
當方程式比未知數還多,或還少:程序衡算真正的勝負手
從自由度分析、反應進度到含再循環流程的撕裂與聯立求解,看程序模擬器引擎蓋底下真正在解什麼。
當方程式比未知數還多,或還少:程序衡算真正的勝負手
入門篇教過你「畫一個框、寫下守恆律」。但真到了一張畫滿管線、有反應、有再循環(recycle)、有放空(purge)的程序流程圖(flowsheet)前面,多數人卡住的地方不是不會寫平衡式,而是——寫出一堆方程式之後,根本不知道該從哪一條先解。
更糟的情況有兩種:方程式比未知數還少,問題無解(under-specified,欠定);或方程式比未知數還多,問題互相矛盾(over-specified,過定)。一個訓練有素的化學工程師,在動筆計算前,會先做一件入門課很少強調、卻決定成敗的事——自由度分析(degree-of-freedom analysis)。它回答的問題很單純卻致命:「這個問題,到底解不解得出來?」
本文假設你已經熟悉總質量平衡、成分平衡、能量平衡與轉化率的寫法。我們要往前一步,談的是「怎麼把這些平衡式組成一個可解的系統,並在含再循環的真實程序中收斂出答案」。這正是程序模擬軟體(Aspen Plus、DWSIM)引擎蓋底下真正在做的事。
自由度分析:計算之前的計算
自由度(degree of freedom, DOF)的定義是:
$$N_{\text{DOF}} = N_{\text{unknowns}} - N_{\text{independent equations}}$$
判讀規則乾淨俐落:
- $N_{\text{DOF}} = 0$:問題恰好設定(well-specified),理論上有唯一解,可以放心計算。
- $N_{\text{DOF}} > 0$:欠定,未知數太多。你必須再指定 $N_{\text{DOF}}$ 個設計變數(design variable,例如進料流率、轉化率、某股回收比例),問題才封閉。
- $N_{\text{DOF}} < 0$:過定,方程式太多。要嘛你誤把不獨立的式子當成獨立,要嘛量測資料彼此衝突(這正是後面要談的資料校正問題的起點)。
關鍵在於 $N_{\text{independent equations}}$ 這個「獨立」二字。對一個有 $C$ 個成分的單元,你能寫的質量平衡式總數是 $C$ 條成分平衡,或者「$C-1$ 條成分平衡 $+ 1$ 條總質量平衡」——但這兩組不能同時全用,因為總質量平衡只是所有成分平衡的加總,並非獨立資訊。初學者最常見的錯誤,就是把總平衡和全部成分平衡都算進去,導致誤判為過定。
動手試試:數一座分離器的自由度
考慮一個穩態氣液分離器(flash drum),進料含 3 個成分($C=3$),分成氣相產品與液相產品兩股輸出。先數未知數:
- 每股的「總流率 + 各成分組成」。一股 3 成分的物流,獨立變數是 1 個流率 $+$ $(3-1)=2$ 個莫耳分率 $= 3$ 個。三股(進料、氣、液)共 $3 \times 3 = 9$ 個變數。
- 通常進料完全已知(給定流率與兩個組成,3 個值)。
獨立方程式:
- 成分質量平衡:$C = 3$ 條。
- 相平衡關係(phase equilibrium):每個成分一條 $y_i = K_i x_i$,共 3 條。
