
如果留才是一道數學題,你的公式寫對了嗎?
深入人力資源管理的量化引擎:用效用模型估算甄選的金錢價值、用存活分析鎖定離職熱點,並看清 people analytics 的統計陷阱與倫理界線。
如果留才是一道數學題,你的公式寫對了嗎?
入門篇結尾留下一個尖銳的問題:一家公司明明薪水不低、績效評核也說員工「優良」,為什麼還是留不住人?我們當時的答案停在「內在報酬不足」這個概念層次。但如果你是這家公司的人資長,下個月董事會要你提出對策,你不能只說「我們要更重視員工的意義感」——你得回答更硬的問題:到底是誰會走?什麼時候走?我們花多少錢去攔,才划算?
這些問題不是靠直覺或座右銘能回答的。現代人力資源管理(Human Resource Management, HRM)有一整套量化機制,把「招募、留才、訓練」這些看似柔性的議題,轉譯成可以推導、可以驗證、可以算報酬率的工程問題。入門篇給了你地圖,這篇進階文章要帶你拆開引擎蓋,看看裡面的齒輪怎麼咬合:甄選的效用(utility)究竟能用金錢估算到什麼程度?離職為什麼要用存活分析(survival analysis)而不是單純算離職率?以及,當我們把「人」變成資料時,哪些統計陷阱會讓再漂亮的模型也誤導決策。
效用分析:一個好的甄選決策,到底值多少錢?
入門篇談到甄選方法的預測效度(predictive validity)有高低之分——結構化面試遠勝隨興聊天。但效度高,到底高出多少「價值」?這個問題在 1940 年代就有了精確的數學答案,稱為 Brogden–Cronbach–Gleser 效用模型。它的核心公式長這樣:
ΔU = N × T × r × SD_y × Z̄_s − C
別被符號嚇到,每一項都對應一個你直覺上就在意的東西:
- N:用這個方法錄取的人數。錄越多人,好甄選的價值放大越多。
- T:這些人平均會留任幾年。一個用得久的好甄選,效益是逐年累積的。
- r:甄選工具的效度係數(validity coefficient),也就是測驗分數與未來績效的相關。這是公式裡唯一直接反映「甄選好不好」的項。
- SD_y:員工績效換算成金錢後的標準差——意思是「一個績效在前段的員工,比一個普通員工,一年多創造多少價值」。這是整個模型最關鍵也最難估的數字。
- Z̄_s:錄取者在甄選測驗上的平均標準分數,反映你的錄取率(selection ratio)有多嚴格。你越能挑、越不缺應徵者,這項越大。
- C:施測的總成本。
這個公式給管理者三個違反直覺、卻極為重要的啟示。
第一,效度的價值是被「放大」的,不是孤立的。 因為 r 要乘上 N、T、SD_y,所以在一家大公司、職位留任久、且該職位績效差異很大(例如頂尖業務員和普通業務員的業績可能差好幾倍)的情境下,把甄選效度從 0.3 提升到 0.5,背後可能是數百萬甚至上千萬的價值差距。這解釋了一個常見的矛盾:為什麼大公司願意花重金做嚴謹的甄選流程,而小店家用聊天式面試就夠了——不是大公司比較講究,而是同樣的效度提升,在不同規模下值的錢差好幾個數量級。
第二,錄取率(selection ratio)本身就是一種槓桿。 即使你的測驗效度普通,只要應徵者夠多、你能挑得夠兇(Z̄_s 很大),甄選依然能創造可觀價值。反過來,如果職位乏人問津、來幾個就得錄幾個,再準的測驗也使不上力——因為你根本沒有挑選的空間。這就是為什麼「雇主品牌(employer branding)」與「擴大應徵漏斗」不只是行銷,而是直接提升甄選效用的前置條件。
第三,SD_y 揭露了一件殘酷的事:績效差異越大的工作,選才越重要。 在高度標準化、人人產出差不多的工作(流水線、收銀),換個更準的甄選方法省下的錢有限。但在創意、研發、銷售、管理這類「明星與庸才差距巨大」的工作,SD_y 極大,一個好的甄選決策的價值會被這個項狠狠放大。這也呼應了入門篇講的策略對齊——不同策略下的職位,連「值得在甄選上投資多少」都不一樣。
效度從哪裡來,又會在哪裡漏掉?
