
把「最強五人」湊在一起,為什麼會輸給「組合對的五人」?
從斷層線、史坦納過程損失公式到集體智慧與人—AI 團隊,拆解團隊績效背後的組成科學與協調機制。
把「最強五人」湊在一起,為什麼會輸給「組合對的五人」?
你已經知道團隊不等於群體,也知道塔克曼(Bruce Tuckman)的形成、風暴、規範、執行四個階段。現在換一個更刁鑽的問題:假設你手上有十位能力都很頂尖的工程師,要組成兩支五人團隊,你會怎麼分?
直覺答案是「把最強的五個放一隊」。但組織行為的實證研究一再告訴我們:團隊績效不是成員能力的加總,而是成員能力如何被組合、如何被協調、如何彼此補位的函數。同樣一批人,換一種組合方式,產出可能差一倍。換句話說,團隊是一種「設計問題」,而不只是「選才問題」。
入門篇談的是「團隊是什麼、會怎麼演化、會有哪些內耗」。這篇進階文章要往下鑽三層:第一,團隊的組成科學(composition)——多元到底幫不幫得上忙、什麼時候會反咬一口;第二,把「人多反而變糟」這件事用史坦納(Steiner)的過程損失公式講清楚,並引介近十年最重要的發現之一「集體智慧因子」;第三,當團隊走向遠距、跨域,甚至有 AI 成員時,那些為「人—人面對面」設計的構念還站得住腳嗎。
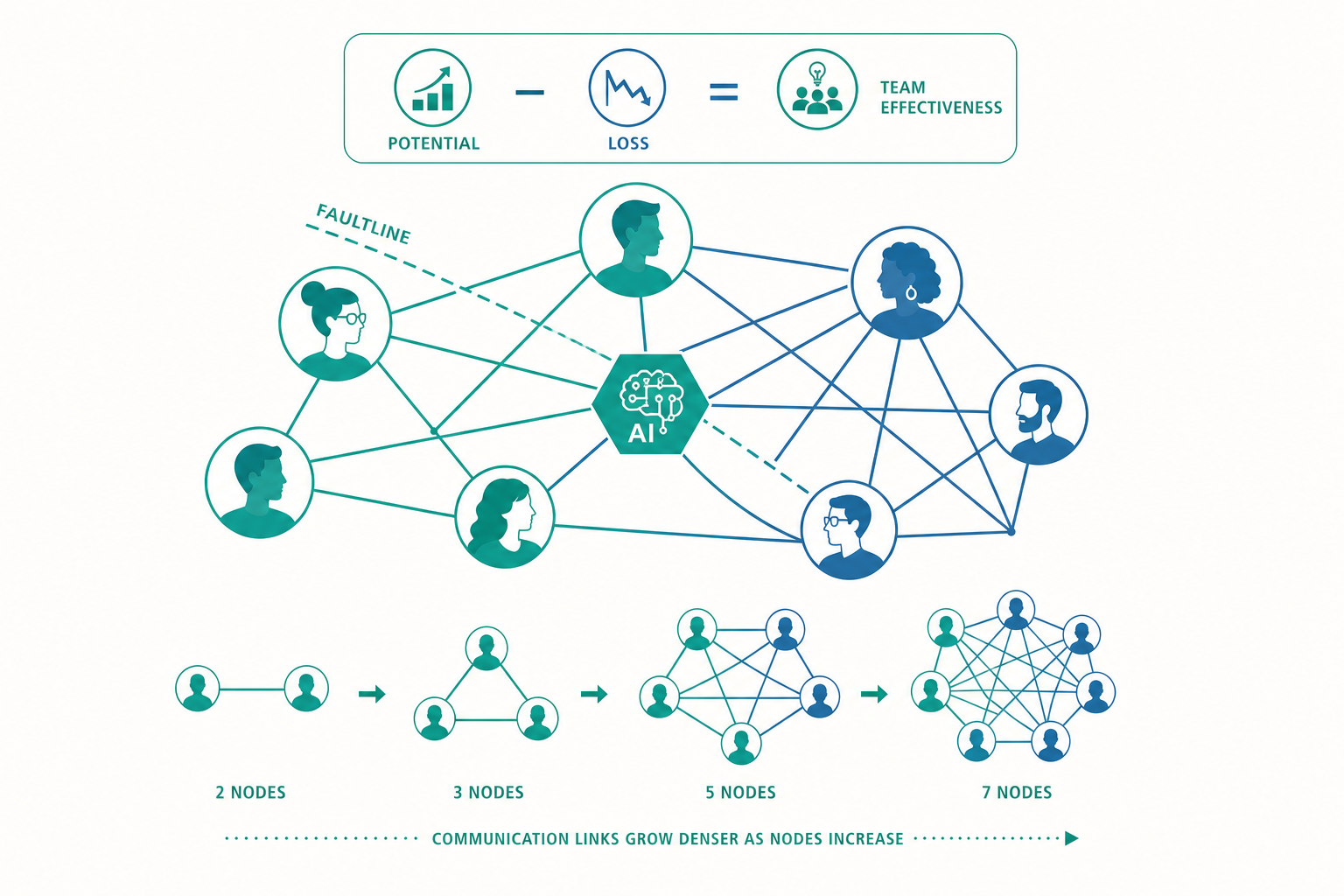
多元的兩面刃:斷層線(faultlines)才是關鍵變數
「團隊要多元」幾乎成了管理常識,但實證結果其實相當混亂——有些研究發現多元提升創意與決策品質,有些卻發現多元拖垮凝聚力與溝通效率。問題出在我們把「多元」當成一個籠統的詞。
研究者把團隊多元拆成兩類。表層多元(surface-level diversity)指年齡、性別、族裔等一眼可辨的特徵;深層多元(deep-level diversity)指價值觀、人格、專業知識、思考方式等需要互動才會浮現的差異。哈里森(David Harrison)等人的研究發現一個有意思的時間動態:團隊剛組成時,表層差異的影響較大(人會本能地用可見特徵分類彼此);但隨著相處時間拉長,表層差異的效果逐漸消退,深層差異才真正開始左右團隊的合作品質。這解釋了為什麼「短期專案靠表面相似快速磨合,長期團隊靠深層契合走得遠」。
