
同樣一份資料,為什麼兩個研究者會跑出相反的結論?
深入測量模型、因果識別(DAG 與混淆/中介/對撞因子)、準實驗設計與重製危機,理解社會研究方法最硬核的內在邏輯。
同樣一份資料,為什麼兩個研究者會跑出相反的結論?
想像一個情境:兩個研究團隊,拿到同一份「全國家庭收支與教育」的大型調查資料,都想回答「補習到底有沒有幫助提升學業成績」。半年後,第一隊發表的結論是「補習顯著提升成績」,第二隊卻說「控制了家庭背景之後,補習的效果幾乎消失」。資料一模一樣,結論卻南轅北轍。
這不是誰造假,也不是誰計算錯誤。差別藏在更深的地方:他們對「該控制哪些變項」做了不同的判斷,而這個判斷,決定了他們在估計一個因果效果,還是在估計一個被混淆的假象。
入門篇告訴你「相關不等於因果」、要警惕第三變項。但真正困難的問題從這裡才開始:在無法做實驗的觀察資料裡,到底「該」控制什麼、「不該」控制什麼?多控制一個變項,一定讓估計更準嗎? 答案是否定的——而且控制錯了變項,會親手製造出原本不存在的偏誤。這篇文章要帶你走進社會研究方法最硬核、也最迷人的核心:測量與因果識別的內在邏輯。
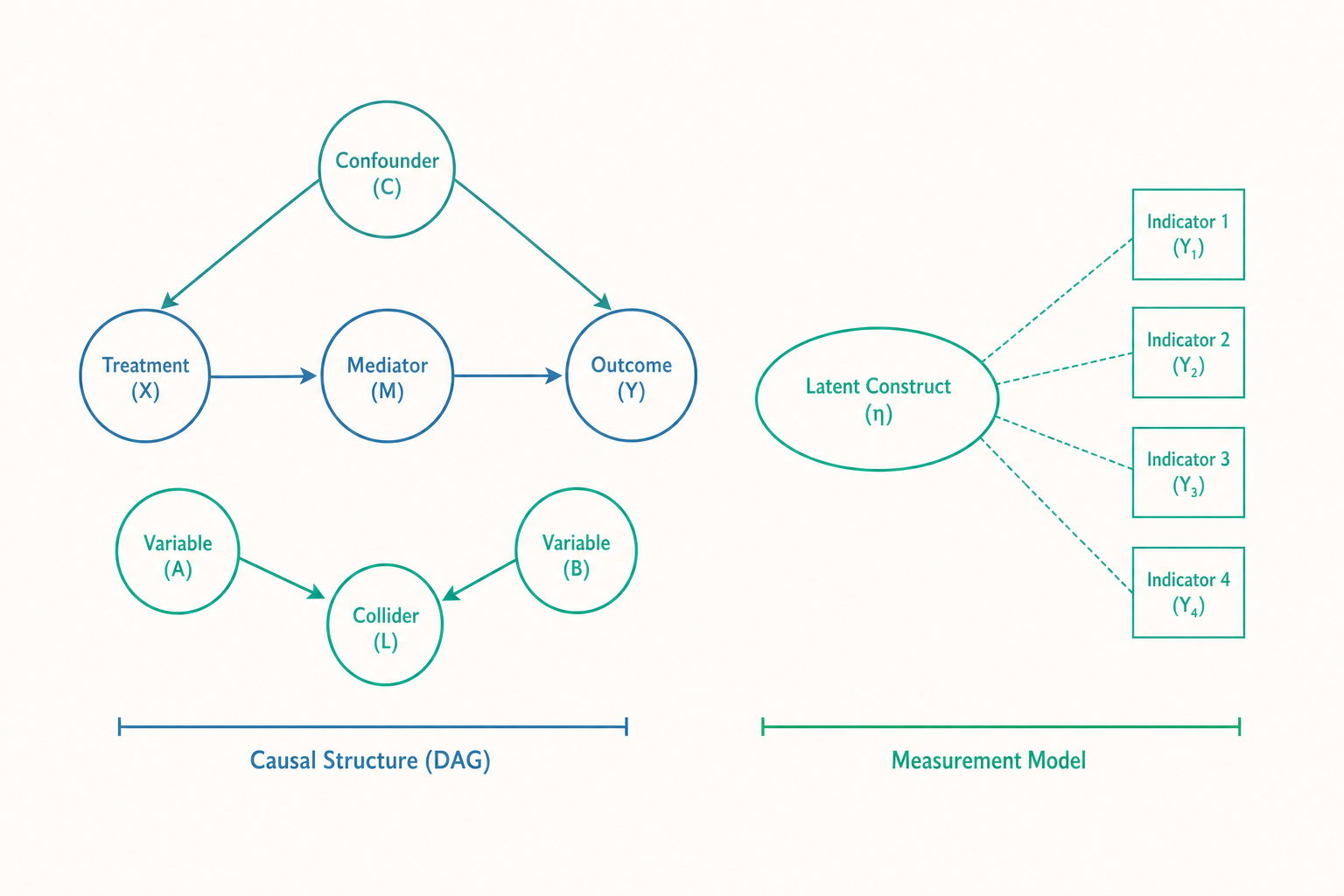
測量不只是「量一下」:潛在變項與測量模型
入門篇談過效度與信度,把測量講成一個「準不準、穩不穩」的問題。但社會學最常研究的那些東西——權威性人格、社會資本、階級認同、制度信任、性別意識——有一個共同特性:它們沒有一把現成的尺可以直接量。你看不到、摸不到「社會資本」,你只能觀察一些被它影響的外在表現。
這類概念在方法論上稱為潛在變項(latent variable):它本身不可直接觀測,只能透過多個觀測指標(observed indicator)間接推估。比方說「制度信任」這個潛在變項,研究者會用一組問題去逼近它:「你對法院的信任程度?」「對警察?」「對立法院?」「對媒體?」每一題都只是這個看不見構念的一個側面,每一題也都帶著各自的測量誤差。
這就帶出一個入門篇沒展開的關鍵:測量本身需要一個模型。 把單一題目的答案直接當成構念,是很粗糙的做法。較嚴謹的取向會用驗證性因素分析(confirmatory factor analysis, CFA)或更完整的結構方程模型(structural equation modeling, SEM),明確區分「真實構念」與「測量誤差」兩層,並用統計方法檢驗「這幾個指標真的在量同一件事嗎」。
看一個例子
假設你想測量大學生的「學習投入(engagement)」。你設計了四道題:上課專注度、課後自主學習時數、發問頻率、作業完成品質。在做任何分析之前,一個受過進階訓練的研究者會先問:
- 這四題的得分彼此高度相關嗎?如果一個學生在前三題都高、第四題卻很低,可能第四題量到的根本是別的東西(例如「對某科目的興趣」而非整體投入)。這對應收斂效度(convergent validity)。
- 這四題合起來,跟另一個概念(比如「考試焦慮」)的題目能不能清楚區分開?如果分不開,代表你的「投入量表」其實混進了焦慮,這對應區辨效度(discriminant validity)。
只有通過這些檢驗,把四題加總或加權成一個分數才有意義。這就是為什麼進階研究裡,「我用了一份量表」之後,緊接著一定要報告信度係數(如 Cronbach's α、組合信度)與效度檢驗——少了這一步,後面所有漂亮的統計都建立在流沙上。
值得強調一個反直覺的點:信度高不代表你量對了東西。 一份題目都在問「你多認同傳統性別分工」的量表,可能內部一致性極高(高信度),但如果你拿它來宣稱量到的是「整體保守程度」,效度依然可疑。測量的核心難題,永遠是效度而非信度。
