
切得越細,就賺得越多嗎?市場區隔的甜蜜點在哪裡
從異質性與規模經濟的取捨,到 POD/POP 攻防、品類框架與資料驅動區隔,看 STP 如何在個人化時代深化與受到挑戰。
切得越細,就賺得越多嗎?市場區隔的甜蜜點在哪裡
入門篇用「一瓶水賣 8 元也賣 80 元」帶你認識了 STP 三道工序:切分市場(Segmentation)、選定目標(Targeting)、佔住心智(Positioning)。那是地圖、戰場與旗幟的故事。但讀完之後,一個更尖銳的問題才剛開始:市場到底要切多細?
直覺上,切得越細、鎖得越準,每一群顧客的需求就被滿足得越好,企業好像就該賺得越多。但現實裡,很多公司死在「切太細」——為十個小到不行的區隔各做一套產品、各打一支廣告,研發與行銷成本爆炸,每一塊的營收卻撐不起對應的開銷。也有公司死在「切太粗」——想用一套方案討好所有人,結果誰都不夠滿意,被更聚焦的對手各個擊破。
這篇進階文章不再重述「什麼是區隔、有哪四個變數」。我們要往下挖一層,談區隔背後的經濟邏輯、定位的攻防機制、以及資料時代裡「區隔」這個概念本身正在發生的質變。換句話說,入門篇教你「怎麼切」,進階篇要回答的是「切到什麼程度才划算、切完之後在顧客腦中怎麼打贏這場仗、以及當演算法可以一人一個區隔時,傳統 STP 還剩下什麼」。
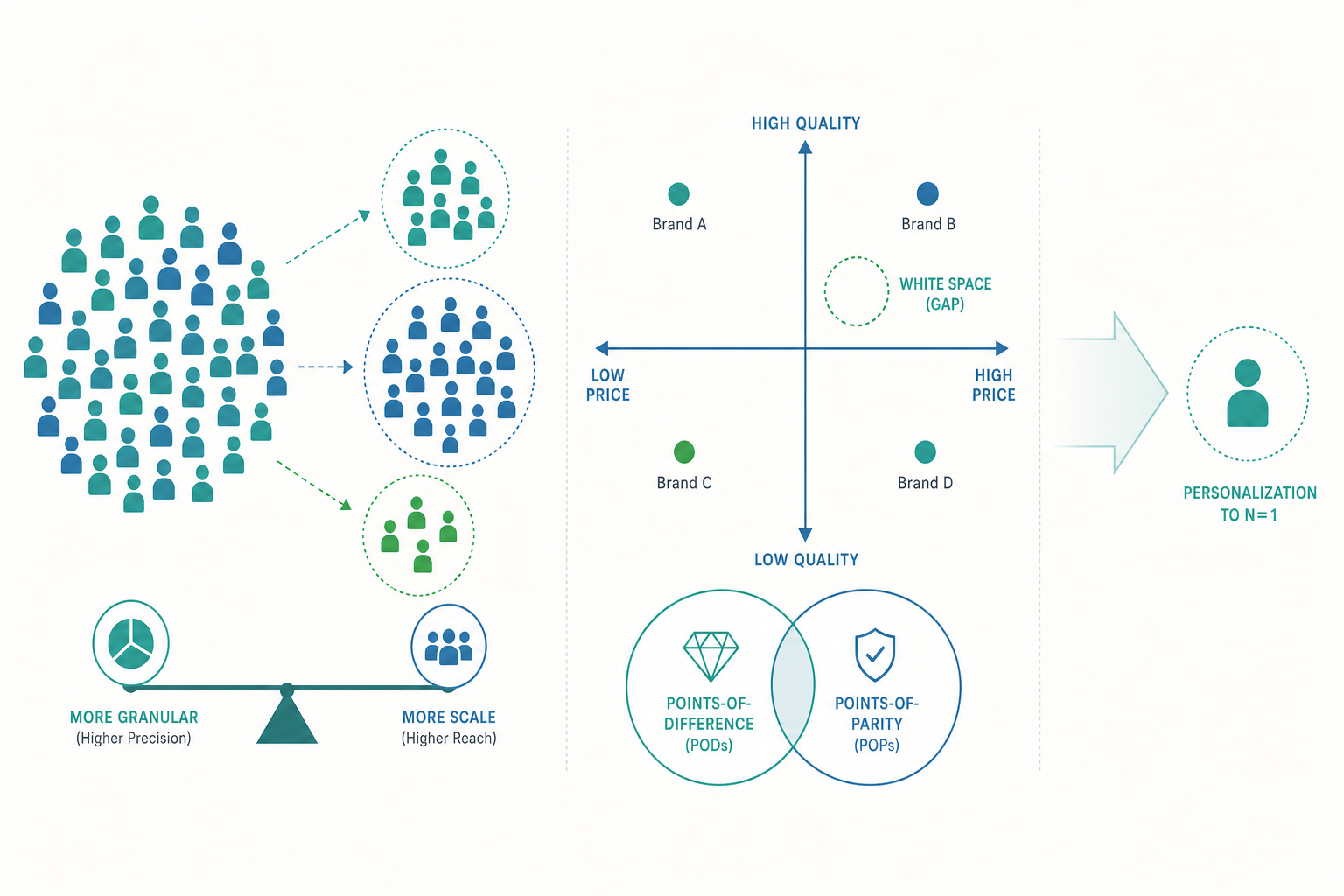
區隔的本質,是在「異質性」與「規模經濟」之間取捨
要理解「切多細才划算」,得先看清楚市場區隔在經濟上到底在權衡什麼。一邊是需求的異質性(heterogeneity):顧客的偏好越分歧,用單一方案服務全體所損失的「契合度」就越大,切分市場帶來的收益也越高。另一邊是供給的規模經濟(economies of scale):產品開發、生產、行銷、通路都有固定成本,服務的人越多,分攤到每個人身上的成本越低;一旦把市場切碎,每一塊都得各自負擔一份固定成本,總成本就上升。
所以市場區隔的最適深度,本質上是一道最佳化問題:切分帶來的「需求契合收益」要能蓋過切分造成的「規模經濟損失」。當顧客偏好高度分歧、而客製化的邊際成本又低時(這正是數位產品的特性),市場就值得切得很細;反之,當偏好其實沒那麼不同、而固定成本又很高時(例如重工業),粗略的區隔反而更有效率。
這個視角解釋了一個常被誤解的現象:並不是越精準的行銷就越好。 區隔的價值不在「細」,而在「異質性是否真實存在、且大到值得用不同方案去回應」。如果你切出來的兩群人,需求其實大同小異、對行銷的反應也一樣,那再漂亮的人口統計切法都只是自我安慰——這正呼應入門篇提到的「可區別性(differentiable)」條件,只是這裡把它放回了成本效益的天平上來看。
區隔是一種「成本」,不只是一種「洞察」
初學者容易把市場區隔當成純粹的「看清楚顧客」的洞察活動,免費又只有好處。進階的視角要記得:每多服務一個區隔,都要付出真實的代價。 多一條產品線就多一份庫存與複雜度,多一個目標族群就多一套溝通與通路。這就是為什麼資源有限的新創幾乎都被建議走集中化(concentrated)策略——不是因為利基比較好,而是因為他們付不起服務多區隔的固定成本。當企業規模壯大、固定成本能被攤平了,才有本錢從集中化走向差異化。STP 不是一次定生死的決定,而是隨企業資源與市場演化動態調整的過程。
