
當你把預算從 A 渠道挪到 B 渠道,總業績卻沒變,問題出在哪?
深入數位行銷量測的方法論核心:競價機制、歸因與增量的分野、LTV/CAC 與留存、MMM 三腳架,以及 cookieless 與 AI 搜尋帶來的典範轉移。
當你把預算從 A 渠道挪到 B 渠道,總業績卻沒變,問題出在哪?
入門篇用「砸十萬沒人理 vs. 零預算天天接單」帶你認識了數位行銷的三大引擎:SEO(搜尋引擎優化)、SEM(搜尋引擎行銷)與成效行銷(Performance Marketing),也介紹了轉換漏斗與 CTR、CVR、CPA、ROAS 這套指標。那是一張很好的入門地圖。但只要你真的握過一筆預算、做過一次「把錢從這裡挪到那裡」的決策,就會撞上一個入門篇沒講透、卻足以讓整個行銷部門爭論不休的難題:
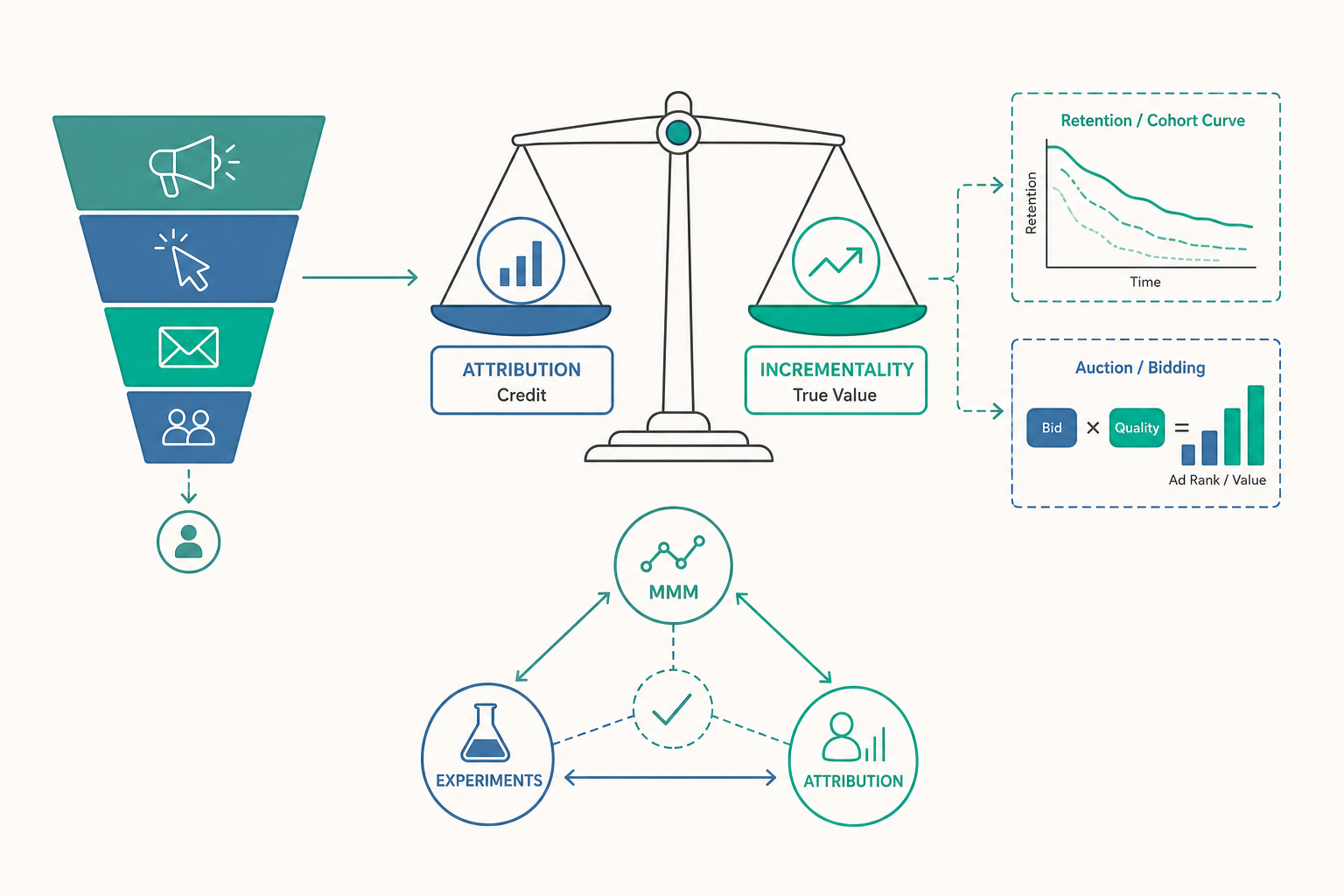
你看著後台數據,把預算從 ROAS 4.0 的渠道挪到 ROAS 6.0 的渠道,照理說整體報酬應該上升——結果一個月後,公司的總營收幾乎沒動。錢花得更「漂亮」了,生意卻沒變好。這不是執行失誤,而是成效行銷最核心的方法論陷阱:你以為自己在衡量「廣告創造的價值」,其實後台數字衡量的常常只是「廣告搶到的功勞」。 這兩者的差距,就是這篇進階文章要帶你跨過的那道門檻。
這篇文章不再重述什麼是 SEO、什麼是 CPC。我們要往下挖三層:第一,廣告競價的內部機制到底怎麼運作、為什麼出價高未必贏;第二,歸因(attribution)與增量(incrementality)的差別,以及為什麼成熟的團隊開始用 LTV/CAC 與留存來取代單次 ROAS;第三,當第三方 cookie 退場、AI 接管搜尋,整個量測典範正在發生什麼樣的結構性質變。換句話說,入門篇教你「怎麼投、怎麼算」,進階篇要回答的是「你算出來的數字,到底是不是真的」。
競價拍賣的內部:你買的不是位置,是一場機率
入門篇提到 SEM 是「競價拍賣」,出價之外還看廣告品質分數(Quality Score)。這個說法對,但停得太早。要真正理解數位廣告的成本從何而來,得把這場拍賣的內部結構拆開。