真正把多元研究推進一大步的,是萊歐(Dora Lau)與默尼根(Keith Murnighan)在 1998 年提出的斷層線(faultlines)概念。斷層線指的是團隊中多個屬性同時對齊所形成的假想分界線。請看兩支同樣「兩位資深男性工程師 + 兩位資淺女性設計師」的團隊:
- A 隊:兩位資深的恰好都是男性工程師、兩位資淺的恰好都是女性設計師——年齡、性別、專業三條線完全重疊。
- B 隊:資深的一男一女、工程師裡有男有女——同樣的屬性分布,但屬性彼此交錯而非對齊。
兩隊的「多元程度」(用任何單一維度算都一樣),但 A 隊有一條又深又清楚的斷層線:團隊很容易裂成「資深男工程師」對「資淺女設計師」兩個次群體(subgroup),溝通在裂縫處中斷、信任沿著裂縫流失。B 隊的屬性交錯,沒有任何單一分界能把團隊一刀切開,反而更容易整合。
斷層線理論的價值在於:它解釋了為什麼「多元」有時加分、有時扣分——重點不是團隊有多不一樣,而是這些差異是否在同一條線上對齊。給主管的實務啟示很直接:組隊時要刻意「打散對齊」,讓不同屬性交錯分布;當斷層線已經存在時,可以透過共同的上位目標(superordinate goal)、跨次群體的角色設計(讓每個人都得跟「另一邊」的人合作才能完成任務)來「橋接」裂縫。
把內耗算給你看:史坦納的過程損失公式
入門篇用社會惰化(social loafing)解釋了「為什麼人多不一定力量大」,但那只是冰山一角。心理學家史坦納(Ivan Steiner)在 1972 年提出一條簡潔卻深刻的式子,把整件事說透了:
實際生產力(actual productivity)= 潛在生產力(potential productivity)- 過程損失(process losses)
潛在生產力是「在資源與任務限制下,理論上能達到的最佳表現」;過程損失則是「協調不良與動機不足吃掉的部分」。過程損失又分兩種:
- 動機損失(motivation loss):成員少出力,社會惰化就屬於這類。
- 協調損失(coordination loss):就算每個人都全力以赴,把力氣「對準同一個方向、在對的時間」本身就有成本。拔河時八個人合力小於八人單拉總和,除了有人偷懶,更因為大家施力的時機與方向無法完全同步——這部分是純粹的協調損失,跟動機無關。