效用模型裡的 r(效度)看起來只是一個相關係數,但它其實是一池暗藏陷阱的水。進階學習者必須理解兩個會系統性「壓低」觀測效度的現象,否則你會嚴重低估好甄選工具的真實價值。
第一是測量誤差導致的衰減(attenuation)。 任何測驗分數都包含「真實能力」加上「隨機誤差」。如果你的績效評核本身就充滿入門篇提到的趨中、近因、月暈等偏誤,那麼它作為「效標(criterion)」就不可靠。而當你拿一個不可靠的效標去檢驗甄選工具,算出來的相關必然被稀釋——不是工具沒用,而是你的尺本身是歪的。這帶來一個反直覺的管理啟示:想知道你的甄選準不準,得先確保你衡量績效的方式夠可靠。 量尺有問題,整套驗證都會失真。
第二是全距限縮(range restriction)。 你只能觀察到「被錄取者」後來的績效,但被錄取的人,恰恰是甄選分數較高的那一群。低分者被你刷掉了,永遠看不到他們進來後會表現多差。這等於是只用「分數高的那一截」去算相關,自然會把效度算得偏低。經過統計校正後,許多甄選工具的「真實」效度,遠比公司內部草率估出來的數字高得多。
這兩個現象合起來,造就了 HRM 研究史上一個重要的方法論轉折——效度概化(validity generalization, VG)。Schmidt 與 Hunter 主張:過去人們以為「每個職位、每家公司都要各自驗證甄選工具」(情境特定論),其實大半是被上述兩種人為誤差騙了。當你把眾多研究做整合分析、並校正測量誤差與全距限縮後,會發現像「一般心智能力」這類工具的效度,在各行各業之間遠比想像中穩定。這個發現直接改變了實務:企業不再需要每換一個職位就從頭做一次昂貴的在地驗證,而可以合理援引已累積的證據。
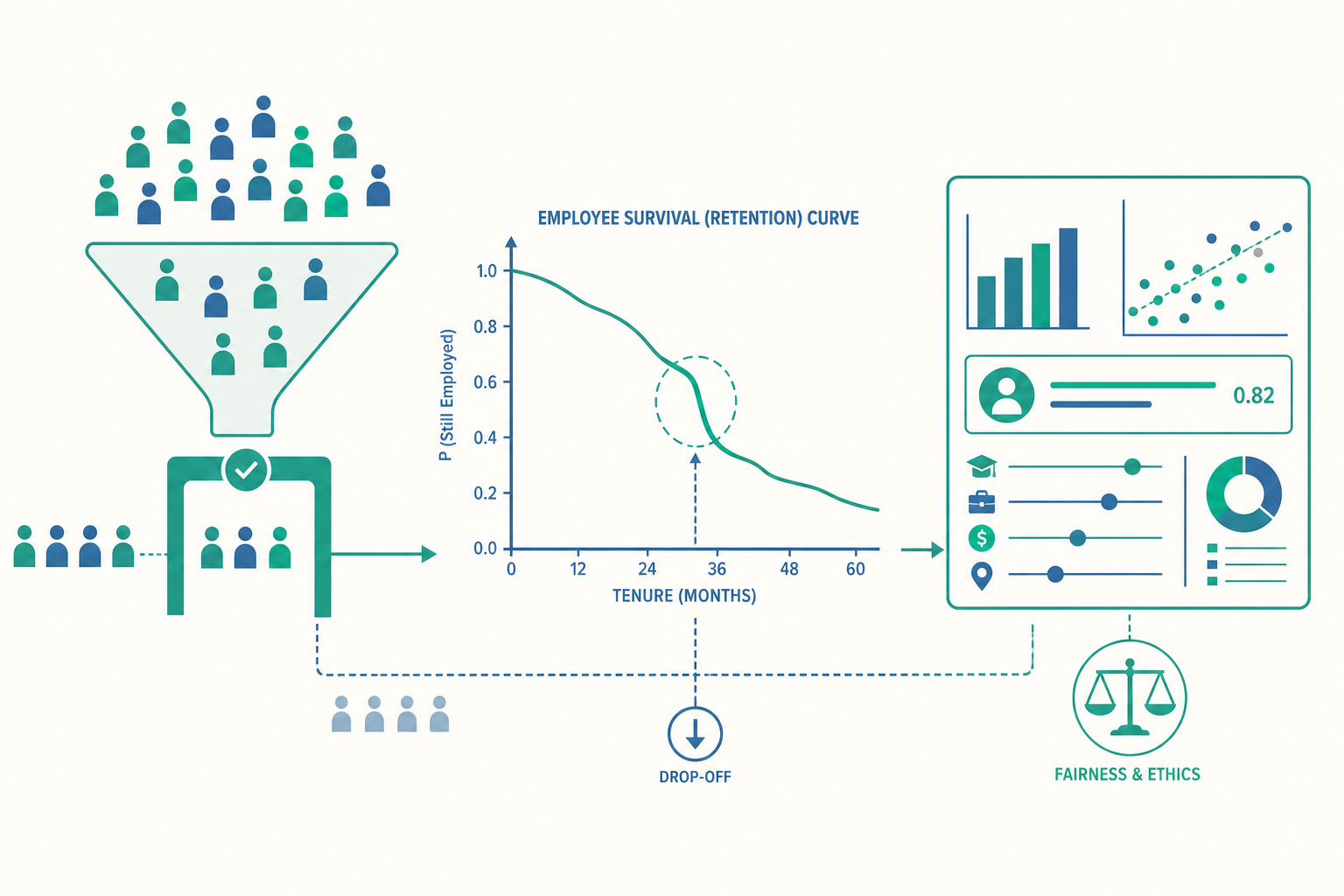
離職不是一個數字,而是一條時間曲線
回到開頭的留才難題。多數公司衡量流失,用的是一個簡單的比率:年離職率 = 當年離職人數 ÷ 平均在職人數。這個數字方便溝通,但對「該怎麼辦」幾乎沒有指導力,因為它把三種截然不同的故事壓成同一個數字:
- 是新人進來三個月就大批走人(招募/到職適應出問題)?
- 還是資深員工在第三、四年集體出走(升遷天花板、薪酬僵化)?
- 還是各年資都平均地流失(整體文化問題)?
要分辨這些,需要把問題從「有沒有走」升級為「多久之後走」。這正是存活分析(survival analysis)的用武之地——這套方法原本用來研究「病人服藥後存活多久」,借到 HR 就變成「員工到職後在職多久」。
它的核心是兩個概念。存活函數(survival function) S(t) 回答:「到職後第 t 個月,還留在公司的比例是多少?」把它畫成曲線,就是一條從 100% 緩緩下滑的「留任曲線」。曲線在哪個時間點掉得最陡,那裡就是你的「流失熱點」。第二個是風險率(hazard rate):在第 t 個月「還在職的人之中」,這個月離職的瞬時機率。風險率比存活率更銳利——它能告訴你「危險期」落在到職後第幾個月,讓你把留才資源精準投放到對的時間窗,而不是全程平均灑網。
