
如果你的忠誠方案,其實只是在「付錢給本來就會留下來的人」?
從增量性、機率式 CLV 建模與因果推論的視角,重新審視顧客關係管理真正創造的價值。
如果你的忠誠方案,其實只是在「付錢給本來就會留下來的人」?
你在入門篇學過:留存比拉新划算、顧客終身價值(Customer Lifetime Value, CLV)會被留存率放大、忠誠方案能墊高轉換成本。這套敘事乾淨而誘人。但如果有一群行銷科學家拿出橫跨多個品類、上萬筆會員資料告訴你——大多數忠誠方案的「淨」投資報酬率接近於零,因為它們的折扣大部分發給了那些不給折扣也會回購的顧客——你會怎麼修正你的判斷?
這不是要否定 CRM,而是要把它從「直覺上很對」的故事,升級成「可被量測、可被質疑、可被優化」的科學。進階的顧客關係管理,正是從這種「框架與證據的張力」開始:當入門課教你「經營關係、深化忠誠」,嚴謹的資料卻一再追問——這段關係的價值,有多少是你真正創造的,又有多少只是你恰好碰上了本來就高價值的人?
這篇文章假設你已經懂了 CLV 的基本概念、RFM 分群與留存的複利效應。我們要往前一步,看 CRM 如何被建模、被歸因、被當成資源配置問題、以及被它自己的副作用反咬。
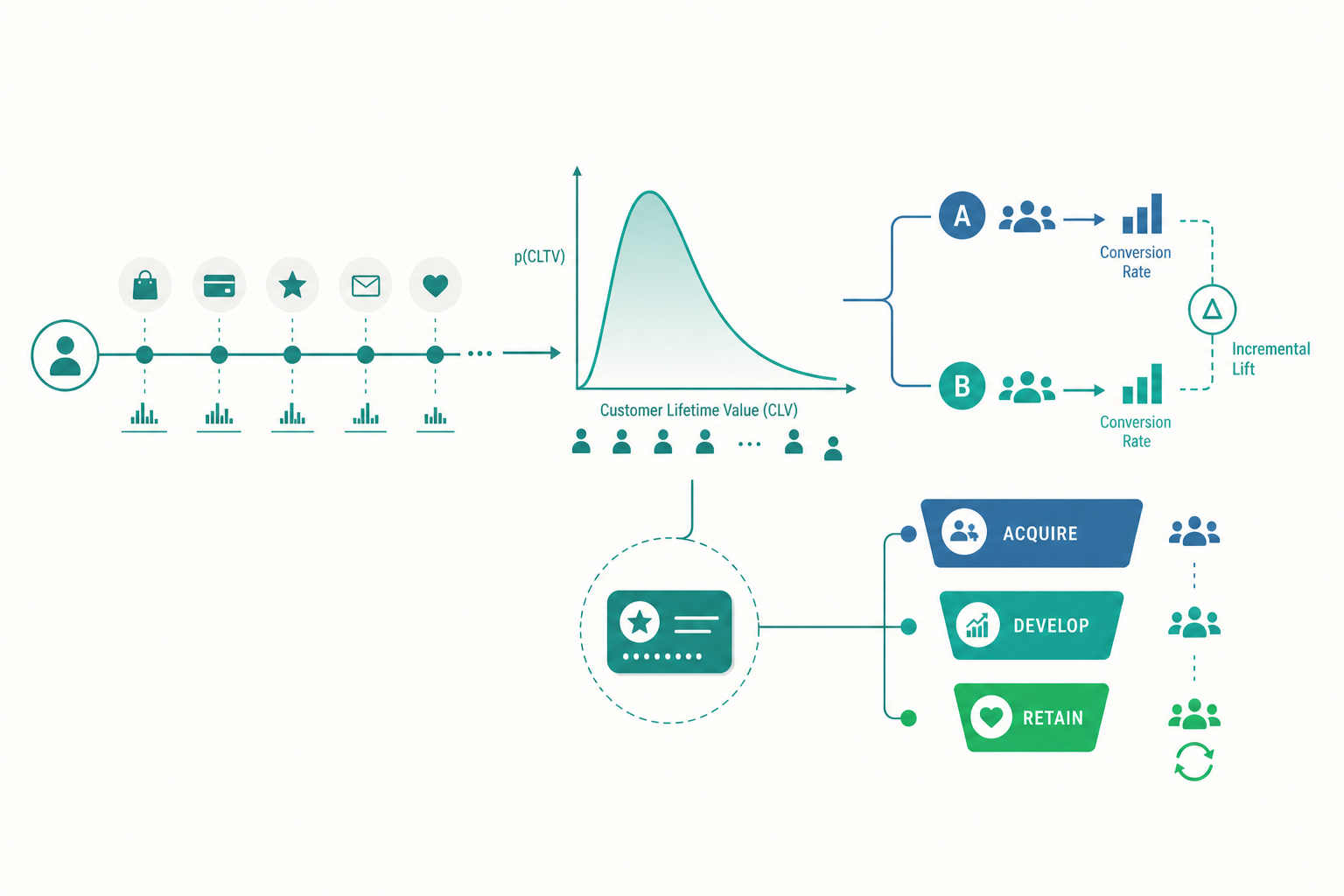
CLV 不只一個數字:從「平均」到「機率分布」
入門篇用一條乘法式估出 CLV:每次貢獻利潤 × 年購買次數 × 往來年數,再扣取得成本。這對教學很好用,但它藏了一個危險的假設——它假設「平均顧客」存在。
現實是,顧客的行為高度異質(heterogeneous)。在同一個 RFM「核心顧客」格子裡,有人會再買三十次,有人下個月就無聲流失。把他們用同一個平均往來年數一筆帶過,等於把一群形狀完全不同的分布壓成一個點。進階建模的第一個轉向,就是從點估計(一個數字)走向機率估計(一個分布)。
在「非契約型」情境——顧客可以隨時停止購買、卻不會明確告訴你他走了(多數零售、電商、咖啡店都是這樣)——這個問題格外尖銳。你怎麼知道一位三個月沒來的顧客是「暫時忙」還是「已經流失」?學界發展出一套機率模型來回答,最著名的是 Pareto/NBD 與更易計算的 BG/NBD(Beta-Geometric/NBD) 模型,再搭配 Gamma-Gamma 模型估計每筆交易的金額。它們的精神可以這樣理解:
- 把每位顧客拆成兩個隱藏特質:他的「購買速率」(活著時多久買一次)與他的「存活狀態」(還活著的機率)。
- 這兩個特質在母體中各自服從某個分布,而不是所有人共用一個值。
- 用每位顧客過去的交易紀錄(買過幾次、最近一次多久前、第一次到最近一次跨多長)去反推他個人的這兩個特質。
結果是,你不再說「這位顧客 CLV 是兩萬元」,而是說「他未來一年還會購買的期望次數是 4.2 次、且他此刻仍活著的機率是 0.73」。這個轉變不只是技術細節——它讓你能對「沉默」做出有根據的判斷,而不是憑感覺發喚回券。
折現:今天的一塊錢與三年後的一塊錢
