3$ 的那個「3」)調低,靈敏度上升、抓得到更多真疫情,但偽陽性暴增;調高則反之。沒有一個門檻能同時讓兩種錯誤都最小化——這是入門篇提過的「靈敏度與精確度相互拉扯」的數學本質。
評估監測演算法好壞時,流行病學家會借用診斷檢定的語言,把每一天分成「該不該示警 × 有沒有示警」的四格:
| 系統示警 | 系統未示警 | |
|---|---|---|
| 真有疫情 | 真陽性 TP | 偽陰性 FN |
| 無疫情 | 偽陽性 FP | 真陰性 TN |
由此可算出靈敏度(sensitivity $=TP/(TP+FN)$)、特異度(specificity $=TN/(TN+FP)$),以及監測獨有的第三個維度——及時性(timeliness):就算最終抓到了,是疫情第幾天才抓到的?一個調得很靈敏的演算法可能抓得早卻誤報連連;一個保守的演算法準是準,卻可能等疫情已經明顯了才示警。把不同門檻下的(靈敏度、偽陽率、及時性)畫成曲線,挑出符合當前防疫目的的工作點,這就是設計監測系統的「工程權衡」具體化為一道可計算的最佳化問題。值得強調:在族群層次,這個工作點的選擇是價值判斷而非純技術——對一個致死率高、有特效介入的新興傳染病,社會願意容忍大量偽陽性以換取不漏接;對一個輕症為主的常見病,則應把門檻調高以保護人力。
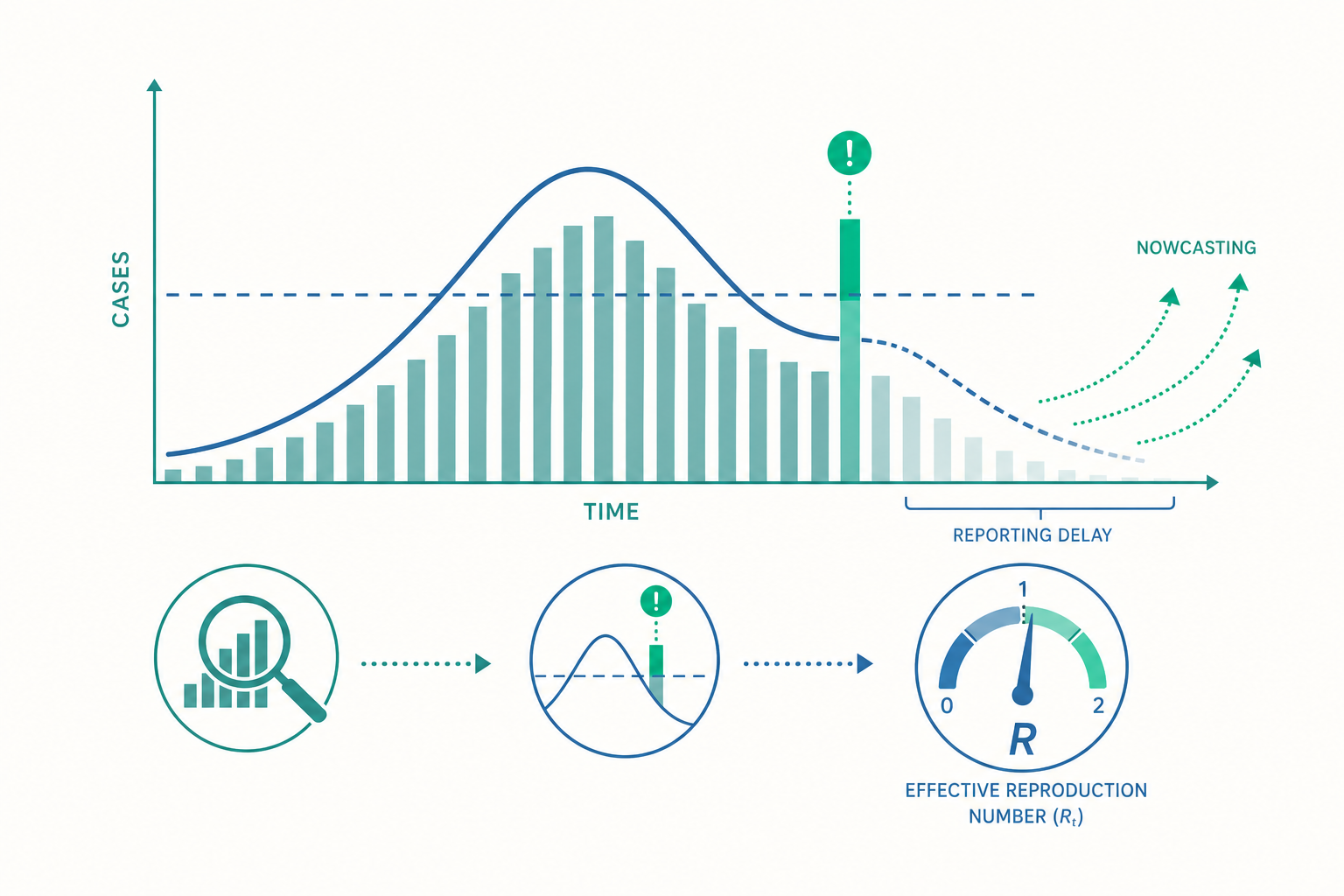
進行中的曲線會騙你:通報延遲與右設限
現在進入第二個引擎,也是即時流行病學最反直覺的一課。請看一個情境:
你是疫情指揮中心的分析師,今天是週五。你打開以「發病日」(onset date)排序的流行曲線,發現週三、週四的病例數明顯下降。你鬆了一口氣,準備向上回報「疫情趨緩」。
這幾乎一定是錯的。
問題出在通報延遲(reporting delay):從一個人發病、就醫、被診斷、到資料真正進入監測系統,中間隔著好幾天。所以當你在週五回看週三、週四的數字,許多在那兩天發病的人,根本還沒被通報進來。最近幾天的曲線必然被低估,呈現一個虛假的「下墜尾巴」。在統計學上,這叫右設限(right censoring)——最近期的觀測尚未「完成」。
| 發病日 | 截至週五已通報數 | 數天後最終總數 | 完整度 |
|---|---|---|---|
| 上週六 | 50 | 50 | 100% |
| 週一 | 48 | 50 | 96% |
| 週三 | 30 | 49 | 約 61% |
| 週四 | 12 | 48 | 25% |
上表是個典型樣貌:越靠近「今天」,已通報數越偏離最終真實數。直接拿最新幾天的數字解讀趨勢,等於把「通報還沒跑完」誤讀成「疫情在下降」。 2020 年 COVID-19 初期,許多地方一到週末病例數就「下降」,其實只是週末檢驗與通報量能下降造成的週期性偽影,週一又補回來——這就是通報延遲的日內版本。
動手試試:用延遲分布做最簡單的回填
解法叫 回填(nowcasting):根據「歷史上通報延遲有多長」的分布,估計每一個發病日「最終會被通報上來的真實總數」。最簡單的版本是這樣:
假設我們從歷史資料學到,某病的通報延遲分布大致為——發病後第 0 天通報 10%、第 1 天累積 40%、第 2 天累積 70%、第 3 天累積 90%、第 5 天 100%。
現在是某日,「兩天前」發病的個案目前已通報 35 例。由於延遲分布告訴我們,發病後兩天「應該只累積到約 70%」,於是回填估計:
$$ \hat{x}_{\text{真實}} = \frac{35}{0.70} = 50 \text{ 例} $$
也就是說,那天最終約會有 50 例,目前看到的 35 例只是「跑完七成」的中間態。把每一個近期發病日都這樣放大校正,原本那條虛假的「下墜尾巴」就會被拉回它真正的高度。
當然,真正的 nowcasting 遠比這精細:通報延遲本身會隨疫情階段、星期幾、檢驗量能變化(不是固定分布),所以實務上用貝氏階層模型或廣義加成模型(GAM)來同時估計延遲分布與真實病例數,並給出不確定區間。但核心直覺不變:永遠不要直接相信曲線最右端的幾天。 一個成熟的分析師看到「最近三天在降」,第一反應不是「疫情趨緩」,而是「這是不是右設限?」——這份警覺,是區別新手與老手的分水嶺。
量化傳播速度:有效再生數 $R_t$ 與更新方程
第三個引擎,回答的是決策者最常問、卻最難答準的問題:「現在疫情是在加速還是在減速?」
衡量這件事的核心量,是有效再生數(effective reproduction number, $R_t$):在時間 $t$、考慮當下的免疫比例與防疫措施後,一個感染者平均會傳染給幾個人。它與更為人熟知的基本再生數 $R_0$(完全沒有免疫與介入時的傳染力)不同——$R_0$ 是疾病的「先天」特性、近乎常數,$R_t$ 則是會隨時間變動的「即時體溫計」:
- $R_t > 1$:每個病人傳給超過一人,疫情擴大。
- $R_t = 1$:剛好替補,疫情進入平衡(高原)。
- $R_t < 1$:每個病人傳不到一人,疫情萎縮、終將平息。
當代主流的即時估計法,建立在更新方程(renewal equation) 上。它的直覺很美:今天的新發病數,是過去每一天的病人,按照「他們在病程第幾天最容易傳人」的權重,各自貢獻出來的總和。寫成式子:
$$ E[I_t] = R_t \sum_{s=1}^{t} I_{t-s}\, w_s $$
其中 $I_t$ 是第 $t$ 天的新發病數,$w_s$ 是序列間隔(serial interval)分布——也就是「傳染者發病」到「被他傳染者發病」之間相隔 $s$ 天的機率。換句話說:把過去的病例數用序列間隔加權求和,當成「今天的傳染壓力」,今天實際冒出多少新病例除以這個壓力,就是 $R_t$。Cori 等人 2013 年提出的方法把這套寫進一個簡潔的貝氏框架,至今是各國疫情指揮中心的標準工具之一。
但 $R_t$ 出了名地「敏感而脆弱」,三個陷阱必須牢記:
- 它繼承了所有資料問題。$R_t$ 是從病例曲線算出來的,所以前一節的通報延遲、右設限會直接讓最新幾天的 $R_t$ 失真——這也是為什麼負責任的單位公布 $R_t$ 時,最近期的值總標注「估計尚未穩定」。