- 莫耳分率歸一($\sum y_i = 1$、$\sum x_i = 1$):這兩條若你已用「$C-1$ 個分率 $+$ 流率」來描述每股,就已內含、不可重複計入。
於是:
$$N_{\text{DOF}} = \underbrace{9}_{\text{變數}} - \underbrace{3}_{\text{已知進料}} - \underbrace{3}_{\text{成分平衡}} - \underbrace{3}_{\text{相平衡}} = 0$$
DOF 為零,問題封閉,可解。但若你忘了相平衡那 3 條(只當它是「把進料分兩半」的黑箱),$N_{\text{DOF}} = 3$——系統告訴你「資訊不足,氣液怎麼分你還沒講清楚」。自由度分析的價值,就是在你浪費半小時亂解之前,先告訴你問題到底缺什麼。
反應系統:用反應進度取代一堆轉化率
入門篇用「轉化率 $X_A$」處理反應。但當系統裡有多個獨立反應同時進行(例如甲烷重組同時發生重組與水煤氣轉移),逐一追蹤每個成分的生成消耗會讓未知數爆炸。研究所層級的做法,是改用反應進度(extent of reaction)$\xi$ 作為核心變數。
對第 $k$ 個反應,定義反應進度 $\xi_k$(單位 mol/time),則成分 $i$ 的出口莫耳流率可以寫成一個漂亮的線性組合:
$$\dot{n}_{i,\text{out}} = \dot{n}_{i,\text{in}} + \sum_{k} \nu_{ik}\, \xi_k$$
其中 $\nu_{ik}$ 是成分 $i$ 在反應 $k$ 中的化學計量係數(stoichiometric coefficient,反應物為負、產物為正)。這個寫法的威力在於:不論系統有幾個成分,未知的反應變數只有「獨立反應的數目」這麼多個。
獨立反應的數目怎麼定?它等於化學計量矩陣(stoichiometric matrix)$\boldsymbol{\nu}$ 的秩(rank)。換句話說,你列出所有可能發生的反應後,真正貢獻自由度的只有線性獨立的那幾條。這把「反應使自由度增加多少」這個問題,從手工數數變成一個線性代數問題——也是為什麼程序模擬器內部全用矩陣運算。
看一個例子:用反應進度算多反應出口
合成氣(syngas)反應器中同時進行兩個反應:
$$\text{(R1)}\quad \mathrm{CO} + 2\mathrm{H_2} \rightarrow \mathrm{CH_3OH}$$ $$\text{(R2)}\quad \mathrm{CO_2} + 3\mathrm{H_2} \rightarrow \mathrm{CH_3OH} + \mathrm{H_2O}$$
進料:$\mathrm{CO}=100$、$\mathrm{CO_2}=50$、$\mathrm{H_2}=350$(mol/min)。假設由實驗或平衡求得 $\xi_1 = 80$、$\xi_2 = 30$ mol/min。求甲醇與氫氣出口流率。
甲醇($\mathrm{CH_3OH}$)只生成、不進料,計量係數在兩反應中皆為 $+1$:
$$\dot{n}_{\mathrm{CH_3OH}} = 0 + (1)(80) + (1)(30) = 110 \text{ mol/min}$$