存活分析還能優雅地處理一個傳統算法搞不定的問題:設限資料(censoring)。研究期間結束時,大部分員工根本還沒離職——你只知道他們「至少待了這麼久」,卻不知道最終會待多久。傳統離職率要嘛把這些人粗暴排除、要嘛假裝他們永不離職,兩種都會扭曲結論。存活分析的數學框架能正確地把「目前還在職」當作一筆有效但不完整的資訊納入估計,這是它在方法論上的決定性優勢。
更進一步,Cox 比例風險模型(Cox proportional hazards model) 能同時納入多個變項,估計「在控制其他因素後,某個特徵會讓離職風險增加或降低幾倍」。例如它可能告訴你:在控制部門與年資後,「過去一年沒有升遷或加薪」的員工,離職風險是其他人的 2.3 倍。注意這裡的措辭——風險倍數,不是宿命。模型給的是群體層次的關聯,幫你找到該優先處理的結構性因子,而非預言某個特定員工的命運。
看一個例子
假設一家連鎖餐飲集團把兩年內所有到職員工的留任資料畫成存活曲線,發現曲線在到職後第 2 到 4 個月掉得最陡——超過三成的離職都集中在這短短三個月內,之後曲線就趨於平緩。
如果只看「年離職率 28%」這個數字,管理層大概會得出「薪水太低、要全面加薪」的結論,然後砸下一筆橫跨全體的調薪預算。但存活曲線講的是完全不同的故事:撐過前四個月的人,其實相當穩定。 真正的問題不在薪資,而在「新人前期適應」——可能是職前訓練不足、現場主管沒空帶、排班讓新人有挫折感。
接著用 Cox 模型分析,發現「到職首月有指定資深員工帶教(buddy)」的新人,前四個月離職風險只有沒人帶者的四成。於是對策變得既精準又便宜:與其全體加薪,不如把資源投入「到職前 90 天的帶教制度」。 同一筆預算,效果可能天差地別。這就是為什麼進階 HR 要從「一個離職率」走向「一條存活曲線加一個風險模型」——前者讓你焦慮,後者讓你知道該動哪根槓桿。
動手試試
你不需要統計軟體也能體會存活分析的威力。找出你熟悉的一個社團、實驗室或打工團隊近兩年所有成員的「加入月份」與「離開月份」(還在的就記為「至今仍在」)。
- 把每個人換算成「待了幾個月」。對還在的人,標記為設限(你只知道下限)。
- 從第 1 個月開始,逐月計算「這個月還在的人當中,這個月離開的比例」——這就是你手算的風險率。
- 把每個月「留下來的比例」連乘起來,畫成一條下滑曲線——這就是存活曲線的雛形。
畫完後問自己:曲線在第幾個月掉得最陡?那個時間點周圍發生了什麼(學期壓力、幹部交接、缺乏新鮮感)?你會發現,光是把「離開」標上「何時離開」,洞察力就完全不同了。 這正是資料分析在 HRM 裡最樸素卻最有力的一步:別急著算總數,先把時間軸還原回來。
從預測到偏誤:people analytics 的雙面刃