- 序列間隔 vs 世代間隔(generation interval)的混淆。理論上更新方程該用的是世代間隔(一次感染到下一次感染的時距),但感染時刻通常觀測不到,實務上常用可觀測的序列間隔(發病到發病)來近似。當潛伏期與可傳染期不對齊時,這個近似會引入偏誤——這是一個入門課本幾乎不提、但研究所必爭的細節。
- 它對序列間隔的假設極為敏感。如果你假設的平均世代間隔偏短,估出的 $R_t$ 就會偏向 1(看起來疫情比實際溫和);偏長則相反。同一波疫情,不同團隊因序列間隔假設不同,估出的 $R_t$ 可能差距可觀——這不是誰算錯,而是這個量本身就吃假設。
理解這三點,你就能讀懂為何疫情期間「$R_t$ 到底是多少」常有爭論。它不是因為科學不嚴謹,恰恰相反,是因為嚴謹的人知道這個數字背後綁著一串易碎的假設。在族群層次傳達 $R_t$ 時,把它當成一支「帶誤差棒的即時溫度計」而非精確讀數,才是負責任的做法。
重點回顧
- 「病例數超過預期」必須被寫成統計規則:從樸素的 3-sigma(EARS C1)到考慮季節、趨勢、歷史污染的 Farrington 演算法,差別在於「預期值」如何被誠實地建模。
- 自動警報是反覆的假設檢定,無可避免地在第一型錯誤(偽陽性、警報疲勞)與第二型錯誤(偽陰性、錯過黃金窗口)之間權衡;門檻的選擇是價值判斷,須評估靈敏度、特異度與及時性三維工作點。
- 進行中的流行曲線最右端必然被低估:通報延遲造成右設限,最近幾天的「下降」常是假象;nowcasting 用延遲分布回填出真實高度。
- 有效再生數 $R_t$ 是疫情的即時體溫計(>1 擴大、<1 萎縮),建立在更新方程與序列間隔分布上,但它繼承資料延遲問題、混淆世代/序列間隔、且對假設高度敏感。
- 所有進階方法的共同教訓:監測的數字從來不是直接的真相,而是被通報行為、延遲、模型假設層層中介後的「估計」——讀數字前先問「這是怎麼被算出來的」。
深入探討(研究所視角)
把上述三個引擎放回研究前沿,它們各自連著一條活躍的研究脈絡,也共享同一個哲學核心:從不完整、有偏誤、且持續更新的資料流中,做出帶有量化不確定性的即時推斷。
異常偵測的多重檢定與時空掃描。當系統同時監看數百種疾病 × 數千個地理單元 × 每天更新,本質上是在做海量同時假設檢定——若每個檢定都用 $\alpha = 0.05$,光靠運氣每天就會冒出大量偽陽性。如何控制整體偽發現率(false discovery rate, FDR),是監測統計的核心議題。在空間維度上,Kulldorff 的空間掃描統計量(spatial scan statistic, SaTScan) 用移動的圓形視窗在地圖上搜尋「病例顯著群聚」的位置與大小,並用蒙地卡羅排列檢定校正多重比較,已是疾病群聚(disease cluster)偵測的標準工具;其時空版本能同時定位「何處、何時」出現異常聚集。
Nowcasting 與 backcasting 的階層貝氏框架。當代回填研究多採貝氏階層模型,把「真實流行曲線」與「通報延遲分布」當成兩組待估的潛在參數聯合估計,並能納入延遲分布隨時間漂移(time-varying delay)。延伸問題還有 backcalculation(回算):已知發病曲線與潛伏期分布,反推更早的「感染時刻曲線」——這在愛滋病流行病學史上是經典方法,用以從已發病的 AIDS 病例回推 HIV 的真實感染時程。Nowcasting 與 backcalculation 共享同一個「去摺積(deconvolution)」數學結構:觀測曲線 = 真實曲線 與 延遲(或潛伏)分布的摺積,要做的是把它解開。