定位的攻防:相同點與相異點
入門篇談定位,重點放在「找出差異化價值、用一句話講清楚」。進階篇要拆解定位在競爭裡實際的攻防結構。科特勒與凱勒(Kotler & Keller)提出一組關鍵概念:相異點(Points of Difference, POD)與相同點(Points of Parity, POP)。
- 相異點(POD)是顧客強烈地、正面地與你的品牌連結,且認為競爭者做不到的屬性。這是你的「進攻武器」,是顧客選你不選別人的理由。
- 相同點(POP)則是「你必須具備、否則出局」的基本條件。它不會讓顧客愛上你,但缺了它,顧客連把你列入考慮都不會。
這裡藏著一個初學者常忽略的洞見:只有相異點是不夠的,相同點往往才是定位的隱形戰場。 想像一家主打「健康無糖」的新飲料(這是它的 POD),如果它「不好喝」,那再健康也賣不動——「好喝」是這個品類的相同點,是入場券。許多看似有差異化卻失敗的產品,問題不在於沒特色,而在於為了凸顯特色而犧牲了某個關鍵相同點,結果連基本盤都守不住。
POP 還有一種微妙的攻防用途:「競爭性相同點(competitive POP)」是用來抵銷對手相異點的。 當對手用某個賣點攻擊你時,你不必在那個維度上贏過他,只要做到「夠好、沒有明顯落後」,就能把戰場拉回到你自己的相異點上。例如後進的智慧型手機品牌,未必要在相機上超越領導者,只要相機「夠好到讓人不糾結」,就能把消費者的注意力導向自己真正的賣點(如續航或價格)。定位不只是「我比你強在哪」,更是「我如何讓你的強處不再是顧客的決策關鍵」。
定位的隱形地基:品類框架(category framing)
定位陳述的標準句式裡有一格叫「產品類別」,入門篇一筆帶過,但它其實是定位中最有槓桿、也最常被低估的一步。你把產品歸進哪個品類,等於替顧客設定了「跟誰比、用什麼標準評」。
舉個經典思路:一瓶能量飲料,若定位在「碳酸飲料」品類,它要跟可樂比甜度與價格,多半落於下風;若把自己框成「機能性提神飲品」品類,它的比較對象變成咖啡與提神錠,貴一點反而合理。同一個產品,換一個品類框架,整張定位圖的座標軸都換了,競爭者也換了一批。 這就是為什麼成熟的行銷人會說:定位的第一場仗,往往是「定義你在哪個品類競爭」,而不是「在既定品類裡排第幾」。找到一個對自己有利、又有顧客需求的品類框架,常常比在紅海裡硬擠更高明。
從靜態區隔到動態、資料驅動的區隔
入門篇介紹的四大變數(地理、人口、心理、行為)有個共同特徵:它們多半是事前、靜態地把人分類。進階的行銷實務,越來越倚賴事後、由資料浮現的區隔方法。這裡介紹兩種思路,幫你看懂「區隔」這個動作如何被數據改寫。