把上述機制串起來——用效用模型決定甄選投資、用存活模型鎖定留才時機——你就握有了「人力資源分析(people analytics / HR analytics)」的雛形。它讓 HR 從「憑經驗的藝術」往「可驗證的科學」推進了一大步。但越是強大的工具,誤用的代價也越大,進階學習者必須同時看見它的暗面。
陷阱一:相關不是因果,而 HR 決策往往需要因果。 模型可能發現「參加過內部讀書會的員工升遷較快」,於是有人主張「多辦讀書會就能培養人才」。但真相可能是——本來就有上進心、能力強的人,才會去參加讀書會(自我選擇)。讀書會是結果不是原因。把這種相關當因果去訂政策,錢會花在錯的地方。要逼近因果,需要更嚴謹的設計(如準實驗、前後對照、傾向分數配對),而不是把任何顯著相關都當成行動依據。
陷阱二:演算法會把歷史偏見「洗白」成客觀。 如果你用過去的錄取與績效資料訓練一個甄選模型,而過去的決策本身帶有對某些群體的偏見,模型會忠實地學會這個偏見,並披上「資料驅動、客觀中立」的外衣繼續複製它。著名的案例是某科技巨頭曾訓練出一套會系統性低估女性履歷的招募 AI——因為它學習的歷史資料本身就由男性主導。模型不會自動變公平,它只會把你過去的不公平自動化、規模化。
陷阱三:被量化的勞動者。 當員工的一舉一動——打字速度、會議發言、線上時長——都被轉成可分析的資料,組織獲得了前所未有的洞察力,但也可能滑向持續監控。這不只是隱私的法律問題,更是「工作意義」的心理問題:當人感覺自己被當成一組待優化的指標,承諾與信任反而會被侵蝕。這正呼應 Uedu 所依循的 Educational Omics 框架中 Ethicomics(倫理規範) 維度的核心關切:當我們有能力大規模蒐集與分析「人」的資料時,技術的可能性與倫理的界線該如何拿捏。 分析能力越強,越需要透明、同意與治理機制來約束它。
重點回顧
- 甄選的價值可以被估算,而且會被規模放大。 Brogden–Cronbach–Gleser 效用模型顯示,效度(r)的價值會乘上人數、留任年數與績效金錢標準差(SD_y)——這解釋了為什麼大公司、明星型職位值得在選才上重金投入,小規模標準化職位則不必。
- 觀測到的效度通常被低估。 測量誤差導致的衰減與全距限縮會系統性壓低相關;效度概化(VG)告訴我們,校正後許多甄選工具的真實效度遠比在地草率估計穩定且偏高。
- 離職要看曲線,不要只看比率。 存活分析用存活函數與風險率揭露「何時走」的熱點,並能正確處理設限資料;Cox 模型能在控制其他因素後估出各因子的離職風險倍數。
- 找對時間窗,比全面加薪便宜。 把留才資源投放到存活曲線最陡的危險期(如新人前 90 天),往往比橫向灑網的加薪更有效。
- people analytics 是雙面刃。 警惕「相關當因果」、演算法放大歷史偏見、以及過度量化侵蝕信任——分析能力越強,越需要 Ethicomics 層次的倫理與治理。
深入探討(研究所視角)
對想進一步鑽研的讀者,本文觸及的量化 HRM 在學術上有幾條值得深掘的脈絡。