入門篇的 CLV 把未來幾年的利潤直接相加,這在概念上沒問題,但嚴謹計算必須加一道工序:折現(discounting)。
道理很單純——今天到手的一塊錢,可以拿去投資、可以避開未來的不確定,因此比三年後才到手的一塊錢更值錢。把未來現金流折回現值,公式的骨架長這樣:
CLV = Σ(第 t 期的預期淨利潤 × 留存到第 t 期的機率)÷(1 + d)ᵗ
其中 d 是折現率,t 是期數。三個輸入都會大幅左右結果:
- 折現率 d 的選擇:用公司的資金成本?用無風險利率加風險溢酬?d 從 8% 改到 15%,遠期顧客的價值會被大幅壓低,可能直接改變「值不值得砸錢留住長尾顧客」的結論。
- 預測期間的長短:要算未來三年、五年,還是「無限期」?期間拉愈長,CLV 數字愈漂亮,但遠期預測的不確定性也愈高。實務上常設一個合理上限(如 5 年)以免高估。
- 留存機率本身會隨時間變化:多數情境下,撐過頭幾期的老顧客,往後的留存率反而更高(存活者愈來愈穩定)。用單一固定留存率會系統性地低估忠實顧客。
這裡的訓練重點不是背公式,而是養成一種懷疑的習慣:任何一個漂亮的 CLV 數字背後,都站著一排假設。 看到別人報告 CLV 時,你該問的第一個問題是「你的折現率、預測期間、留存假設各是什麼?」
把 CRM 看成資源配置:取得、發展、留存的三角
入門篇告訴你「留存比拉新划算」。進階觀點要拆掉這個過於簡化的口號——正確的問題不是「拉新 vs. 留存哪個好」,而是「在取得(Acquisition)、發展(Development/向上與交叉銷售)、留存(Retention)三條戰線上,下一塊錢該投到哪裡邊際報酬最高」。
這是一個資源配置問題,而非二選一的信仰問題。三條戰線各有其經濟邏輯:
- 取得:把陌生人變成第一次顧客。成本通常最高、報酬最不確定,但若市場尚未飽和、或你的 CLV/CAC 比值健康,停止取得等於停止成長。
- 發展:讓既有顧客買更多、買更貴、買更廣(向上銷售 Up-sell、交叉銷售 Cross-sell)。這條線常被低估,但對已建立信任的顧客追加銷售,成本遠低於從零取得。
- 留存:防止既有顧客流失。槓桿來自複利,但有一個關鍵陷阱——並非所有流失都值得阻止。挽留一個本來就低於損益平衡的顧客,可能是在燒錢。
把三者放在一起看,會浮現一個入門篇不會講的反直覺結論:有時候「主動放手」某些顧客,反而提升整體顧客資產。 那些服務成本高、抱怨多、又拉不高價值的顧客,硬留下來只會稀釋資源。CRM 的成熟,是從「留住每一個人」走向「把對的資源放在對的關係上」。
把所有顧客的 CLV 加總,就得到一個公司層級的指標——顧客資產(Customer Equity)。它把 CRM 從零散的戰術,連接到企業估值的高度:一家公司值多少,某種程度上等於它現有與未來顧客關係的折現價值總和。當你用顧客資產的視角看,行銷預算就不再是「費用」,而是對顧客資產的「投資」。
忠誠方案的真相:增量,而不是總量
現在回到開頭那個尖銳的問題。為什麼說很多忠誠方案的淨報酬接近零?
