
當審稿人問「你怎麼知道是 A 造成 B」:討論與結論的進階論證
從擋掉競爭解釋、詮釋效果量、劃定推廣邊界,到把結論寫成研究對話的一回合
入門教你「詮釋數據」,進階要問:你的詮釋,真的站得住嗎?
入門篇把分工講清楚了:Results 報導「發生什麼」,Discussion 詮釋「這意味什麼」,Conclusion 收束「貢獻與展望」。你也學會了避險(hedging)、和文獻對話、把限制寫具體。那些是底盤。
但有經驗的審稿人讀討論時,腦中跑的不是「你有沒有詮釋」,而是一連串更尖銳的審問:你提出的這個機制,有沒有別的解釋同樣說得通?你說「顯著」,那效果到底多大、值不值得實務界理會?你把結果推廣到「大學生」,可是你只測了一所學校的通識課,這一步跨得會不會太大?你的結論句句漂亮,但哪一句是真的「你的貢獻」、哪一句其實是文獻早就講過的?
這篇進階文章不再教你「怎麼寫出一段詮釋」,而是教你怎麼讓詮釋禁得起攻擊。我們會談討論段落底層的論證結構、競爭性解釋(rival explanation)的處理、效果量的詮釋政治、推廣邊界的精準劃定,以及如何把整篇結論寫成一個「研究對話的回合」。這些正是初稿與可發表稿之間,最常拉開差距的地方。
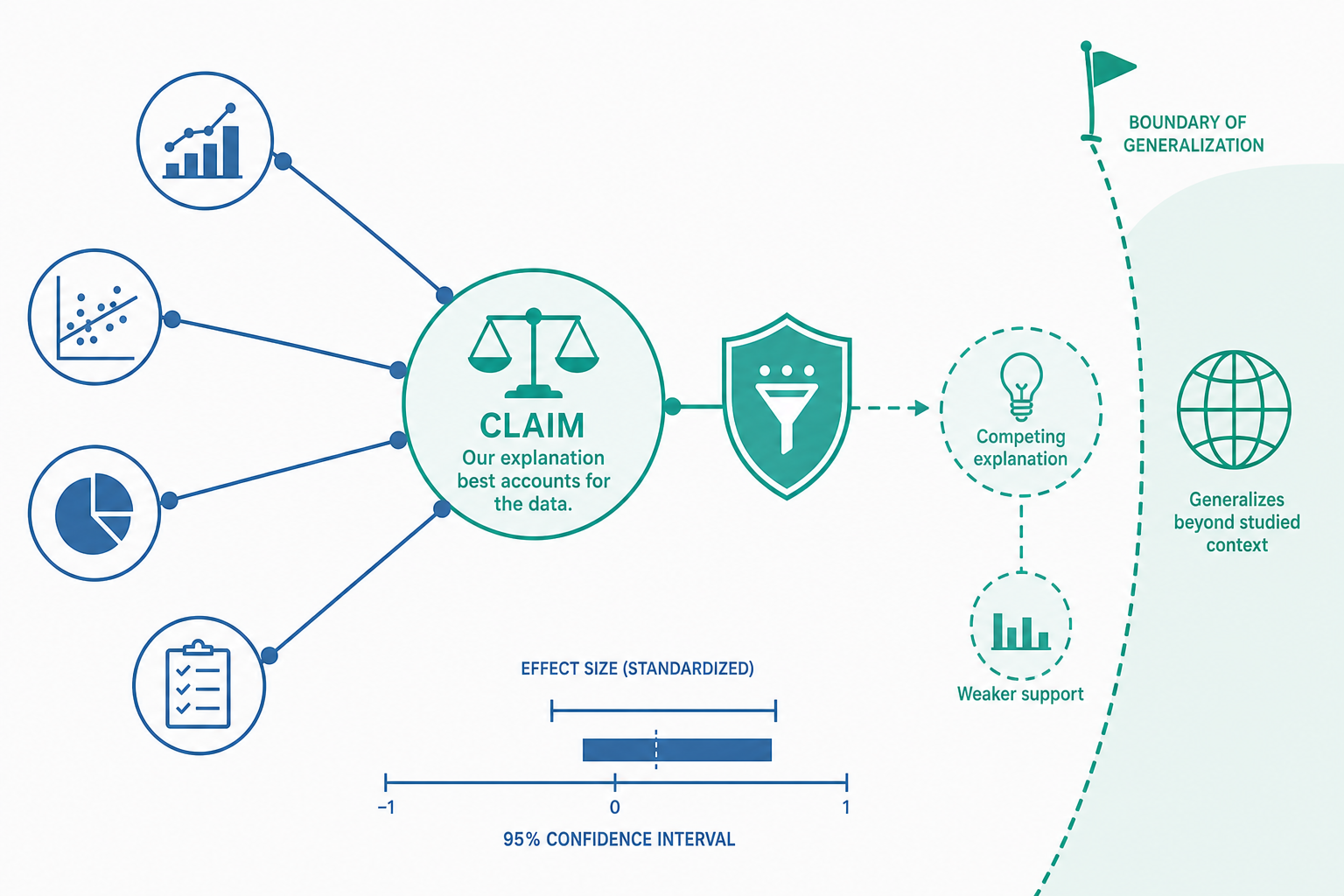
機制不是越多越好,而是要先「擋掉競爭解釋」
入門篇鼓勵你把數字翻成機制(mechanism)。進階的問題是:你提的機制,是「最可能」的那個,還是只是「你最喜歡」的那個?
一個發現往往可以對應好幾種解釋。實驗組成績比較好,可能是因為介入有效;也可能是因為實驗組剛好程度比較高(選擇偏誤)、因為老師對實驗組比較熱情(實驗者期望)、因為實驗組被測了兩次而練習到(測驗效應)。成熟的討論不會只提一個機制就收工,而是主動點名最強的競爭解釋,再說明為什麼你的資料讓它比較不可信。
❌ 不佳:The improvement was caused by our feedback system, which clearly motivates students to learn. (這個進步是由我們的回饋系統造成的,它顯然能激勵學生學習。)
問題不在它錯,而在它沒有對手。作者只把自己偏愛的故事講了一遍,完全沒回應「會不會是別的原因」。"clearly" 更是一個危險字——真正清楚的事,不需要你用 "clearly" 來宣告。
✅ 改良:One might argue that the gain simply reflects a novelty effect rather than the feedback itself. However, two observations weigh against this: the advantage persisted into the eighth week, by which point novelty would likely have faded, and a parallel group exposed to the same novel interface without timely feedback showed no comparable gain. Taken together, these patterns make timely feedback the more parsimonious explanation. (有人可能主張,這個進步只是反映新奇效應,而非回饋本身。然而兩項觀察不支持此說:此優勢一直延續到第八週,屆時新奇感應已消退;且一個接觸相同新介面、但未獲即時回饋的對照組並未顯現相當的進步。綜合來看,即時回饋是較簡約的解釋。)
差別是質的躍升。改良版先把最強的對手(新奇效應)請上台,再用兩條證據把它請下去,最後用「簡約原則」(parsimony)收束。這種「設立並擊倒競爭解釋」的寫法,是討論段落最有說服力的結構之一。實用句型:
- 引入競爭解釋:An alternative explanation is that… / One might argue that… / It could be that the effect is driven by X rather than Y.