第一種是以行為價值為基礎的區隔,最具代表性的是零售與電商廣泛使用的 RFM 模型:依顧客最近一次購買(Recency)、購買頻率(Frequency)、消費金額(Monetary)三個行為指標,把顧客分成不同價值層級。RFM 的精神跟人口統計切法完全相反——它不問「你是誰」,只看「你做了什麼」。一個沉睡已久的高消費老客、與一個頻繁回購的小額新客,需要的行銷動作截然不同,RFM 讓這種差異變得可操作。這也呼應入門篇提到的「行為變數比人口變數精準」,只是進階篇把它落實成了一套可計算、可自動化的分群系統。
第二種是以統計方法自動發掘區隔,例如集群分析(cluster analysis)與潛在類別分析(latent class analysis)。傳統做法是「先決定用年齡切,再看每群多大」;資料驅動做法則反過來——把大量顧客特徵丟進演算法,讓「組內相似、組間相異」的結構自己浮現,再回頭去解讀每一群的特徵與命名。這種方法常常切出人類事前想不到的區隔組合(例如「高所得但極度價格敏感、只在特價時囤貨」這種跨變數的群體)。
但資料驅動區隔不是萬靈丹,它帶來三個必須警覺的張力:
- 可解釋性:演算法切出來的群,有時很難用人話說清楚「這群人到底是誰」,難以指導實際的產品與溝通設計。切得出來不等於用得上。
- 穩定性:行為會變,今天的分群明天可能就漂移了,需要持續更新,而非一勞永逸。
- 「可行動」的回歸:再精緻的分群,最終仍要通過入門篇那五個老問題的檢驗——可衡量、足量、可接觸、可區別、可行動。資料讓「切」變容易了,但「切得有沒有意義」的判準沒有改變。
當「區隔」趨近於 N=1:個人化的極限與反撲
把資料驅動推到極致,會抵達一個理論上的端點:每個人都是一個區隔(segment of one)。推薦系統、動態定價、程式化廣告(programmatic advertising)讓「為每個人量身打造」在技術上不再是幻想。這似乎是 STP 的終極勝利——精準到了個體層級。
但這裡有兩個進階思辨,值得放進腦中。
其一,個人化與定位之間存在張力。定位的本質,是在「一群人」心中建立「一致而清晰」的品牌形象——大家聽到這個品牌,腦中浮現的是同一個位置。可是當行銷訊息被演算法切到一人一個版本、千人千面時,品牌還能維持那個「共享的、一致的」心智位置嗎?過度個人化有可能稀釋掉品牌的整體定位,讓品牌變成一面「對每個人說不同話」的鏡子,反而失去了強勢品牌賴以建立的一致性。精準鎖定的是「轉換」,但定位要經營的是「認同」,兩者並不總是同向。
其二,個體化區隔放大了倫理與信任成本。一人一價的動態定價,效率上很美,卻可能被顧客視為「看人喊價」的不公平;基於敏感特徵的精準鎖定,可能滑向歧視或操弄。這正是 Uedu 在資料治理上一貫強調的「隱私為本(Privacy by Design)」所要面對的議題——當區隔的解析度逼近個人,行銷的權力與責任也同步放大。能不能切到一個人,與該不該切到一個人,是兩個不同的問題。 成熟的行銷策略,會把「顧客的信任」也算進區隔的成本效益裡。
動手試試
下次你打開任何一個購物或串流 App,試著做一個小觀察練習,把這篇文章的概念套上去:
- 找它的相異點與相同點:這個品牌讓你「非它不可」的理由是什麼(POD)?又有哪些是「沒有就出局、但有了也不稀奇」的基本功(POP)?