現代搜尋廣告用的是廣義第二價格拍賣(Generalized Second-Price Auction, GSP)的變體。它的精神是:你最終付的錢,不是你自己的出價,而是「剛好贏過下一名所需要的最低金額」。這個設計不是平台佛心,而是賽局理論的結果——第二價格機制能降低廣告主「猜測對手出價、來回算計」的誘因,讓大家更傾向誠實出價,市場因此更穩定。
但真正決定排名的,不是出價(bid)本身,而是廣告排名(Ad Rank)≈ 出價 × 品質分數(實務上還納入廣告格式、預期點擊率、到達頁體驗等因子)。把這個乘法看懂,你會得到一個對實務極關鍵的推論:
- 品質分數是一個槓桿。同樣想排在第一名,品質分數高的廣告主只要出較低的價就能達標;品質分數差的,得用更高的出價去硬補。
- 這意味著「相關性」會直接折算成「成本」。一支跟關鍵字高度貼合、到達頁體驗好的廣告,它的實際每次點擊成本(effective CPC)會比帳面出價低。
所以,當兩個品牌在同一個關鍵字上的 CPC 差了一倍,差距往往不在「誰口袋深」,而在「誰的廣告與落地頁更貼合搜尋意圖」。這把入門篇的「Quality Score」從一個名詞,變成了一條可以主動經營、直接影響獲客成本的工程——優化落地頁、對齊搜尋意圖、提升點擊率,本質上都是在「用內容品質換取更便宜的流量」。
為什麼你「贏得」一次點擊,未必是好事
競價還藏著一個進階者才會警覺的現象:贏家的詛咒(winner's curse)。在拍賣裡,「贏得」一個高價關鍵字,往往代表你對它的估值高過所有對手——而當所有人都在估同一個東西,估得最高的那個人,最可能是「估錯、估太高」的那個。把這個邏輯放回廣告:你願意為某組關鍵字出最高價、因而長期穩穩拿下它,很可能正說明你把它的價值算得過於樂觀。成熟的投手不會以「搶到曝光」為榮,而會持續問:「我為這次點擊付的價,真的對應它帶來的價值嗎?」這個提問,正好把我們引向下一個、也是整篇文章最重要的概念——歸因。
歸因的幻覺:你看到的 ROAS,是功勞還是價值?