- 反駁或削弱:However, several lines of evidence argue against this… / This account, however, cannot easily explain…
- 收束到較佳解釋:A more parsimonious interpretation is that… / On balance, the data are more consistent with…
一個常被忽略的原則:你不需要徹底「消滅」競爭解釋,只要誠實地評估它的可信度。 若資料無法排除某個對手,正確的寫法是承認它仍是開放問題,而不是假裝它不存在。
「顯著」之後:把效果量翻成讀者聽得懂的實務語言
入門篇提醒你避免把 p < .05 講成「證明」。進階的責任更重:統計顯著只回答「效果不太可能是隨機」,它完全沒回答「效果有多大、值不值得在意」。 這兩個問題的混淆,是討論段落最隱蔽的硬傷。
一個 N = 5000 的研究,可能讓一個微不足道的差異(兩組相差 0.5 分)達到 p < .001;而一個 N = 20 的研究,可能讓一個巨大的效果因樣本太小而「不顯著」。所以越來越多頂尖期刊要求:報告效果量(effect size,如 Cohen's d、η²、odds ratio)與信賴區間(confidence interval),並在討論中詮釋它的實務意義。
❌ 不佳:The intervention had a statistically significant effect on engagement (p = .04), demonstrating its effectiveness. (介入對投入度有統計上顯著的效果(p = .04),證明了它的有效性。)
✅ 改良:Although the effect reached significance (p = .04), its magnitude was small (d = 0.18, 95% CI [0.01, 0.35]). In practical terms, this corresponds to roughly a two-point shift on a 100-point engagement scale—detectable, but modest. Whether such a gain justifies the cost of large-scale deployment is a question this study cannot settle on its own. (雖然效果達顯著(p = .04),但其量值很小(d = 0.18,95% 信賴區間 [0.01, 0.35])。換算成實務語言,這大約相當於百分制投入度量表上兩分的移動——可偵測,但幅度有限。這樣的進步是否足以正當化大規模佈署的成本,並非本研究單獨能定奪的問題。)
改良版做了三件事:給出效果量與信賴區間、把抽象的 d 翻成「百分制上兩分」這種人話、誠實點出「值不值得」是另一個層次的問題。注意它沒有因為效果小就唱衰自己,而是精準地把效果「定位」在讀者能判斷的尺度上。這正是研究所階段審稿人最看重的成熟度。
反過來,當效果量很大但因樣本小而不顯著時,也別急著說「沒效果」:
✅ Although the difference did not reach significance (p = .11), the effect size was moderate (d = 0.52), suggesting the study may have been underpowered; a replication with a larger sample is warranted before drawing firm conclusions. (雖然差異未達顯著(p = .11),但效果量為中等(d = 0.52),暗示本研究可能檢定力不足;在下定論前,有必要以更大樣本進行重複驗證。)
推廣的邊界要「主動劃線」,而不是讓審稿人替你劃
入門篇談過外部效度(external validity)。進階的關鍵動作是:在結論主動劃出「我的主張到此為止」的那條線,而不是把話講滿、等審稿人來打臉。 過度概化(overgeneralization)是退稿信裡最常出現的詞之一。
差別往往就在一兩個限定詞(qualifier)。
❌ 不佳:These findings show that AI tutoring improves learning. (這些發現顯示 AI 輔導能提升學習。)
這句話的主詞太大。「AI tutoring」泛指所有 AI 輔導,「learning」泛指所有學習,但你測的只是某一種回饋設計、某一群學生、某一種學習成果。
✅ 改良:Within the context of an undergraduate general-education course, an AI tutor that delivered immediate, individualized feedback was associated with improved performance on a factual-recall assessment. Whether the same design benefits higher-order skills, or transfers to disciplines with different epistemic norms, remains an open question. (在大學通識課程的脈絡下,一個提供即時、個人化回饋的 AI 輔導與事實記憶評量上的表現提升有關。同樣的設計是否有益於高階能力,或能否遷移到具有不同認識論規範的學門,仍是開放的問題。)
改良版把三個邊界都標清楚了:脈絡(通識課)、成果類型(事實記憶,而非高階能力)、可遷移性(其他學門待驗)。讀者一看就知道你清楚自己的疆界。這種「自我設限」非但不削弱論文,反而讓你的核心主張更可信——因為你沒有亂開支票。