氫氣($\mathrm{H_2}$)在 R1 係數 $-2$、R2 係數 $-3$:
$$\dot{n}_{\mathrm{H_2}} = 350 + (-2)(80) + (-3)(30) = 350 - 160 - 90 = 100 \text{ mol/min}$$
不必逐成分追轉化率,兩個 $\xi$ 就把所有 5 個成分的出口流率一次鎖定。這就是反應進度法在多反應系統的優雅之處——它把「反應」這件事壓縮成最少的自由度。
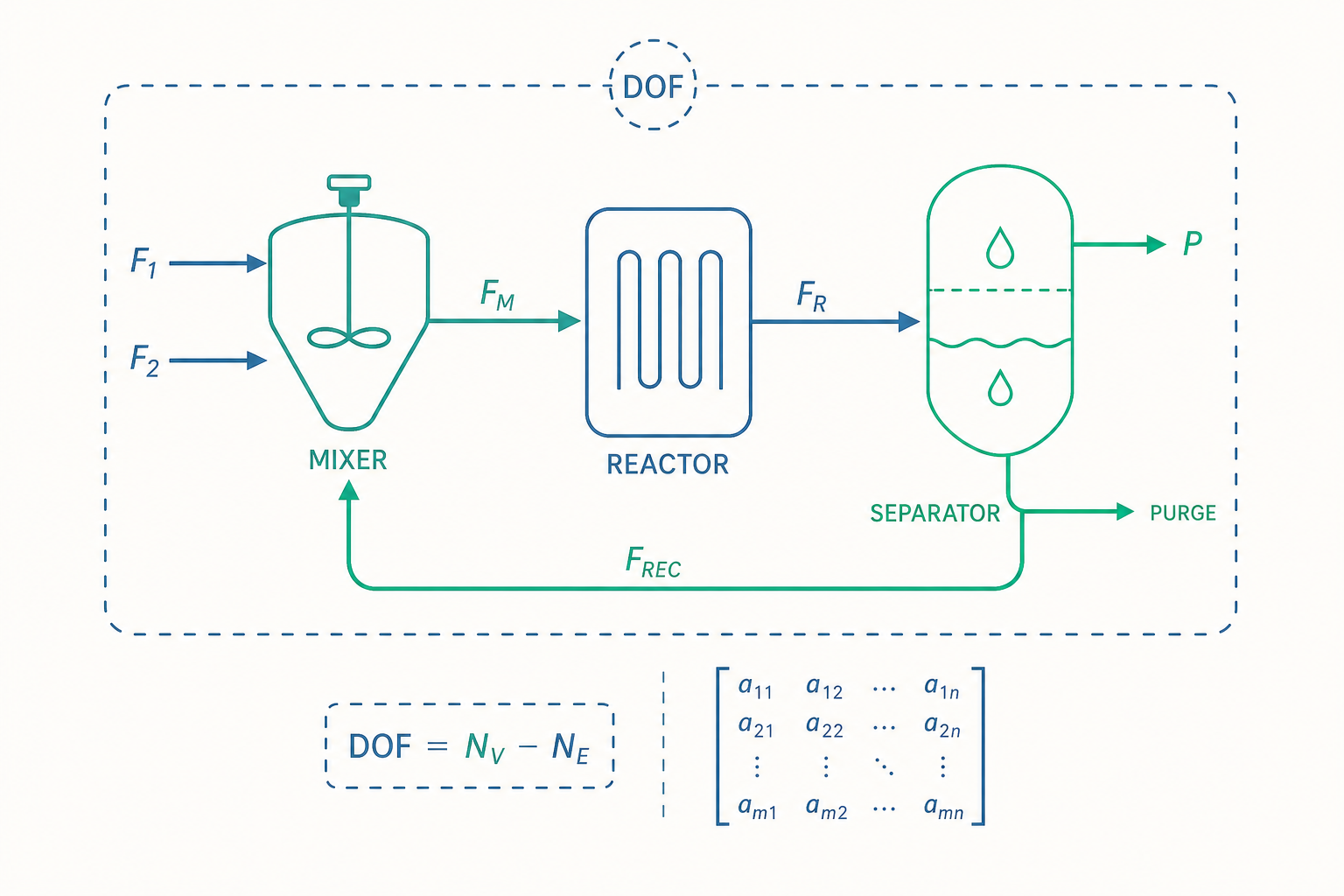
真正的難關:再循環讓方程式糾纏成一團
入門篇結尾提過再循環會讓平衡式互相耦合。這裡我們把它說透,因為這是程序衡算從「習題」變成「真實工程」的分水嶺。
考慮一個帶再循環的典型流程:新鮮進料(fresh feed)混入再循環流後進反應器,反應器出口經分離器,產品取出、未反應原料循環回去。問題的麻煩在於:要算混合器的出口,你得知道再循環流;但再循環流來自分離器,而分離器要算又得先知道反應器出口,反應器又依賴混合器出口…… 形成一個首尾相咬的閉環,沒有任何一個單元能「第一個被解」。
工程上有兩種策略破解:
循序模組法(sequential modular, SM)+ 撕裂(tearing)。 既然閉環無法逐一順序解,那就「剪斷」它:選定再循環流為撕裂流(tear stream),先猜一組初值,假裝它已知,順著流程算一整圈,回到撕裂點時得到一組「新算出的」再循環流值。比較猜測值與計算值,若不一致就用計算值更新猜測,再算一圈,直到前後兩圈差異小於容許誤差——收斂(convergence)。這個迭代常用 Wegstein 法或直接代入加速,是 Aspen Plus 預設引擎的核心。
方程導向法(equation-oriented, EO)。 不剪斷,而是把整廠所有單元的質能平衡式全部攤開,組成一個巨大的非線性方程組 $\mathbf{F}(\mathbf{x}) = \mathbf{0}$,再用 Newton–Raphson 法一次性聯立求解:
$$\mathbf{x}^{(m+1)} = \mathbf{x}^{(m)} - \mathbf{J}^{-1}\big(\mathbf{x}^{(m)}\big)\, \mathbf{F}\big(\mathbf{x}^{(m)}\big)$$
其中 $\mathbf{J} = \partial \mathbf{F} / \partial \mathbf{x}$ 是 Jacobian 矩陣。EO 法收斂快、適合做優化(梯度資訊現成),但初值敏感、除錯困難。現代模擬器多半兩者並用:SM 求一個好初值,EO 收尾並做優化。
一個你必須懂的設計直覺:放空與惰性累積
再循環有個反直覺的陷阱。假設進料含有少量惰性氣體(inert,例如氮氣),它不反應、不被分離器移除,於是每循環一圈就累積一點。若不處理,惰性會在循環中無限累積直到系統崩潰。解法是在再循環管路上開一個放空口(purge stream),持續排掉一小股。
穩態下,對惰性做質量平衡會得到一條極簡潔的關係:惰性的進料速率必須等於放空速率(因為惰性既不生成也不消耗,又不從產品離開):
