
網格夠細、邊界也對了,為什麼答案還是錯的?
深入 FEM 元素構造與求解器的數值病態——Jacobian、剪力鎖定、沙漏模態、條件數與 CFL 條件,看清「網格收斂」之外那層讓答案無聲失真的陷阱。
網格夠細、邊界也對了,為什麼答案還是錯的?
入門篇結束在一個讓人安心的結論:做好網格收斂分析、設對邊界條件,FEM 的數字就可信。但任何真正跑過大型專案的人都遇過一種令人沮喪的情境——網格已經細到記憶體爆掉、邊界條件反覆檢查了三遍、解析解的量級也對得上,結果就是不對。位移偏小一半,或者應力雲圖上出現詭異的鋸齒花紋,或者求解器跑了一夜還說「不收斂」。
問題出在一個入門篇刻意略過的層次:元素本身的數值構造(element formulation)與求解器的數值行為。$\mathbf{K}\mathbf{u}=\mathbf{F}$ 這個方程式看似乾淨,但 $\mathbf{K}$ 怎麼被積分出來、$\mathbf{K}$ 的條件數(condition number)有多糟、求解器用直接法還是迭代法、顯式還是隱式——這些藏在「按下分析按鈕」背後的決策,會在你毫無察覺的情況下污染答案。本文就是要打開這層黑盒子。
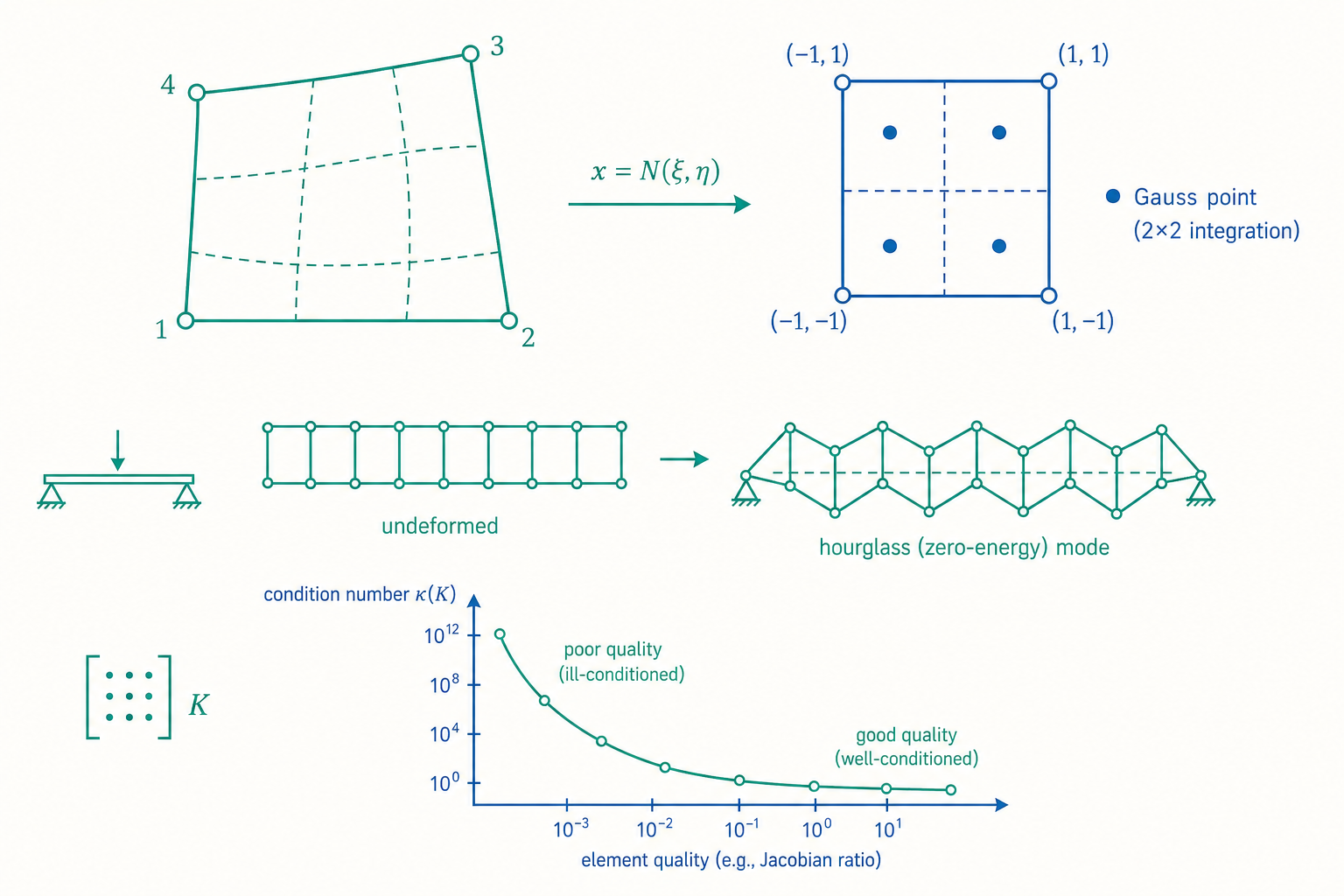
等參映射與 Jacobian:元素品質不是美觀問題
入門篇用一維桿元素說明剛度矩陣怎麼疊加,但真實 3D 元素遠比那複雜。關鍵技術是等參元素(isoparametric element):用同一組形函數 $N_i$ 同時內插「幾何座標」與「位移場」。每個扭曲的實際元素,都被映射回一個規整的母元素(parent element)——例如二維四邊形映射回 $\xi,\eta \in [-1,1]$ 的正方形。
幾何映射寫成:
$$x(\xi,\eta) = \sum_i N_i(\xi,\eta)\, x_i, \qquad y(\xi,\eta) = \sum_i N_i(\xi,\eta)\, y_i$$
要把母元素座標的微分轉回真實座標,需要 Jacobian 矩陣(Jacobian matrix):
$$\mathbf{J} = \begin{bmatrix} \dfrac{\partial x}{\partial \xi} & \dfrac{\partial y}{\partial \xi} \\[2mm] \dfrac{\partial x}{\partial \eta} & \dfrac{\partial y}{\partial \eta} \end{bmatrix}, \qquad \det \mathbf{J} = J$$
這個 $J$ 不只是個數學細節——它就是元素品質的量化指標。元素剛度矩陣的積分要用到 $\mathbf{J}^{-1}$ 與 $J$:
$$\mathbf{k}^e = \int_{-1}^{1}\!\!\int_{-1}^{1} \mathbf{B}^\mathsf{T}\mathbf{D}\,\mathbf{B}\; J \; d\xi\, d\eta$$
其中 $\mathbf{B}$ 是應變—位移矩陣(含 $\mathbf{J}^{-1}$)。現在問題來了:
- 若元素嚴重扭曲(一個角接近 180° 或塌成細長條),$J$ 在元素內某些點會趨近 0,$\mathbf{J}^{-1}$ 隨之爆炸,應力計算嚴重失真。
- 若元素自我翻折(concave 到一個角穿過對邊),某些積分點的 $J < 0$,物理上代表「體積為負」,求解器通常直接報 negative Jacobian 而停止。