關鍵概念叫 增量性(incrementality)。假設你發了一張「回購九折券」,下個月有 1,000 位收券的人回購了。行銷報告會興高采烈地把這 1,000 筆都記在忠誠方案頭上。但真正該問的是:這 1,000 人裡,有多少是「因為這張券才回購」,又有多少是「反正都會回購、只是順手用了券」?
後者就是純粹的成本流失——你對本來就會付全價的人打了折。要分離出真正的增量效果,相關性是不夠的,你需要因果推論:
- A/B 隨機對照實驗:把符合資格的顧客隨機分成「發券組」與「不發券對照組」,比較兩組的回購率差異。這個差異——而非發券組的絕對回購率——才是忠誠方案的真實貢獻。
- 選擇偏誤(Selection Bias)的陷阱:高價值顧客本來就更可能加入忠誠方案、也更可能回購。如果你只比較「會員 vs. 非會員」,會把「方案造成的效果」和「本來就忠誠的人自我選擇加入」混為一談,嚴重高估方案成效。
- 準實驗方法:當無法隨機分組時,可用傾向分數配對(Propensity Score Matching)找出特質相近的對照組,或用差異中之差異(Difference-in-Differences)控制掉共同趨勢。
這個視角徹底改變了 CRM 的優化方式。最前沿的做法是 增量模型(Uplift Modeling,又稱 Net Lift):它不預測「誰會回購」,而是預測「誰會因為我的介入而改變行為」。顧客可以分成四類——「給了券才會買的(可說服者)」「不給券也會買的(必然者)」「給不給都不會買的(無望者)」、甚至「給了券反而被打擾而流失的(睡狗 Sleeping Dogs)」。行銷資源只該花在第一類人身上。 對必然者發券是浪費,對睡狗發券是反效果。
這就是進階 CRM 與入門 CRM 最深的分野:入門問「誰是好顧客」,進階問「我的這次介入,對誰真正製造了差異」。
動手試試:拆解一個忠誠方案的「真實效果」
假設某電商想評估「會員生日禮券」的成效,拿到下面這份(簡化的)資料:
| 組別 | 人數 | 當月回購率 | 每筆毛利 | 禮券成本/人 |
|---|---|---|---|---|
| 收到禮券(實驗組) | 5,000 | 22% | 300 元 | 60 元(僅回購者使用) |
| 未收禮券(對照組) | 5,000 | 17% | 300 元 | 0 |
很多人會直接說:「實驗組回購 22%,效果很好!」但這是陷阱。請跟著算一次增量:
- 增量回購率 = 22% − 17% = 5 個百分點。也就是說,22% 裡有 17% 是不發券也會回購的「必然者」,禮券真正多製造的回購只有 5%。
- 每千人的增量回購數 = 1,000 × 5% = 50 筆。
- 增量毛利 = 50 × 300 = 15,000 元。
- 禮券成本:實驗組回購率 22%,即每千人有 220 人用券,成本 = 220 × 60 = 13,200 元。
- 淨貢獻(每千人) = 15,000 − 13,200 = 1,800 元。
注意這個結果有多脆弱:增量只要從 5% 掉到 4%,增量毛利變 12,000 元,扣掉幾乎不變的券成本後就由正轉負。如果你天真地只看「實驗組回購 22%」而忽略對照組,你會誤以為這個方案賺翻了,實際上它只是勉強打平、甚至在某些假設下虧損。
這個練習的價值在於:它逼你把「看起來成功」與「真正創造增量」分開。一個沒有對照組的 CRM 報告,在科學上幾乎沒有說服力。
CRM 的暗面:個人化、操弄與隱私的界線
CRM 的力量全部來自顧客資料,而力量愈大,責任與風險也愈大。進階學習者必須正視三個入門篇較少深談的張力。
個人化與操弄的界線。 同樣是利用資料,「在你需要時推薦真正相關的商品」是服務,「精準偵測你的脆弱時刻(剛發薪、情緒低落、深夜衝動)再投放難以抗拒的訊息」則接近操弄。技術上兩者用的是同一套模型,差別在意圖與是否增進顧客的真實福祉。能做,不代表都該做。