- 猜它把你分進了哪個區隔:首頁推薦給你的東西,反映了它對你的哪些行為判斷(最近看了什麼、買的頻率、價格帶)?這比較像 RFM 式的行為分群,還是人口統計分群?
- 感受個人化的兩面:這些個人化讓你覺得「真貼心」,還是「有點被看穿、被操控」?這個主觀感受,就是上面談的「信任成本」在你身上的真實刻度。
做完這個練習,你會發現自己已經不是被動的消費者,而是能反向拆解品牌 STP 策略的分析者——這正是進階學習的價值。
重點回顧
- 市場區隔的最適深度是一道最佳化問題:在「需求異質性帶來的契合收益」與「規模經濟被切碎的損失」之間取捨。切得越細不等於越賺,重點是異質性是否真實且大到值得回應。
- 每多服務一個區隔都是真實成本:這是新創走集中化、大企業才走差異化的根本原因;STP 是隨資源與市場動態調整的決策,不是一次定生死。
- 定位是 POD 與 POP 的攻防:相異點是進攻武器,相同點是入場券;競爭性相同點能抵銷對手賣點,把戰場拉回自己的強項。
- 品類框架是定位最有槓桿的一步:你把產品歸進哪個品類,就決定了顧客拿你跟誰比、用什麼標準評。
- 資料驅動區隔(RFM、集群/潛在類別分析)讓區隔從靜態走向動態浮現,但仍須回到可衡量、可接觸、可行動的老判準;個人化逼近 N=1 時,會與「品牌一致性」和「顧客信任」產生張力。
深入探討(研究所視角)
對於想把市場區隔與定位推進到研究層級的學習者,以下幾個前沿議題值得追蹤。
第一,區隔的內生性與「需求被製造」問題。 傳統 STP 假設市場上存在「客觀既有」的區隔,行銷人的任務是發現它。但在推薦系統與精準廣告主導的環境裡,顧客的偏好與行為本身可能是被平台塑造出來的——你觀察到的「區隔」,有多少是真實的需求結構,又有多少是演算法回饋迴路(feedback loop)自我強化的人造產物?這種偏好的內生性(endogeneity),對「以顧客需求為核心」的行銷哲學構成深刻挑戰,也讓「我們到底在區隔什麼」成為一個需要嚴肅對待的方法論問題。
第二,定位效果的因果識別。 「採用某定位的品牌賣得好」往往只是相關,而非因果——成功的品牌本來就資源多、通路廣。要嚴謹驗證「某個定位策略真的造成了銷售或偏好的改變」,需要借助隨機對照實驗(A/B 測試、地理實驗)或準實驗設計,分離出定位本身的真實效果,並排除選擇偏誤。如何在觀察性的市場資料中做出可信的因果推論,是行銷科學(marketing science)的核心難題之一。
第三,動態定位與品牌資產的權衡。 定位不是一次定生死,市場與競爭會變,品牌可能需要重定位(repositioning)。但重定位極其困難,因為要改寫的是已根深柢固的顧客心智;學術上會探討重定位的時機、品牌延伸對核心定位的稀釋效應,以及如何在「保持一致性以累積品牌資產(brand equity)」與「適應變化以避免被淘汰」之間取得平衡。把這個權衡形式化、可量測化,是品牌研究的重要方向。
第四,個人化、公平與福利的交叉地帶。 當區隔解析度逼近個體、動態定價與精準鎖定成為常態,行銷研究正與經濟學、資訊倫理、公共政策交會:一人一價是提升了配置效率,還是加劇了價格歧視與不公平?精準鎖定的「成功」,是滿足了真實需求,還是放大了操弄與成癮?這些問題沒有單一答案,但它們正是當前最具張力、也最有貢獻空間的研究前沿——而能同時駕馭行為科學、資料科學與研究倫理的學習者,將在這個交叉地帶最有發揮。
延伸閱讀方向:Kotler & Keller《Marketing Management》中關於 POD/POP 與品牌定位的章節、Wedel & Kamakura《Market Segmentation: Conceptual and Methodological Foundations》(區隔方法論的經典專著)、以及近年關於演算法定價、個人化倫理與消費者文化理論(CCT)的期刊文獻。