所以網格器報告的 Jacobian ratio、aspect ratio、skewness 這些「網格品質指標」,不是讓圖好看,而是直接反映 $J$ 在元素內的均勻程度。理論上完美的細網格,若元素品質差,照樣給你錯誤的應力——這是「網格夠細卻仍出錯」的第一大來源。
Gauss 積分:電腦怎麼算那個積分
上面的積分電腦不是用解析法做的,而是高斯數值積分(Gauss quadrature):在元素內選幾個特定的積分點(integration point / Gauss point),加權求和近似積分:
$$\int_{-1}^{1} f(\xi)\, d\xi \approx \sum_{g=1}^{n_g} w_g\, f(\xi_g)$$
$n$ 個高斯點可精確積分到 $2n-1$ 次多項式。一個二次四邊形通常用 $3\times 3 = 9$ 個高斯點(full integration,完全積分)。記住「應力是在高斯點上算最準的」這件事很重要——軟體顯示的節點應力(nodal stress)其實是從高斯點外推(extrapolate)再平均出來的,這個外推與平均過程本身就會引入誤差,也是為什麼相鄰元素的節點應力不連續、需要平滑化的根源。
Shear Locking 與 Hourglassing:積分點數量的兩難
這裡是整篇文章的核心張力,也是入門篇完全沒碰的陷阱。積分點數量看似只是精度問題,實際上牽動兩個方向相反的數值病態。
完全積分(full integration)的災難:剪力鎖定(shear locking)。 想像用一層線性(一階)實體元素去模擬一根受彎的薄梁。線性元素的位移場是雙線性的,但純彎曲時材料纖維應該彎成弧形,線性元素無法表現彎曲,只能用「斜剪」去硬湊那個變形。結果是元素產生了虛假的剪應變(parasitic shear strain),吸收了大量本不該存在的應變能,讓元素表現得比真實材料硬得多。症狀很經典:你用一排線性元素算懸臂梁撓度,算出來只有理論值的一半甚至更少,而且網格再怎麼加密都收斂得極慢。這就是「網格夠細答案還是錯(偏硬、偏小)」的典型元兇。
對抗剪力鎖定的標準手法是降階積分(reduced integration):故意少用幾個高斯點(例如線性四邊形只用 $1$ 個中心點而非 $2\times 2$),讓那個虛假剪應變在唯一的積分點上恰好為零,鎖定就消失了。
但降階積分有它自己的惡魔:沙漏模態(hourglassing)。 用單一中心高斯點時,會出現一種「零能量模態(zero-energy mode)」:某些非剛體的變形模式,在那唯一的積分點上應變恰好算出來是零,於是這種變形不產生任何應變能、不被剛度矩陣懲罰。多個元素串起來,這種變形交錯排列,網格會扭成像沙漏(hourglass)一樣的鋸齒花紋——這正是前言提到的「詭異鋸齒」。$\mathbf{K}$ 因為多了零能量模態而變得接近奇異,位移場出現巨大且無意義的振盪。
現代軟體的解法是沙漏控制(hourglass control):人為加入一個小小的人工剛度(artificial stiffness)去抑制這些零能量模態,但又不能加太多否則剛度鎖定又回來。這是一場精細的平衡。更高階的解法是用選擇性降階積分(selective reduced integration)、B-bar / 假設應變法(assumed strain) 或 不協調模式元素(incompatible modes element),只對「容易鎖定」的那部分變形降階。