入門篇在「研究所視角」裡點到了歸因問題,這裡我們把它升級成主菜,因為它是數位行銷實務裡最昂貴的誤解來源。
回到開頭那個謎題:把預算挪到高 ROAS 渠道,總營收卻不動。原因常常是這樣的——你後台看到的 ROAS,是用最後點擊歸因(last-click attribution)算出來的。一個顧客可能早就因為看過你的品牌、口碑、內容而決定要買,他在 Google 搜尋你的品牌名、點了那則「品牌字廣告」、然後下單。最後點擊歸因會把這整筆業績的功勞,記在那則品牌字廣告頭上,於是它的 ROAS 高得驚人。
但這裡有個致命問題:如果你把那則品牌字廣告關掉,這些人會不會還是買? 答案多半是「會」——他們本來就要買你,廣告只是攔在他即將完成的動作前面收了一筆過路費。這就是「功勞」與「價值」的分野:
- 歸因(attribution)回答的是「這筆業績,帳面上該記給誰」。它是一場功勞的分配遊戲。
- 增量(incrementality)回答的是「有了這個廣告 vs. 沒有這個廣告,多賺了多少」。它衡量的才是真正被廣告「創造」出來的價值。
一支廣告可以有很高的歸因 ROAS,卻有接近零的增量——它只是站在本來就會發生的轉換前面,把功勞收割了過來。這正是「把預算挪到高 ROAS 渠道、總營收卻不動」的真相:你挪過去的那個渠道,歸因數字漂亮,增量卻很低;你砍掉的那個渠道,帳面難看,卻可能正在默默開發新客。
衡量增量的黃金方法是實驗:把受眾隨機分成「看得到廣告」與「看不到廣告(控制組)」兩群,比較兩群的轉換差異,那個差才是廣告真正的貢獻。業界用的「ghost ads」「公益廣告對照(PSA test)」「地理實驗(geo experiment)」都是這個思路的變形。這也是為什麼近年大型廣告主越來越少問「我的 ROAS 多少」,而改問「我這筆花費的增量報酬(incremental ROAS, iROAS)是多少」——後者才扛得起真正的預算決策。
從「單次轉換」到「顧客一生的價值」:LTV、CAC 與留存
成效行銷的入門指標(CPA、ROAS)有個隱含假設:一次轉換就是終點。但對絕大多數需要回購的生意(訂閱、電商、App、SaaS)來說,真正決定生死的不是你獲得一個顧客花了多少,而是這個顧客一輩子能帶來多少。 這就要引入兩個進階核心指標:
- CAC(Customer Acquisition Cost,顧客獲取成本):獲得一位「新顧客」的平均成本。注意它和 CPA 的細微差別——CPA 可能把「老客回購」也算成轉換,CAC 嚴格只計新客。
- LTV(Lifetime Value,顧客終身價值):一位顧客在與你往來的整段關係裡,預期帶來的總毛利(已扣成本、常需折現)。
行業裡有一條粗略但好用的健康線:LTV / CAC ≥ 3,且 CAC 最好能在 12 個月內回收。如果你花 1000 元獲客,但這個顧客一生只貢獻 1200 元毛利,那這門生意的成長是「越衝越虧」——每多買一個客,就多燒一份錢。這解釋了一個入門者常困惑的現象:為什麼有些 ROAS 看起來不錯的公司還是倒了? 因為單次 ROAS 看的是「這一筆」,LTV/CAC 看的是「這個人的一輩子」,而很多生意的利潤藏在第二次、第三次購買裡。