一個進階技巧是區分統計推論的母體(statistical population)與理論推論的範圍(theoretical scope)。你的樣本可能只代表某一所大學,但你的「理論主張」(例如「降低提問的社會成本能促進參與」)原則上可以更廣——只要你誠實標明後者是「待檢驗的延伸」而非「已證實的結論」。能把這兩層分開談,是討論寫作的高階手藝。
別讓「未來研究」變成卸責的萬用句
入門篇已經批過 "more research is needed" 的空洞。進階要更進一步:「未來方向」其實是你展示研究品味(research taste)的舞台——它揭露你是否真的看懂這個領域接下來的關鍵問題。
弱的未來方向是「把這次的限制反過來講一遍」(樣本小→未來找大樣本;時間短→未來做長期)。這只是補洞。強的未來方向會指向一個這次發現所「打開」的新問題——不是修補,而是延伸。
❌ 不佳:Future research should use a larger sample and a longer duration to confirm these results. (未來研究應採用更大樣本與更長時程來確認這些結果。)
✅ 改良:A more generative direction concerns the boundary of the effect. If, as we argue, the benefit stems from lowering the social cost of asking, then it should be strongest precisely where that cost is highest—among students with high social anxiety or in cultures with strong face-saving norms. Testing this moderation hypothesis would not merely replicate our finding but probe the mechanism we have proposed. (一個更具生產性的方向關乎效果的邊界。若如我們所主張,益處源自降低提問的社會成本,那麼在這個成本最高之處——高社交焦慮的學生,或重視面子規範的文化中——效果應最強。檢驗這個調節假設不僅是重複我們的發現,更是直探我們所提出的機制。)
改良版把未來方向從「補洞」升級成「驗證機制的調節假設(moderation hypothesis)」。它等於告訴審稿人:我不只知道我做了什麼,我還知道這個發現的下一個關鍵問題在哪。這就是研究品味。
看一個例子:把一段「漂亮但空心」的結論改寫成「有貢獻定位」的結論
許多結論讀起來很順,卻講不出「到底新在哪」。問題常在於:作者把「文獻早就知道的事」和「自己這次才確立的事」混在一起講,讀者分不出哪句是貢獻。
假設研究發現「在程式設計課中,讓學生互相講解程式碼(peer code explanation)的組別,期末專案品質較高」。
漂亮但空心版:
In conclusion, peer learning is beneficial for programming education. Our study confirms that collaboration helps students learn. These findings have important implications for teaching. Future research is encouraged to explore this further.
問題清單:(1) "peer learning is beneficial" 是文獻共識,不是你的貢獻;(2) "collaboration helps" 同樣是老生常談;(3) "important implications" 是空話,沒說是什麼意涵;(4) 整段沒有一句話只屬於這篇論文。
有貢獻定位版:
While collaborative learning is well established as beneficial, this study isolates a specific and previously underexamined mechanism: the act of explaining code, rather than merely co-writing it, appears to drive the gain in project quality. Groups that co-wrote without explaining showed no comparable advantage, pointing to articulation—not collaboration per se—as the active ingredient. For instructors, this reframes the design question from "should students work together?" to "what cognitive work must the collaboration require?" The next step is to test whether this articulation effect generalizes from code to other ill-structured domains, such as experimental design or legal reasoning.
升級版做對了四件事:(1) 先讓出文獻共識(collaborative learning 有益是已知的),把舞台清出來;(2) 精準指認自己的新貢獻(不是合作,而是「講解」這個特定動作);(3) 用一個對照組證據(只共寫不講解者無優勢)撐住這個主張;(4) 把實務意涵說成一句可操作的設計問題重構,並指向一個有理論張力的延伸。讀完,讀者清楚知道這篇論文「在已知地圖上新畫了哪一塊」。