| 策略 | 剪力鎖定 | 沙漏模態 | 計算成本 |
|---|---|---|---|
| 線性 + 完全積分 | 嚴重(過硬) | 無 | 中 |
| 線性 + 降階積分 | 無 | 嚴重 | 低 |
| 線性 + 降階 + 沙漏控制 | 無 | 受控 | 低 |
| 二次 + 完全積分 | 輕微 | 無 | 高 |
這張表解釋了一個實務常識:當答案偏硬、撓度偏小,懷疑剪力鎖定,換二次元素或降階積分;當雲圖出現棋盤格鋸齒,懷疑沙漏,打開沙漏控制或換完全積分。 這個判斷力,是入門篇的「網格收斂」框架完全無法給你的。
體積鎖定:當材料幾乎不可壓縮
還有一種鎖定值得單獨點名,因為它跟橡膠、塑膠、生物軟組織分析直接相關。當材料的蒲松比(Poisson's ratio) $\nu \to 0.5$(接近不可壓縮,如橡膠),材料的體積模數(bulk modulus)
$$K = \frac{E}{3(1-2\nu)}$$
在 $\nu \to 0.5$ 時趨於無限大。標準位移型元素必須同時滿足「體積守恆」這個幾乎剛性的約束,導致體積鎖定(volumetric locking)——元素再次表現得過硬,壓力場出現劇烈震盪。解法是改用混合元素(mixed / u-p formulation),把位移 $\mathbf{u}$ 和壓力 $p$ 當作獨立的未知數同時求解,避開那個發散的 $K$。所以下次做橡膠墊圈分析時若結果離譜,第一個要懷疑的不是網格,而是有沒有選對 hybrid 元素。
求解器的數值現實:條件數與直接 vs 迭代
假設元素都選對了,$\mathbf{K}\mathbf{u}=\mathbf{F}$ 終於組好。但「解這個方程組」本身也不是無痛的。
關鍵量是 $\mathbf{K}$ 的條件數(condition number) $\kappa(\mathbf{K}) = \lambda_{\max}/\lambda_{\min}$(最大與最小特徵值之比)。它衡量解對誤差的放大倍率:輸入有相對誤差 $\epsilon$,輸出的相對誤差可達 $\kappa \cdot \epsilon$。浮點數約有 16 位有效數字(雙精度),若 $\kappa \approx 10^{12}$,你的答案就只剩 4 位可信——這就是為什麼混用差異懸殊的剛度(例如把一個鋼螺栓和一片軟泡棉放進同一個模型,$E$ 差六個數量級)會讓結果無聲無息地爛掉。元素尺寸極端不均(aspect ratio 過大)同樣會推高 $\kappa$。
求解策略分兩大流派:
- 直接法(direct solver,如稀疏 LU / Cholesky 分解):對 $\mathbf{K}$ 做因式分解,一次解出。穩健、對病態矩陣容忍度高,但記憶體與時間隨自由度約以 $O(N^2)$ 量級成長(取決於矩陣帶寬與 fill-in),百萬自由度以上會吃掉巨量記憶體。中小型、多載荷工況的問題首選。
- 迭代法(iterative solver,如預條件共軛梯度 PCG):從初始猜測逐步逼近,每步只做矩陣—向量乘法,記憶體省得多,適合千萬自由度的超大模型。但收斂速度直接受 $\kappa$ 主宰——理論上共軛梯度法的迭代次數約正比於 $\sqrt{\kappa}$。所以迭代法高度依賴預條件子(preconditioner) 去壓低有效條件數;遇到病態矩陣可能跑很久甚至不收斂。