$R_t$ 估計的方法學分歧。除了 Cori 等人的「瞬時再生數」(instantaneous $R_t$,基於更新方程),還有 Wallinga–Teunis 的「個案再生數」(case reproduction number,基於成對傳播機率的概似),兩者回答的問題微妙不同——前者問「在時間 $t$ 當下的傳染環境如何」,後者問「在時間 $t$ 發病的人最終各傳了幾個」。前者適合即時監測(不需等未來資料),後者需要等傳播鏈完成、較適合回溯。理解這個分野,才不會把兩條 $R_t$ 曲線當成「應該一樣卻不一樣」而困惑。
機制模型與資料的耦合。上述方法多屬「現象學(phenomenological)」——直接從曲線推斷、不假設明確傳播機制。另一條路線是把監測資料餵進機制模型(如 SEIR 艙室模型或個體基礎模型),用資料同化(data assimilation) 技術(如集合卡爾曼濾波 ensemble Kalman filter、序貫蒙地卡羅 / 粒子濾波)讓模型狀態隨新資料即時更新,這正是流感與 COVID-19 即時預測(forecasting)競賽(如美國 CDC FluSight、COVID-19 Forecast Hub)的主流方法。一個值得深思的發現是:多模型的「整體預測」(ensemble forecast)幾乎總是優於任何單一模型——這呼應了天氣預報的長期經驗,也提醒我們在族群層次的不確定推斷裡,謙遜地承認「沒有單一模型壟斷真相」往往比追求一個完美模型更務實。
繞過監測金字塔的「客觀」訊號。所有上述方法都建立在「通報病例」這個受就醫與通報行為扭曲的資料上。近年最受矚目的突破,是尋找不依賴個人就醫行為的群體生物標記——其中廢水病原監測(wastewater-based epidemiology) 最為成熟:直接量測社區污水中的病原核酸載量,與通報行為脫鉤,能繞過監測金字塔的系統性低估(入門篇提過的「冰山」問題)。它把「個體層次的通報偏誤」轉化為「族群層次的客觀環境訊號」,但也帶來新的方法學課題:載量到病例數的換算(脫落率、稀釋、降解的不確定)、空間解析度(一個污水廠涵蓋多大人口),以及與傳統監測的校準融合——如何把這條「客觀但模糊」的訊號,與「精確但偏誤」的臨床通報整合進同一個推斷框架,是當前資料融合(data fusion) 研究的前沿。
最後,回到那個沒有公式能取代的判斷。再精巧的演算法,輸出的都只是「警報訊號」與「帶誤差棒的估計」。把這些統計訊號轉譯成「要不要關閉一所學校、要不要啟動大規模篩檢」的決策,仍需要人在價值、可行性與公平之間權衡——例如某項介入是否會不成比例地衝擊弱勢族群、社會是否能承受偽陽性帶來的成本。監測的數學讓訊號更清晰、不確定更誠實,但它的終點,始終是讓人類在族群健康的取捨上,做出更明智、也更負責任的選擇。