$$\dot{n}_{\text{inert, fresh feed}} = \dot{n}_{\text{inert, purge}}$$
這條式子讓你能直接定出放空率,而循環流中惰性的濃度,則由放空比例決定。放空太小,惰性濃度飆高、稀釋反應物;放空太大,又把寶貴的未反應原料一起丟掉。這個取捨本身就是一個優化問題——而它的可行域,完全由質量平衡界定。
質量與能量何時必須一起解
入門篇把質量平衡和能量平衡分兩步處理:先算完物流,再算熱量。對「等溫」或「物性與溫度無關」的理想情況,這個解耦(decoupling)成立。但真實程序裡,兩者常是雙向耦合的:
- 反應速率 $r$ 對溫度高度敏感(Arrhenius 關係 $r \propto e^{-E_a/RT}$),溫度變一點,轉化率、進而所有物流組成都跟著變——能量影響質量。
- 反應放熱量 $\propto$ 反應進度 $\xi$,而 $\xi$ 又取決於組成——質量影響能量。
當這兩條回路咬在一起,質量平衡與能量平衡必須聯立求解,不能先後解。這正是非絕熱 CSTR 著名的「多重穩態(multiple steady states)」現象的根源:同一組進料條件,質能耦合方程可能有 3 個數學解(低轉化率、中、高),其中中間那個是不穩定的。哪一個是工廠實際運轉的點,取決於開車路徑——這已經是非線性動力學的領域了,而它的起點,不過就是「質量平衡和能量平衡不肯分開解」這件事。
$$\underbrace{\dot{n}_{A,\text{in}} - \dot{n}_{A,\text{out}} - r(T)\,V = 0}_{\text{質量平衡(含 }T\text{)}} \quad\Big|\quad \underbrace{\dot{Q} + (-\Delta H_{\text{rxn}})\,r(T)\,V - \dot{n}C_p(T-T_{\text{in}}) = 0}_{\text{能量平衡(含組成)}}$$
兩條式子裡都同時藏著 $T$ 與組成,這就是「必須一起解」的數學長相。
質能衡算與優化學的進階連結
入門篇說過質能平衡是優化的等式約束。進階視角要補上一點:約束的數學性質,決定了優化問題的難度。
- 純質量平衡(無反應、線性混合)通常是線性約束,配上線性目標就是線性規劃(LP),全域最佳解唾手可得。
- 一旦加入相平衡、反應動力學、能量耦合,約束變成非線性、甚至非凸(non-convex)。優化問題升級為非線性規劃(NLP),可能有多個局部最佳解——對應前面說的多重穩態。
- 若再加入「設備要不要建」這類整數決策(程序合成、流程結構選擇),就成了混合整數非線性規劃(MINLP),是程序系統工程最硬核的計算難題。
換句話說,你寫下的每一條守恆式的線性與否,直接寫進了優化器要面對的地形。一個能讓問題保持凸性的衡算建模方式,可能比一個更精確但非凸的模型更實用——這是建模藝術,也是研究所程序優化課的核心張力。
重點回顧
- 先算自由度,再算答案:$N_{\text{DOF}} = N_{\text{unknowns}} - N_{\text{independent equations}}$。等於 0 才可解;大於 0 須補設計變數;小於 0 代表過定或誤判獨立方程。