要把 LTV 看準,需要世代分析(cohort analysis):把同一個月獲得的顧客當成一個「世代」,追蹤他們往後每個月的留存率與消費。留存曲線(retention curve)會告訴你一個殘酷的事實——多數生意的問題不在「拉新太貴」,而在「留不住人」。如果你的顧客第二個月就走掉七成,那無論獲客多便宜,LTV 都撐不起來;反過來,一條會「翹尾巴」(留存到後期趨於平穩)的曲線,代表你有一群死忠用戶,這才是可規模化的根基。
這個視角徹底改寫了預算思維:成熟的成長團隊不只盯著「漏斗最上層的獲客效率」,更把資源投向「留存與回購」——因為對 LTV 的一點點改善,會沿著整條世代曲線放大,最終允許你「付得起更高的 CAC 去搶市場」。在獲客成本逐年上漲的今天,「能比對手付更高 CAC 的人贏」,而能付更高 CAC 的前提,是你有更高的 LTV。
全漏斗的真相:上層投資為什麼總是「看起來沒效」
把歸因、增量、LTV 串起來,會浮現一個結構性的偏誤,值得每個未來的行銷人刻進腦裡:數位量測天生偏袒漏斗下層,系統性低估漏斗上層。
漏斗下層(再行銷、品牌字、購物車提醒)面對的是「已經想買的人」,轉換快、歸因容易、ROAS 漂亮。漏斗上層(品牌認知、新客觸及、內容經營)面對的是「還不認識你的人」,它的回報慢、跨渠道、難以用最後點擊歸因捕捉。於是當一家公司用「即時 ROAS」當唯一準繩,演算法與預算會像水往低處流一樣,不斷湧向下層——直到有一天,新客池見底,整盤生意失去了源頭活水。
這就是為什麼進階的量測會引入行銷組合模型(Marketing Mix Modeling, MMM)作為「最後點擊歸因」的補課。MMM 不追蹤個別使用者,而是用一段較長時間的總體資料(各渠道花費、銷售、季節、價格、競品、總經環境等),透過迴歸與時間序列方法,去估計每個渠道對「總銷售」的貢獻,包含品牌廣告那種延遲、外溢的長期效果。它和使用者層級的歸因正好互補:歸因看微觀的「這個人怎麼來的」,MMM 看宏觀的「整盤錢花得值不值」。
於是現代量測形成了一個「三腳架」:用MMM 做頂層戰略性的預算配置、用增量實驗(geo/holdout)校準因果真值、用使用者歸因做日常的戰術微調。任何單獨一條腿都會失衡——只信歸因會餓死品牌,只信 MMM 會失去日常敏捷,只做實驗則太慢太貴。看懂這個三腳架,你就跨過了「會看後台」到「會做決策」的分水嶺。
看一個例子
把上面所有概念套進一個情境。某新創訂閱制保養品牌「澈研」,後台數據如下:
- 再行銷廣告(針對加過購物車的人):ROAS 8.0,數字最漂亮。
- 品牌關鍵字廣告(搜「澈研」的人):ROAS 6.0。
- 新客觸及廣告(針對沒聽過品牌的人):ROAS 1.8,數字最難看。
入門級的反應是:把錢全集中到 ROAS 8.0 的再行銷。但進階的團隊先做了一個增量實驗——把品牌字廣告在隨機一半地區關掉兩週。結果發現:關掉品牌字廣告的地區,營收幾乎沒掉。這證明那則 ROAS 6.0 的品牌字廣告,增量極低,它只是攔截了本來就要搜品牌名來下單的人。同理,再行銷的高 ROAS 也有很大一部分是「本來就會回來的人」。
接著他們做世代分析,發現:透過「新客觸及廣告」進來的顧客,雖然首單 ROAS 只有 1.8,但六個月後的回購率與 LTV,遠高於其他渠道進來的客——因為這群人是真正「新被說服」的,黏著度最高。
最後他們用 MMM 看整盤,確認新客觸及的花費,在三到四週後對「總銷售」有顯著的延遲拉抬。