資料倫理與法遵。 歐盟的《一般資料保護規則》(GDPR)與台灣《個人資料保護法》都要求蒐集個資需有合法基礎與明確告知,並賦予當事人查詢、更正、刪除(被遺忘權)的權利。CRM 系統若把資料視為理所當然的資產,很容易在合規上踩雷。知情同意不是法務部門的麻煩,而是關係信任的基礎——一段建立在偷偷監控上的「關係」,本質上是脆弱的。
忠誠的陰暗面:鎖定(lock-in)vs. 真心。 高轉換成本(點數會作廢、資料搬不走)確實能留住人,但這種「留」是被困住,不是被吸引。當顧客一有機會就逃離,你建立的其實是怨懟而非忠誠。健康的 CRM 應該讓顧客「留下來是因為想留」,而不是「走不了所以留」。
重點回顧
- CLV 是分布,不是平均數。 顧客行為高度異質,進階建模(Pareto/NBD、BG/NBD、Gamma-Gamma)從點估計走向機率估計,能對「沉默顧客是否已流失」做出有根據的判斷。
- 嚴謹的 CLV 必須折現。 折現率、預測期間與隨時間變化的留存率三個假設,都會大幅左右估值;看到任何 CLV 數字都該追問背後假設。
- CRM 是資源配置問題,不是「拉新 vs. 留存」的信仰之爭。 在取得、發展、留存三條戰線上比較邊際報酬;有時主動放手低價值顧客反而提升顧客資產(Customer Equity)。
- 忠誠方案的價值在增量,不在總量。 用 A/B 實驗與增量模型(Uplift Modeling)分離出「因介入而改變的可說服者」,避免把折扣浪費在必然者、甚至誤觸睡狗。
- CRM 的力量源於資料,責任也源於資料。 個人化與操弄、便利與隱私、鎖定與真心之間,都有一條需要倫理自覺去守的界線。
深入探討(研究所視角)
對有意進一步鑽研的同學,以下幾個方向值得延伸。
生存分析與流失預測的方法論。 流失本質上是「事件何時發生」的問題,適合用生存分析(Survival Analysis)。Cox 比例風險模型(Cox Proportional Hazards)能在控制顧客特徵的同時,估計各因子對「流失風險」的影響;而離散時間風險模型則更貼合按月觀測的訂閱資料。當代實務也大量採用梯度提升樹(如 XGBoost)與深度學習做流失預測,但要警覺一個老問題——預測準確不等於可介入:模型告訴你某人會流失,未必告訴你介入後他會留下(這正是 Uplift 與一般分類模型的根本差異)。
動態與序列決策:CRM 作為強化學習問題。 真實的顧客關係是一連串互動,今天的介入會改變明天的狀態。把它建模成馬可夫決策過程(Markov Decision Process)或用強化學習(Reinforcement Learning)求解「在每個顧客狀態下該採取什麼行動以最大化長期顧客價值」,是近年行銷科學的活躍前沿。難點在於探索(試新策略)與利用(用已知有效策略)的權衡,以及真人不是可以隨意實驗的環境。
從 CRM 到顧客資產驅動的企業估值。 Gupta、Lehmann 等學者主張,把所有顧客的 CLV 加總得到的顧客資產,可作為公司價值的領先指標,甚至能用來反推合理股價。這條線把行銷與財務、與資本市場接通——行銷不再只是花錢的部門,而是顧客資產的管理者。
因果機器學習(Causal ML)。 增量模型背後正在與計量經濟學、機器學習的因果推論浪潮匯流:因果森林(Causal Forests)、雙重穩健估計(Doubly Robust Estimation)、Meta-learners(如 T-learner、X-learner)能在大量特徵下估計「異質處理效果」(每個人對介入的不同反應)。掌握這套工具,是把 CRM 從「對平均顧客有效」推進到「對這位顧客最佳化」的關鍵。
公平性與演算法偏誤。 當 CRM 用模型決定「誰值得挽留、誰享有 VIP 待遇」,就可能把歷史資料中的偏誤制度化——例如系統性地把資源傾斜給某些族群,讓另一些人陷入「被服務得更差→流失→更被忽視」的負向循環。如何在追求顧客價值最大化的同時兼顧公平與包容,是一個技術與倫理交織、且日益重要的研究議題。