這條式子最大的洞見是:團隊規模擴大時,潛在生產力線性增加,但協調損失卻以更快的速度上升。 因為溝通連結數隨人數呈組合成長——n 個人之間有 n(n−1)/2 條溝通通道,5 個人有 10 條,10 個人就跳到 45 條。某個臨界點之後,多加一個人帶來的潛在貢獻,會被它帶來的協調成本吃光甚至倒貼。這正是「兩個披薩原則」背後真正的數學,也是為什麼 Amazon、Spotify 等公司寧可拆成許多小隊,也不願維持龐大團隊。
史坦納還指出,任務類型決定了損失的形態。對於連加性任務(additive,如拔河、眾人搬磚,產出是個別加總),協調損失最致命;對於選優性任務(disjunctive,團隊表現取決於最強成員,如解一道難題),重點是別讓對的答案被多數人壓下去(群體迷思的風險);對於連乘性任務(conjunctive,團隊表現取決於最弱成員,如登山隊以最慢者為準),重點則是補強短板。先判斷任務類型,再決定該優化哪一種損失——這是史坦納框架給管理者最實用的診斷工具。
看一個例子:為什麼「加一個人救火」常常越救越糟
軟體業有一條著名的「布魯克斯定律」(Brooks's Law):對一個已經延遲的軟體專案增派人手,只會讓它更延遲。 這聽起來違反常識——專案落後,多找人來幫忙不是天經地義嗎?
用史坦納的公式一拆就清楚了。新人加入,潛在生產力確實增加(多了一雙手);但同時帶來兩筆過程損失。第一筆是訓練成本:新人得先搞懂既有架構、規範與進度,這段期間原本的高手必須抽身來帶人,團隊整體產能反而暫時下降。第二筆正是協調損失:溝通通道從 n(n−1)/2 暴增,每個介面都得重新對齊、每個決策都得多繞幾個人。當任務本身高度互賴、又處在時間壓力下時,這兩筆損失往往遠超過新人帶來的潛在貢獻。
這個例子的啟示不是「絕對不能加人」,而是:加人是有條件的。如果任務可以乾淨切割成獨立模組(降低互賴、壓低協調損失),加人就有效;如果任務糾纏在一起、又趕時間,加人反而是把火澆上油。判斷的關鍵,永遠是「這項任務的過程損失,主要來自動機還是協調」。
集體智慧因子:團隊也有「智商」嗎?
個人有相對穩定的一般智力因子(g factor),能跨任務預測表現。一個自然的問題是:團隊是否也存在一個類似的「集體智慧」因子,能跨任務預測團隊表現?
