
當「校正了所有變項」反而讓答案更錯:因果推論的暗礁
為什麼「校正越多越好」是迷思——用有向無環圖(DAG)與反事實框架,看清混淆、對撞偏差與效應修飾如何決定該調整哪些變項。
當「校正了所有變項」反而讓答案更錯:因果推論的暗礁
你已經知道:同一份資料,描述的角度不同就能講出兩個故事。入門篇談的是「混淆(confounding)會讓相關看起來像因果」,於是大家學會了一個直覺——把能想到的變項全部放進迴歸模型「校正」就對了。
但這個直覺在流行病學裡是危險的。請先想一個情境:研究者想知道「孕婦吸菸是否害嬰兒死亡率上升」。攤開大型出生登記資料,做一件看似理所當然的事——只看「低出生體重」的嬰兒,比較媽媽有沒有吸菸。結果竟然出現著名的「出生體重悖論」(birth weight paradox):在低體重嬰兒裡,吸菸媽媽的嬰兒死亡率反而比較低。難道吸菸是保護因子?
當然不是。問題出在:研究者「控制」了一個本不該控制的變項。這篇進階文章,要帶你看清楚為什麼「校正越多越好」是迷思,以及現代流行病學如何用一套圖形語言(DAG)與反事實框架,把「該調整什麼」這件事從直覺變成可推導的科學。
從「關聯」到「因果」:我們真正想問的是什麼
入門篇反覆提醒「相關不等於因果」,但很少說清楚:因果到底是什麼意思?
現代流行病學採用「潛在結果」(potential outcomes,又稱反事實 counterfactual)的定義。對個體 $i$ 來說,存在兩個可能的結果:
- $Y_i(1)$:若這個人「暴露」(例如吸菸)會發生的結果。
- $Y_i(0)$:若同一個人「未暴露」會發生的結果。
個體因果效應就是 $Y_i(1) - Y_i(0)$。但這裡有個無法迴避的事實——任何一個人,我們最多只能觀察到其中一個結果(一個人不可能同時吸菸又不吸菸)。這被稱為「因果推論的根本問題」(fundamental problem of causal inference)。我們觀察不到個體效應,只能退而求其次,估計族群層次的平均因果效應(average treatment effect):$E[Y(1)] - E[Y(0)]$。
關鍵在於:在隨機分派的實驗(randomized controlled trial, RCT)裡,因為暴露組與未暴露組在分派前「可交換」(exchangeable),我們觀察到的 $E[Y \mid A=1] - E[Y \mid A=0]$ 才會等於真正的因果效應。但在觀察性研究裡,兩組人本來就不一樣(會吸菸的人也許壓力大、社經地位不同),「關聯」與「因果」之間就出現了裂縫。混淆、選擇偏差、測量誤差,都是讓這道裂縫張開的力量。
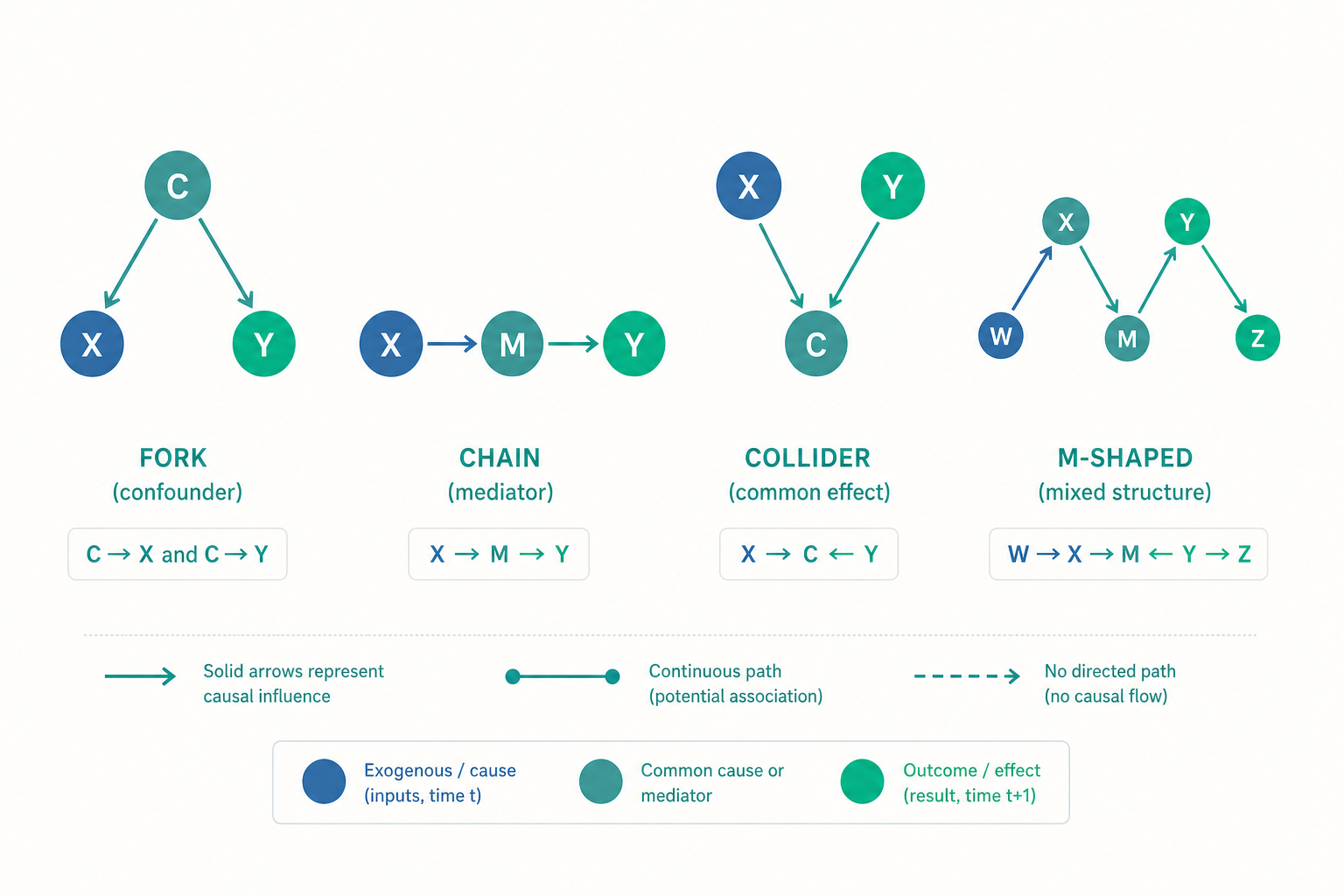
DAG:把因果假設畫成一張圖
要判斷「該校正哪些變項」,光靠直覺會出錯(出生體重悖論就是例子)。現代工具是有向無環圖(Directed Acyclic Graph, DAG)。它用箭頭表示「誰是誰的原因」,把研究者腦中的因果假設攤在桌面上,讓「該調整什麼」變成可以從圖的結構讀出來的規則。
DAG 裡有三種基本結構,決定了統計關聯如何沿著路徑流動:
1. 中介鏈(chain):$A \rightarrow M \rightarrow Y$