這解釋了一個常見困惑:「同一個模型,為什麼換個 solver 就解得出來/解不出來?」答案往往不在物理,而在 $\mathbf{K}$ 的條件數與所選數值方法的匹配度。
顯式 vs 隱式動態:CFL 條件與時間步長
入門篇的動態分析停在模態分析。但碰撞、衝壓、爆炸這類高速暫態(transient) 問題,主流是另一套——顯式時間積分(explicit time integration),它和入門提的隱式方法有本質差異。
隱式法(如 Newmark-$\beta$)在每個時間步都要解一次 $\mathbf{K}\mathbf{u}=\mathbf{F}$(大矩陣求解),時間步可以取得很大、無條件穩定。顯式法(中央差分)則完全不解大矩陣——它把質量矩陣對角化(lumped mass),位移直接從上一步外推:
$$\mathbf{u}_{n+1} = 2\mathbf{u}_n - \mathbf{u}_{n-1} + \Delta t^2\, \mathbf{M}^{-1}\big(\mathbf{F}_n - \mathbf{F}_{\text{int},n}\big)$$
因為 $\mathbf{M}$ 是對角的,$\mathbf{M}^{-1}$ 只是逐項取倒數,每步極便宜。代價是顯式法有條件穩定(conditionally stable):時間步必須小於一個臨界值,由 CFL 條件(Courant–Friedrichs–Lewy condition) 決定:
$$\Delta t \le \frac{L_{\min}}{c}, \qquad c = \sqrt{\frac{E}{\rho}}$$
$c$ 是材料的彈性波速(wave speed)、$L_{\min}$ 是最小元素的特徵長度。物理意義很直白:在一個時間步內,應力波不能穿越任何一個元素。這帶來一個反直覺又極關鍵的後果——只要網格裡有一個極小的元素,整個模型的時間步就被它拖到極小,計算時間暴增。所以顯式分析裡,「一個壞元素」的代價不是精度,而是幾十倍的牆鐘時間。這也是為什麼撞擊分析師對網格裡的最小元素如此敏感,甚至會用質量縮放(mass scaling)人為調大 $\rho$ 來換取更大的 $\Delta t$。
動手試試:估一根鋼梁的顯式時間步
取一段鋼材:楊氏模數 $E = 210\ \text{GPa}$、密度 $\rho = 7850\ \text{kg/m}^3$,網格最小元素尺寸 $L_{\min} = 2\ \text{mm}$。
第 1 步:彈性波速
$$c = \sqrt{\frac{E}{\rho}} = \sqrt{\frac{210\times 10^9}{7850}} \approx \sqrt{2.675\times 10^{7}} \approx 5172\ \text{m/s}$$
(約 $5.2\ \text{km/s}$,與鋼的縱波速實測值吻合。)
第 2 步:臨界時間步
$$\Delta t \le \frac{L_{\min}}{c} = \frac{0.002}{5172} \approx 3.87\times 10^{-7}\ \text{s} \approx 0.39\ \mu\text{s}$$
第 3 步:感受一下計算量
若要模擬一場 $10\ \text{ms}$($0.01\ \text{s}$)的撞擊,需要的時間步數約為
$$N_{\text{steps}} = \frac{0.01}{3.87\times 10^{-7}} \approx 2.6\times 10^{4}\ \text{步}$$