2010 年,伍利(Anita Woolley)、馬隆(Thomas Malone)等人發表在《Science》的研究給出了肯定的答案。他們讓數百個小團隊完成各式各樣的任務(腦力激盪、視覺拼圖、道德判斷、協商談判),結果發現團隊在各類任務上的表現確實高度相關——存在一個可測量的集體智慧因子(collective intelligence, 簡稱 c factor)。
更震撼的是什麼預測了 c、什麼沒有:
- 沒有顯著預測力的,竟然是「成員的平均智商」與「最聰明成員的智商」。把一群高智商的人湊在一起,並不保證高集體智慧。
- 真正預測 c 的有三件事:第一,成員的社會敏感度(social sensitivity,能讀懂他人情緒與意圖的能力,用「以眼讀心」測驗衡量);第二,發言輪流的平均度——由一兩個人壟斷發言的團隊,集體智慧顯著較低;第三,團隊中女性成員的比例(後續研究指出,這多半是透過社會敏感度這個中介變數起作用,而非性別本身)。
這個發現對管理的衝擊很大:它從實證上佐證了入門篇提到的「心理安全感」與「均衡參與」並非軟性口號,而是集體智慧的硬性結構條件。一個被少數人主導、不擅讀懂彼此的團隊,無論成員個人多優秀,集體都「變笨」了。後續研究也發現,這個 c 因子在線上、非同步的遠距團隊中同樣存在——但維持它的條件(尤其是輪流發言的均衡度)在缺乏面對面線索的環境裡更難達成。這正好把我們帶到下一個前沿。
當團隊散落各地、甚至有 AI 成員
過去二十年,團隊的型態被科技徹底重塑。傳統團隊理論大多奠基於「同時、同地、面對面」的小團隊;但今天的團隊愈來愈虛擬化(virtual,跨地點、靠數位工具協作)、跨時區非同步,甚至開始納入 AI 代理人作為成員。為人—人面對面設計的那套構念,需要重新檢視。
交換記憶系統(transactive memory system, TMS) 是個好切入點。這個由韋格納(Daniel Wegner)提出的概念指的是團隊的「分散式記憶」——團隊不需要每個人都記得所有事,只要每個人都清楚『誰知道什麼』(who knows what),需要時就能找到對的人。成熟的 TMS 有三個特徵:專業分工(specialization,知識分散儲存)、可信賴度(credibility,相信對方的專業)、協調(coordination,能順暢調用彼此的知識)。研究顯示 TMS 強的團隊在複雜任務上顯著更有效率——這其實是把「團隊比個人聰明」這件事的機制講白了:不是每個人都變強,而是團隊學會了不重複儲存、精準調用。
問題來了:TMS 高度依賴日常的非正式互動來建立與更新(你在茶水間聽到同事抱怨某個 API,就默默更新了「誰懂這個」的地圖)。在遠距非同步團隊裡,這些偶遇消失了,「誰知道什麼」的地圖更容易過時、出錯。這解釋了為什麼遠距團隊需要更刻意地維護共享知識:明確的技能標籤、可搜尋的文件、定期的知識同步,本質上都是在用制度補上自然互動流失的 TMS 維護機制。
再往前一步是人—AI 團隊(human-AI teaming)。當團隊成員之一是 AI 時,許多經典構念都得重新定義:
- TMS 怎麼算? 人類成員需要建立「AI 知道什麼、不知道什麼、什麼時候會出錯」的心智模型。但 AI 的能力邊界往往不透明、且會隨版本更新而變動,使得「可信賴度」這一支特別難校準——過度信任會釀成自動化偏誤(automation bias),過度不信任又浪費了 AI 的價值。
- 心理安全感對誰而言? 心理安全感原本描述的是人際風險。當隊友是 AI,人類成員「向 AI 承認錯誤、提出蠢問題」的心理門檻確實較低(AI 不會嘲笑你),但這也帶來新風險:人可能對 AI 過度坦白、或把該由人承擔的判斷外包出去。
- 共享心智模型從「人對人、人對任務」擴展到「人對 AI、AI 對人」的相互理解,且這份理解必須是雙向且動態的。
這些問題目前都還沒有定論,正是組織行為與資訊系統交會處最活躍的研究前沿。對學習管理的人來說,重點不是背下哪個理論,而是培養一種判斷力:當情境的基本假設(同地、同步、全人類)改變時,哪些構念依然成立、哪些需要被修正。 這正是把入門知識升級成研究級理解的關鍵一步。
動手試試:用三個問題診斷一支真實團隊
挑一支你親身待過、且印象深刻(無論成功或失敗)的團隊——社團幹部、實習專案、課程分組都可以。用這篇的進階工具問自己三個問題:
- 斷層線在哪? 列出成員的關鍵屬性(年資、專業、價值觀、甚至作息)。這些屬性是「交錯分布」還是「沿同一條線對齊」?如果團隊曾經裂成兩派,那條裂縫是不是正好落在多個屬性同時對齊的地方?