- 總平衡不獨立於成分平衡:$C$ 條成分平衡與「$C-1$ 條成分 $+$ 總平衡」二選一,混用會誤判過定。
- 多反應用反應進度:$\dot{n}_{i,\text{out}} = \dot{n}_{i,\text{in}} + \sum_k \nu_{ik}\xi_k$,獨立反應數 $=$ 化學計量矩陣的秩,把反應自由度壓到最少。
- 再循環需撕裂或聯立:循序模組法靠撕裂流迭代收斂;方程導向法用 Newton–Raphson 一次解全廠。惰性累積靠放空,且穩態下「惰性進料率 $=$ 放空率」。
- 質能耦合不可分解:反應速率對溫度敏感時,質量與能量平衡必須聯立,是多重穩態的根源;約束的線性/凸性直接決定優化難度(LP → NLP → MINLP)。
深入探討(研究所視角)
把上面這些線索往前推,會通向程序系統工程(process systems engineering, PSE)最活躍的幾個前沿:
1. 撕裂變數的最佳選擇與收斂加速。 一張流程圖可能有多種剪法,撕裂流選得好壞直接影響迭代次數。如何用圖論(把單元視為節點、物流視為邊)找出「最小撕裂集合」,以及如何用 Broyden 等擬牛頓法在不算完整 Jacobian 的情況下加速收斂,是模擬器演算法設計的核心。這也解釋了為什麼同一個流程,換個收斂選項就可能從「半小時不收斂」變成「三秒解出」。
2. 資料校正與粗大誤差偵測(data reconciliation & gross error detection)。 真實工廠的流量、溫度量測都有雜訊,使得實測數據違反守恆($N_{\text{DOF}}<0$ 的過定情境)。資料校正把守恆律當硬約束,求解一個加權最小平方問題,找出「最接近量測、又嚴格守恆」的真實值估計;同時用統計檢定揪出故障的儀表(gross error)。這把衡算從離線設計工具,變成線上即時監測與故障診斷工具,是智慧工廠的基礎設施。
3. 動態衡算與狀態估計(dynamic balance & state estimation)。 保留累積項後,質能平衡成為一組 ODE/PDE,描述開停車與擾動下的演化。把這組動態模型與量測串接,用 Kalman 濾波或移動視窗估計(moving horizon estimation)即時推算那些「量不到卻想知道」的狀態變數(如反應器內部濃度分布),是先進程序控制(APC)與模型預測控制(MPC)的前置條件。
4. 不確定性下的衡算與彈性分析(flexibility analysis)。 真實進料組成、物性參數都有不確定性。如何設計一個程序,使其在參數落在某個區間內時「自由度仍恰當、約束仍可滿足」,是隨機規劃與穩健優化(robust optimization)的範疇。這讓質能平衡從「對一組確定數字成立」升級為「對一整片參數空間成立」。
把這四個方向串起來看,你會發現入門篇那個樸素的「畫一個框」,到研究所其實長成了一棵枝繁葉茂的樹:自由度分析是它的根(判定可解性),撕裂與聯立求解是它的幹(算出穩態),資料校正與動態估計是它伸向真實工廠的兩條主枝(線上運用),而不確定性下的優化則是它最高處迎風的新芽。守恆律本身一個世紀沒變過,真正不斷演進的,是我們在愈來愈複雜、愈來愈真實的世界裡求解它、信任它、運用它的能力——這正是化學工程作為一門系統科學歷久彌新的理由。