$A$ 透過 $M$ 影響 $Y$($M$ 是中介變項 mediator)。例如吸菸 → 肺部發炎 → 肺癌。如果你「校正」了 $M$,等於把 $A$ 經由 $M$ 的效應切斷,會低估總效應。這就是「過度校正」(overadjustment)的一種。
2. 分叉(fork):$A \leftarrow C \rightarrow Y$
$C$ 同時是 $A$ 與 $Y$ 的共同原因——這正是混淆因子(confounder)的圖形定義。例如「年齡」同時影響「是否運動」與「心臟病風險」。此時 $A$ 與 $Y$ 之間存在一條「後門路徑」(backdoor path),即使 $A$ 對 $Y$ 沒有因果效應,也會看到關聯。校正 $C$ 可以關閉這條後門,是該做的調整。
3. 對撞(collider):$A \rightarrow K \leftarrow Y$
$K$ 是 $A$ 與 $Y$ 的共同結果(collider,對撞節點)。在自然狀態下,這條路徑是封閉的——$A$ 與 $Y$ 不會因為 $K$ 而產生關聯。但一旦你「校正 $K$」、或只在某個 $K$ 值的子群裡分析(例如只看低出生體重嬰兒),就會打開這條路徑,憑空製造出虛假關聯。這就是對撞偏差(collider bias)。
三種結構的對比,正好顛覆了入門的直覺:fork 要調整、chain 與 collider 不要調整。「校正越多越好」之所以錯,就是因為它分不清這三者。
看一個例子:出生體重悖論的真相
回到開頭的謎題。畫出 DAG:
- 母親吸菸 $A \rightarrow$ 低出生體重 $K$
- 其他病因(如先天缺陷、胎盤異常)$U \rightarrow$ 低出生體重 $K$
- 母親吸菸 $A \rightarrow$ 嬰兒死亡 $Y$
- 其他病因 $U \rightarrow$ 嬰兒死亡 $Y$(而且 $U$ 對死亡的影響通常更致命)
「低出生體重 $K$」是吸菸與其他病因的共同結果——它是一個對撞節點。當研究者「只看低出生體重的嬰兒」,等於是在對撞點上做了分層(conditioning on a collider)。
直覺上會這樣推理:一個嬰兒體重很低,如果他媽媽沒吸菸,那體重低就更可能是由那些更致命的「其他病因 $U$」造成的;反之,如果媽媽有吸菸,至少有一部分低體重「只是」吸菸造成的、相對沒那麼致命。於是在低體重這個子群裡,「未吸菸」反而和「更嚴重的潛在病因」綁在一起,死亡率就被拉高了。吸菸看起來「保護」嬰兒,純粹是對撞偏差製造的幻覺。
這個例子的教訓很硬:選擇研究對象的方式(只看某子群)本身就是一種「校正」,而且可能引入偏差。它不是計算錯誤,是因果結構被誤解。
選擇偏差,其實也是對撞偏差
對撞偏差不只出現在「刻意分層」,它更常藏在樣本是怎麼被選進來的。
- 住院偏差(Berkson's bias):在醫院裡研究「疾病 A 與疾病 B 的關聯」。能不能住院(被納入研究)是兩種病的共同結果——病得夠重才會住院。於是在「住院病人」這個樣本裡,A 與 B 會出現本不存在的負關聯。
- 失訪偏差(loss to follow-up):長期追蹤研究中,若「暴露」與「結果」都會影響一個人是否中途退出,那麼「留在研究裡」就是一個對撞節點,只分析留下來的人會產生偏差。