- 過程損失主要是哪一種? 當團隊表現不如預期,是因為有人不出力(動機損失),還是大家都很拼但力氣沒對準、決策來回打結(協調損失)?這兩種病,藥方完全不同——動機損失要靠「讓貢獻可見」,協調損失要靠「縮小團隊、釐清介面」。
- 集體智慧的結構條件具備嗎? 發言是輪流均衡,還是被一兩個人壟斷?成員之間讀得懂彼此的情緒與意圖嗎?如果這兩項都不及格,再厲害的個人也救不了集體。
你會發現,同一段團隊經驗,用這三個進階透鏡重看,能診斷出比「大家不夠努力」「溝通不良」更精準的病因——而精準的診斷,才是有效介入的前提。
重點回顧
- 多元的效果取決於「斷層線」而非多元程度本身:當多個屬性沿同一條線對齊,團隊容易裂成次群體;刻意讓屬性交錯分布、用上位目標橋接裂縫,才能讓多元加分而非扣分。
- 史坦納公式拆解了內耗:實際生產力=潛在生產力-過程損失,而過程損失分為動機損失與協調損失;團隊變大時協調損失(隨溝通通道 n(n−1)/2 成長)往往吃掉新增的潛在貢獻,這是布魯克斯定律與兩個披薩原則的共同數學基礎。
- 先判斷任務類型再優化損失:連加性、選優性、連乘性任務各有不同的致命損失與對策,診斷錯了,介入就會無效。
- 集體智慧(c factor)真實存在,但不由平均智商決定:社會敏感度、均衡的發言輪流,才是預測團隊跨任務表現的關鍵,從實證上佐證了心理安全感與均衡參與的硬價值。
- 遠距與人—AI 團隊改寫了遊戲規則:交換記憶系統、心理安全感、共享心智模型等構念在缺乏面對面互動、甚至有 AI 成員時都需要重新校準——能判斷哪些假設改變、哪些理論需修正,是研究級理解的標誌。
深入探討(研究所視角)
想把團隊研究做深的讀者,有幾條值得追蹤的方法論與理論前沿。
從「組成」到「組構」:超越線性聚合。 早期團隊組成研究多採用簡單的聚合指標——把成員特質取平均(mean)或變異(variance)來代表團隊。但這種做法抹掉了「結構」資訊:同樣的平均與變異,可以對應完全不同的斷層線結構。當代研究因此轉向更細緻的組構模型(compositional / configural models),例如用斷層線強度演算法(Thatcher、Meyer 等人發展的距離式指標)捕捉次群體分裂的潛勢,或用社會網絡分析刻畫團隊內部的關係結構。核心方法論議題是:個體層次的屬性,該用什麼函數形式聚合到團隊層次,才不會喪失理論上重要的訊息。這與入門篇談的多層次分析(multilevel modeling)、聚合適切性指標(r_wg、ICC)是同一套問題的延伸。
時間動態與團隊歷程的密集追蹤。 團隊是隨時間演化的動態系統(呼應入門篇談的 IMOI 循環模型),但傳統橫斷面研究只能拍下一張快照。近年方法論的重要進展是密集縱貫設計(intensive longitudinal designs)——透過經驗取樣(experience sampling)、團隊互動的逐分鐘編碼、乃至感測器與數位足跡(digital trace data,如協作平台的訊息流、程式碼提交紀錄),高頻率地捕捉團隊歷程如何隨時間湧現與消退。這讓研究者得以檢驗「湧現狀態」(emergent states,如信任、TMS、共享心智模型)究竟是如何一步步形成的,而非只在事後測量其結果。
人—AI 團隊的構念效度危機與轉機。 前文提到,當隊友是 AI 時,心理安全感、TMS、共享心智模型等構念面臨構念效度(construct validity)的根本挑戰:這些測量工具與理論假設,原本都預設「對方是人」。一個尖銳的研究問題是——當我們把「人對 AI 的信任」硬塞進「人際信任」的量表,測到的究竟是同一個東西,還是貌合神離的另一個構念?這牽涉到測量恆等性(measurement invariance)的檢驗,也牽涉到理論上是否需要為「人—機團隊」另立一套構念體系。對有志於組織行為、人機互動或資訊系統的研究者,這片交界地帶幾乎每個經典構念都值得重新提問一次——而每一次重新提問,都可能是一篇有貢獻的論文的起點。