結論的視角與口吻:從「我們的研究」回到「這個世界」
一個細微但會洩漏功力的層次,是結論的視角與口吻。討論大量在談「我們的研究發現了什麼」(the study found),結論則應該逐漸把鏡頭從你的論文拉回到現象本身與研究社群。
❌ 過度自我中心:In this paper, we did many experiments and we found significant results, and we think our method is very useful. (在本文中,我們做了很多實驗、發現了顯著結果,而且我們認為我們的方法很有用。)
這段話的問題是視角始終卡在「我們」,而且 "very useful" 是評價不是論證。
✅ 改良:Taken together, these results refine our understanding of when feedback aids learning: not whenever it is provided, but when it is timely and psychologically safe. This shifts the practical conversation away from tool adoption toward the deliberate design of the conditions under which feedback is received. (綜合來看,這些結果精緻化了我們對「回饋何時有助於學習」的理解:不是只要提供就好,而是要及時且具心理安全感。這把實務上的討論從「採用工具」轉向「審慎設計回饋被接收的條件」。)
改良版的主詞從「我們」變成了 "these results" 與 "our understanding",口吻從自誇變成對領域認知的推進。注意它用現在式(refine、shifts)來陳述「現在這個領域因此而改變的理解」——這正是入門篇講的時態原則,在結論層次的高階應用。
重點回顧
- 機制要先擋掉競爭解釋:別只把偏愛的故事講一遍。主動請出最強的對手(新奇效應、選擇偏誤、實驗者期望),用資料削弱它,再以簡約原則收束。擋不掉的就誠實承認仍是開放問題。
- 顯著之後一定要談效果量:p 值只說「不太可能是隨機」,不說「多大」。報告 effect size 與信賴區間,並把抽象的 d 翻成讀者能判斷的實務尺度。
- 推廣邊界要主動劃線:用限定詞框住脈絡、成果類型、可遷移性。區分「統計母體」與「理論範圍」,後者可較廣但須標明是待驗延伸。
- 未來方向是研究品味的舞台:別把限制反過來講(補洞),要指向發現所打開的新問題——尤其是能驗證你所提機制的調節假設。
- 結論要定位貢獻、拉回世界:先讓出文獻共識,再精準指認你的新貢獻;口吻從「我們做了什麼」轉向「領域因此改變了什麼理解」。
深入探討(研究所視角)
到了研究所與投稿頂尖期刊的階段,討論與結論的寫作會從「技巧正確」上升到「論證政治」與「文體自覺」的層次。
一、討論是一場「主張與反主張」的攻防,可用論證結構自我稽核。 把每一段詮釋拆成 claim(主張)、grounds(你的資料)、warrant(連結兩者的理據)、rebuttal(你預先回應的反駁)。入門篇談過前三者;進階的關鍵是 rebuttal——主動寫進「有人可能反對,但是……」,等於在審稿人開口前先回應他。一段同時具備 warrant 與 rebuttal 的詮釋,幾乎不會被批評為「過度詮釋」,因為你已經展示自己看見了論證的脆弱點。
二、效果量與不確定性的「估計思維」(estimation thinking)正在取代二元的顯著性思維。 Cumming 提倡的「新統計」(the new statistics)主張:少問「有沒有效果(是/否)」,多問「效果有多大、估得多準」。在討論寫作上,這意味著你應圍繞信賴區間的「寬窄」與「位置」鋪陳論述——一個橫跨零的寬區間,本身就是「證據不足、需更大樣本」的精確語言,遠勝於含糊的 "the result was marginal"。能用區間而非單點 p 值來說故事,是區辨資深與新手的指標之一。
三、建構效度(construct validity)的威脅,往往藏在討論的「概念滑移」裡。 一個常見而隱蔽的問題:你測的是 A(如「提問次數」),討論卻悄悄推論成 B(如「學習投入」或「深度理解」)。次數多不等於投入深。成熟的討論會明白地守住「我測到的構念」與「我想談的構念」之間的距離,並把這個落差本身寫成限制。Shadish、Cook 與 Campbell 的效度框架在此特別有用:把每個推論步驟對應到它所依賴(或威脅)的效度類型——統計結論效度、內部效度、建構效度、外部效度。
四、不同學門的「討論文體規範」(disciplinary discourse conventions)差異極大,照搬會出錯。 實驗科學的討論重機制與效果量;質性研究(qualitative research)不談「可推廣性」(generalizability)而談「可轉移性」(transferability),透過厚描述(thick description)讓讀者自行判斷適用情境,其結論常以「詮釋洞見」而非「因果結論」收束;設計研究(design-based research)的結論則以「設計原則」(design principles)的形式輸出,供他人在新情境再脈絡化;計算與工程領域的結論則可能更強調「方法的可重現性與基準表現」。投稿前讀三篇目標期刊的近期論文,逆向拆解它們的討論如何鋪陳,比死背任何句型都有效。
五、把整篇結論寫成「研究對話的一個回合」,並讓貢獻可被後人「接住」。 學術知識是累積的接力。最高明的結論會明確標示三件事:我接住了文獻中誰拋來的問題、我這一棒把理解往前推了多少、我把球往哪個方向傳給下一位。當你的結論能讓讀者清楚看見這條對話線,你寫的就不只是一篇論文的句點,而是一個研究社群持續探問的節點——而這,正是「貢獻」一詞在學術社群裡真正的意義。