結論於是完全翻轉:他們沒有把錢全押在 ROAS 8.0 的再行銷,反而增加了 ROAS 1.8 的新客觸及預算,因為它才是真正在「擴大水池」、創造增量與長期 LTV 的渠道;同時把品牌字與再行銷的預算控制在「夠用就好」,因為它們大多在收割本來就會發生的轉換。半年後,這個看似違反直覺的決策,讓公司的總營收與新客數雙雙成長——而如果他們當初只信後台的單次 ROAS,會把最該投資的引擎當成最差的渠道砍掉。
這個例子的價值在於:它示範了「數據驅動」不等於「被表面數字驅動」。真正的數據素養,是知道每個數字在衡量什麼、又系統性地漏掉了什麼。
隱私典範轉移:當「追蹤每個人」不再可行
入門篇提過 cookieless 時代,這裡我們談它對「量測本身」的結構性衝擊,因為它正在逼整個產業重寫遊戲規則。
過去十五年,成效行銷的精準度建立在一個技術前提上:用第三方 cookie 與裝置識別碼,跨網站、跨 App 地追蹤同一個人,從而把「他看了哪則廣告」與「他在哪裡買了」串成一條完整的轉換路徑。這條路徑,正是使用者層級歸因得以成立的基礎。
如今這個前提正在崩解:各國隱私法規(如歐盟 GDPR)收緊、Apple 的 ATT 機制讓 App 追蹤需經使用者同意、瀏覽器逐步淘汰第三方 cookie。後果是——那條完整的轉換路徑出現了大量斷點,使用者層級的歸因越來越難做、也越來越不準。
產業的回應大致沿三條路走,每一條都是未來行銷人該認識的關鍵字:
- 第一方資料(first-party data)的價值重估:你自己直接、在使用者知情同意下蒐集的資料(會員、訂單、訂閱者)變成最珍貴的資產,因為它不依賴第三方追蹤。這也讓「會員經營」「電子報名單」這些看似老派的自有媒體,重新成為戰略要地。
- 建模與聚合取代逐人追蹤:當無法觀測每個人,就改用統計建模去「估計」效果——前面談的 MMM 與增量實驗,正因為不依賴個人層級追蹤,在這個時代逆勢回春。隱私限制反而把產業推回了更穩健的因果方法。
- 隱私強化技術(Privacy-Enhancing Technologies):差分隱私(differential privacy)、聯邦學習(federated learning)、資料潔淨室(data clean room)等,試圖在「不暴露任何個人」的前提下,仍能做出聚合層級的量測。
這個轉變和 Uedu 一貫主張的「隱私為本(Privacy by Design)」是同一個哲學的兩面:有效性與使用者的資料權利,必須放在同一個天平上權衡。 一個值得記住的判斷是——隱私收緊並不是「行銷的末日」,而是把行銷從「依賴監看個人」推向「依賴更誠實的聚合因果推論」。對學習者而言,這意味著未來十年最值錢的技能,不是「會操作哪個後台」,而是「在資料殘缺的世界裡,仍能做出可信的因果判斷」。
重點回顧
- 競價成本是「出價 × 品質分數」的函數:相關性會直接折算成更低的實際 CPC,所以「優化內容與落地頁」本質上是在「買更便宜的流量」;而長期穩拿高價字,要當心贏家的詛咒。
- 歸因衡量功勞,增量才衡量價值:高 ROAS 不代表廣告創造了銷售,它可能只是攔截了本來就會發生的轉換。判斷一個渠道真實貢獻,要靠隨機對照的增量實驗(iROAS),而非後台的最後點擊 ROAS。
- 生意的命脈是 LTV/CAC 與留存,不是單次 ROAS:對需要回購的生意,利潤藏在世代曲線的後段;LTV/CAC ≥ 3、CAC 在一年內回收,是常用的健康線。能付更高 CAC 的人,靠的是更高的 LTV。