- 自我選擇樣本:網路問卷裡「願意填問卷的人」可能同時受暴露與健康狀況影響,這也是同一種結構。
把選擇偏差視為「在對撞節點上分層」的統一觀點,是現代流行病學的一大進步(Hernán、Greenland 等人的工作)。它讓「樣本代表性」這個老問題,有了可以用 DAG 推導、而非只能憑經驗喊的處理方式。
M-bias:為什麼「多校正一個無害變項」也可能出錯
入門生最容易踩的最後一個雷叫做 M-bias。考慮這張像字母 M 的圖:
$$A \leftarrow U_1 \rightarrow K \leftarrow U_2 \rightarrow Y$$
這裡 $K$ 是某個你「順手」測量到、看起來和暴露、結果都沾點邊的變項(例如某個基因標記、某個前測指標)。注意:$K$ 不是混淆因子——它不在 $A \rightarrow Y$ 的後門路徑上,原本這條路徑是封閉的(因為 $K$ 是對撞點)。
但若你抱著「校正越多越安全」的心態把 $K$ 放進模型,就會打開這條對撞路徑,讓 $A$ 與 $Y$ 之間憑空長出關聯——明明 $A$ 對 $Y$ 沒有任何因果效應,你卻會估出一個顯著的「效應」。
M-bias 之所以陰險,是因為光看資料、看相關係數,你分不出 $K$ 是「該調整的混淆因子」還是「不該碰的對撞點」——唯有靠領域知識畫出 DAG 才能判斷。這也是為什麼資料科學裡「把所有特徵丟進去讓模型自己決定」的做法,在因果推論場景是不適用的:統計學無法從關聯結構裡反推因果方向,那需要你帶進來的科學假設。
不是所有差異都是「偏差」:效應修飾
最後談一個常被和混淆搞混的概念——效應修飾(effect modification)或交互作用(interaction)。
混淆是「需要被移除的偏差」;效應修飾則是「真實存在、值得報告的現象」。當暴露對結果的效應,在不同次族群裡大小不同,就叫效應修飾。例如:
- 某疫苗對年輕人保護力 90%,對 65 歲以上長者只有 60%——年齡是效應修飾因子。
- 黃麴毒素對肝癌的效應,在 B 型肝炎帶原者身上遠大於非帶原者——這是經典的生物學交互作用。
這裡藏著一個尺度的陷阱:效應修飾依「測量尺度」而定。同一份資料,用「相對風險」(ratio scale)看可能沒有交互作用,用「風險差」(difference scale,即可歸因風險)看卻有——反之亦然。這在公共衛生上極為重要:制定族群層級介入時,我們在意的是「能避免多少病例」(絕對尺度),而臨床上常用相對尺度。報告交互作用時,必須講清楚你用的是哪一種尺度,否則又會掉回「同一份資料兩個故事」的老坑。
動手試試:判斷該不該校正
給你一個 DAG,試著判斷「研究 $A \rightarrow Y$ 的因果效應時,下列變項該不該放進迴歸模型」:
題目:$A \rightarrow Y$;$A \leftarrow C \rightarrow Y$;$A \rightarrow M \rightarrow Y$;$A \rightarrow K \leftarrow Y$。
- $C$:該調整。它是混淆因子(fork),不調整會留下後門路徑。
- $M$:不要調整。它是中介變項(chain),調整會切掉一部分真實的因果效應,低估總效應(除非你刻意要做中介分析、拆解直接與間接效應,那是另一個目標)。