第一,效用模型的「無偏估計 vs. 經理人接受度」之爭。 效用分析在理論上嚴謹,但實務推廣卻屢屢碰壁——研究(如 Latham & Whyte 的經典實驗)發現,當把效用分析的「數百萬美元收益」估計呈現給管理者看時,反而降低了他們對方案的信心,因為數字大到不可信。這引出一個有趣的行為議題:技術上正確的決策工具,若違背決策者的心理直覺,未必能被採納。這把 HRM 與行為決策理論(behavioral decision theory)連在了一起,也提醒我們 SD_y 的估計法(如「全球估計法」直接問主管心中的金錢價值)本身就是一個未竟的方法論戰場。
第二,離職的理論模型,而不只是統計模型。 本文聚焦存活分析這個「方法」,但離職背後有豐富的「理論」。從 March 與 Simon 的「離職的易動性與意願(ease and desirability of movement)」、到 Mobley 的離職決策過程模型、再到近年 Lee 與 Mitchell 的展開模型(unfolding model)——後者主張許多離職並非長期不滿累積,而是被某個「震撼事件(shock)」(被挖角、結婚、與主管衝突)瞬間觸發。這對留才實務的啟示截然不同:若離職是被 shock 觸發的,那麼預測「整體滿意度」可能抓不到關鍵,反而要關注關鍵事件的應對。把這套理論與存活分析的時變共變量(time-varying covariates)結合,是當前研究的活躍方向。
第三,因果推論在 people analytics 的方法論前沿。 HR 資料幾乎都是觀察性的(你不能隨機指派員工去離職或升遷),這讓因果推論格外困難。如何在不能做隨機實驗的情境下逼近因果——傾向分數配對(propensity score matching)、雙重差分(difference-in-differences)、工具變數、斷點回歸(regression discontinuity,例如利用「績效剛好過升遷門檻」的準隨機性)——正成為嚴謹 HR 研究與商業計量經濟學交會的熱點。能區分「我的模型只是預測」與「我的模型支持因果宣稱」,是進階研究者的關鍵素養。
第四,演算法管理的規範性研究與治理。 隨著歐盟《人工智慧法案》等規範把「就業領域的 AI」列為高風險應用,HRM 研究正快速擴展到演算法公平性(algorithmic fairness)、可解釋性(explainability)與勞動者權益的交叉地帶。這裡的問題不再只是「模型準不準」,而是「準了之後,誰受益、誰受害、由誰負責、能否申訴」。建議的延伸閱讀方向包括:效用分析方法論(Boudreau & Ramstad 的決策科學取向)、離職展開模型(Lee & Mitchell)、HR 因果分析的實務(people analytics 的計量經濟學應用),以及演算法管理的批判性回顧(Kellogg、Valentine 與 Christin 等人對「演算法作為新管理控制」的研究)。這些議題共同指向一個核心命題——把人變成資料之後,管理學要重新回答的,是效率與尊嚴如何並存。