- 量測天生偏袒漏斗下層、低估上層:只信即時 ROAS 會讓預算不斷湧向收割性渠道、餓死品牌與新客。成熟團隊用「MMM(戰略配置)+ 增量實驗(因果校準)+ 使用者歸因(戰術微調)」三腳架互補。
- 隱私典範轉移正在重寫量測規則:第三方 cookie 退場讓逐人追蹤失效,第一方資料、聚合建模與隱私強化技術崛起;未來的關鍵能力是「在資料殘缺下做出可信因果判斷」。
深入探討(研究所視角)
對於想把數位行銷量測推進到研究層級的學習者,以下幾條前沿值得長期追蹤。
第一,因果推論作為行銷科學的核心方法論。 整篇文章的張力,本質上都是「相關 vs. 因果」的問題:歸因是相關,增量才是因果。當大規模隨機實驗成本太高或不可行時,研究者轉向準實驗(quasi-experimental)方法——合成控制法(synthetic control)、雙重差分(difference-in-differences)、斷點迴歸(regression discontinuity)、以及近年用於地理實驗校準的貝氏結構時間序列(如 CausalImpact)。能在「觀察性的市場資料」中分離出廣告的真實因果效果、並誠實量化不確定性,是這個領域最硬、也最有貢獻空間的能力。
第二,歸因與 MMM 的「統一」難題。 使用者層級歸因(micro)與行銷組合模型(macro)長期是兩套互不相容的世界觀,一個看個人路徑、一個看總體迴歸,兩者給出的渠道貢獻常常打架。學界與業界正在探索如何把實驗校準、MMM 與歸因縫成一個一致的「三角量測(triangulation)」框架,讓三種方法互相約束、彼此校正。這牽涉到階層貝氏模型(hierarchical Bayesian modeling)與如何把實驗得到的「因果先驗」灌進 MMM——是一個方法論尚未收斂、極具開放性的研究地帶。
第三,隱私—效用的形式化權衡。 差分隱私把「隱私保護的強度」變成一個可調的數學參數(隱私預算 ε),這讓「保護多少隱私、會損失多少量測精度」第一次能被嚴謹地形式化、最佳化。如何在給定隱私約束下設計出仍能支持可信因果推論的量測機制,正在成為計算廣告(computational advertising)、機制設計與隱私計算的交叉前沿——它也直接呼應本平台「隱私為本」的治理立場:好的設計,是讓有效性與權利不必二選一。
第四,生成式 AI 重塑「搜尋」與內容供需的均衡。 當使用者越來越習慣由 AI 助理直接整合答案、而非逐一點開連結,傳統 SEO 賴以生存的「點擊」可能被「答案直接生成」取代,催生出「生成式引擎優化(GEO, Generative Engine Optimization)」這個尚無定論的新課題——什麼樣的內容結構,更容易被大型語言模型採信與引述?更深一層,當 AI 既是內容的「消費者」(讀你的網頁)又是「生產者」(生成回答),整個內容市場的供需均衡、誘因結構乃至「人類為誰而寫」都會被重新定義。這是一片正在快速演化的空白地帶,留給有志於數位行銷研究的同學去開疆。
延伸閱讀方向:關於增量與廣告實驗,可參考 Gordon 等人對 Facebook 廣告「觀察性方法 vs. 實驗」的大規模比較研究;量測架構方面,Google/Meta 公開的 MMM 與地理實驗方法文件(如開源的 Meridian、GeoLift);以及計算廣告、隱私計算與消費者文化理論(CCT)近年的期刊文獻。