- $K$:絕對不要調整。它是對撞點,調整會憑空製造偏差。
只有正確識別這三種角色,你的迴歸係數才能解讀為因果效應。這套判準有個正式名稱叫「後門準則」(backdoor criterion):找出一組變項,能關閉所有後門路徑、同時不打開任何對撞路徑、不擋住因果路徑,就是該調整的最小充分集。
重點回顧
- 因果的定義是反事實:平均因果效應 $E[Y(1)] - E[Y(0)]$,而我們對每個人只看得到一半,因此觀察性研究的「關聯」與「因果」之間天生有裂縫。
- 「校正越多越好」是迷思。DAG 的三種結構決定一切:分叉(混淆)要調整、中介鏈不要調整(會低估)、對撞點絕不能調整(會製造偏差)。
- 對撞偏差統一了選擇偏差:只看子群、住院樣本、失訪、自我選擇問卷,本質都是「在對撞節點上分層」,會打開虛假關聯。出生體重悖論就是最著名的案例。
- M-bias 警告我們:光看資料無法判斷一個變項是混淆因子還是對撞點,只有靠領域知識畫 DAG 才能決定——這是因果推論和純預測模型的根本分野。
- 效應修飾是真實現象、不是偏差,但它依測量尺度(相對 vs 絕對)而定,報告時務必說清楚尺度。
深入探討(研究所視角)
若你打算往流行病學或生物統計研究所走,這篇文章只是現代因果推論的入口。值得進一步追的方向有:
目標試驗模擬(target trial emulation)。 Hernán 與 Robins 主張,任何觀察性研究都應先明確寫出「如果我能做一個 RCT,它的納入條件、暴露定義、分派時點、追蹤起點會是什麼」,再用觀察資料去「模擬」這個理想試驗。這套框架直接消解了許多隱性偏差(特別是「不朽時間偏差」immortal time bias),已成為藥物流行病學的方法學主流。
處理「時變混淆」的 g-methods。 當暴露隨時間變化、而混淆因子同時又被前一期暴露影響時(例如愛滋病治療中,CD4 數值既影響是否用藥、又被先前用藥改變),傳統迴歸會同時造成「調整不足」與「過度調整」的兩難。Robins 發展的 g-formula、邊際結構模型(marginal structural models, 透過反機率加權 IPTW 估計)與 g-estimation,是處理這類縱貫資料的標準工具,也是進階生統課程的核心。
敏感度分析與 E-value。 觀察性研究永遠無法排除「未測量的混淆」。VanderWeele 提出的 E-value,量化「要有多強的未測量混淆,才足以推翻你觀察到的關聯」,讓研究者誠實面對因果結論的脆弱程度,現已被多本頂尖醫學期刊建議或要求報告。
工具變數與自然實驗。 當無法隨機分派時,借用一個「只透過暴露影響結果、不走其他路徑」的工具變項(如孟德爾隨機化 Mendelian randomization 用基因型當工具),可在較弱的假設下逼近因果效應,是遺傳流行病學近十年的爆發領域。
這些方法共同的精神是:統計從來不能單獨產生因果結論,它需要你帶進可被檢驗、可被畫出來的科學假設。 DAG 與反事實框架的價值,不在於給出更複雜的數學,而在於逼迫研究者把「我假設世界如何運作」誠實寫下來——這正是把「兩個故事」收斂回「一個可辯護的因果主張」的關鍵一步。