兩萬六千步,每步都要遍歷全模型一次。現在想像若有人不小心在某處留了一個 $0.1\ \text{mm}$ 的破碎元素——$L_{\min}$ 縮小 20 倍,時間步也縮 20 倍,步數暴增到 52 萬步,同一個分析從幾小時變成幾天。這個簡單估算,比任何「網格要乾淨」的口號都更能讓人記住為什麼。
重點回顧
- Jacobian 就是元素品質:等參映射用 $\mathbf{J}$ 在母元素與真實元素間轉換,$J\to 0$ 或 $J<0$ 直接污染應力,再細的網格也救不回扭曲元素。
- 積分點數量是兩難:完全積分會剪力鎖定(過硬、撓度偏小),降階積分會沙漏(鋸齒振盪),現代解法靠沙漏控制與選擇性積分在兩者間取平衡。
- 不可壓縮材料會體積鎖定:$\nu\to 0.5$ 時體積模數發散,橡膠/塑膠分析要改用 u-p 混合元素。
- 求解器受條件數主宰:$\kappa(\mathbf{K})$ 過大會讓答案無聲失真;直接法穩健吃記憶體、迭代法省記憶體但依賴預條件子與良態矩陣。
- 顯式動態被 CFL 綁死:$\Delta t \le L_{\min}/c$,一個小元素就能拖垮整個分析的時間步,這是撞擊模擬的命門。
深入探討(研究所視角)
本文揭露的這些病態,背後都通向更深的數學理論。剪力鎖定、體積鎖定能不能被嚴格分析?答案是 inf-sup 條件(Ladyzhenskaya–Babuška–Brezzi, LBB 條件):在混合變分問題(如 u-p 公式)中,位移空間與壓力空間的離散選擇必須滿足一個關於 inf-sup 常數有下界的相容性條件,否則壓力場會出現偽振盪。一個元素「會不會鎖定 / 沙漏」,本質上就是它在 LBB 框架下穩定與否的問題——這是計算力學研究生課程裡 Mixed and Hybrid Finite Element Methods 的核心。
值得延伸的還有後驗誤差估計(a posteriori error estimation)與自適應網格(adaptive mesh refinement, AMR)。入門篇的網格收斂是「手動加密、肉眼判斷」,但現代工程要的是讓軟體自己算出每個元素的誤差指標(如 Zienkiewicz–Zhu 應力恢復誤差估計子),自動在高誤差區加密、低誤差區放粗——把均勻細網格的浪費,集中到真正需要解析的應力梯度區。這把「要多細」從工程師的直覺,變成可量化、可自動化的數值決策。
另一個與 AI 時代直接相關的前沿是降階模型(reduced-order model, ROM)與代理模型(surrogate model)。完整的 $\mathbf{K}\mathbf{u}=\mathbf{F}$ 對即時設計疊代太慢,於是用 本徵正交分解(Proper Orthogonal Decomposition, POD) 從大量全階解中萃取出少數主導模態,把百萬自由度壓縮成幾十個,達成近即時的近似求解;近年更有物理資訊神經網路(Physics-Informed Neural Networks, PINN) 直接把 PDE 殘差寫進神經網路的損失函數,嘗試繞過網格。但要提醒的是——這些方法再快、再炫,它們近似的對象仍然是本文討論的那個 $\mathbf{K}\mathbf{u}=\mathbf{F}$。一個分不清剪力鎖定與沙漏、不知道條件數會吃掉有效位數的人,就算手握最先進的 AI 求解器,也無法判斷它什麼時候在說謊。工具會一直進化,但對數值方法本質的理解,永遠是工程判斷的最後一道防線。