因果識別:DAG、混淆因子、對撞因子
現在進入這篇文章的心臟。入門篇說「要控制第三變項」,聽起來控制越多越好。但這是一個流傳很廣、卻錯誤的直覺。當代因果推論用一個簡單的視覺工具——有向無環圖(Directed Acyclic Graph, DAG)——清楚說明:變項分成幾種角色,控制錯角色會帶來災難。
把每個變項畫成一個點,因果方向畫成箭頭。三種典型結構:
第一種,混淆因子(confounder)。 某個變項同時影響「原因」與「結果」。例如研究「補習 → 成績」時,「家庭社經地位」既影響孩子是否去補習,也影響成績。它在 DAG 上是一個指向兩邊的共同源頭。這種變項必須控制,否則你看到的「補習與成績的相關」,有一部分其實是家庭背景偽造出來的。這正是開頭兩隊結論不同的根源:第二隊控制了家庭背景,假象就消失了。
第二種,中介因子(mediator)。 某個變項位在因果鏈的中間:補習 → 增加練習量 → 成績。「練習量」是補習發揮作用的管道。這裡的陷阱是:如果你把中介因子也「控制」掉,你會把補習真正的效果一起堵死,得到「補習沒效」的錯誤結論。要不要控制中介,取決於你想估計的是總效果還是直接效果——這是一個必須事先想清楚的設計決定,不是越控制越好。
第三種,也是最反直覺的——對撞因子(collider)。 某個變項同時被「原因」與「結果」影響,是兩個箭頭共同指向的「下游」。經典例子:在「演藝圈」這個樣本裡,研究發現「外貌」與「演技」呈負相關,於是有人下結論「漂亮的人通常演技差」。但這是假的。真相是:能進演藝圈,要嘛靠外貌、要嘛靠演技;「是否在演藝圈」這個篩選條件,正是一個對撞因子。當你只看圈內人(等於「控制」了這個對撞因子),就人為製造出原本不存在的負相關。這叫對撞偏誤(collider bias),也是選擇偏誤(selection bias)的一種深層機制。
一句話總結這套邏輯:控制混淆因子能消除偏誤,控制中介因子會堵死效果,控制對撞因子會無中生有。 「該控制什麼」不是統計問題,而是你對因果結構的理論判斷——而 DAG 逼你把這個判斷攤在陽光下,讓別人能檢驗。
準實驗:在做不了實驗時逼近因果
社會學的研究對象大多無法被隨機分配。你不能為了研究貧窮的影響,「隨機指定」一群人變窮。於是研究者發展出一整套準實驗(quasi-experimental)設計,巧妙利用現實世界裡「接近隨機」的契機。
差異中差異(difference-in-differences, DID): 當某個政策只在部分地區、部分時間實施,你可以比較「受影響組」與「未受影響組」在政策前後的變化量差異。例如某縣市實施免費營養午餐,鄰縣沒有,你比較兩縣學童健康在政策前後的變化差距。它的巧妙在於:透過「相減」,把兩組各自原有的、固定不變的差異(如縣市本來就不同的飲食文化)給消掉了。
斷點迴歸(regression discontinuity, RD): 當某個資格是由一條人為的門檻決定時——例如「指考 PR 值 60 以上錄取某校」——分數落在 59.8 和 60.2 的兩群人,能力其實幾乎一樣,純粹被一條武斷的線分到兩邊。比較這條線「左右兩側緊鄰」的人,就近似一場小型隨機實驗。
工具變項(instrumental variable, IV): 找一個只透過「原因」影響「結果」、不走其他路徑的外生變項當槓桿。例如研究「教育對收入的影響」時,用「義務教育年限的法律改革」當工具——法律改幾年純粹是政策決定,與個人能力無關,卻會推動實際受教年數。
這些方法的共同精神是:既然不能靠實驗創造隨機,就去現實世界裡尋找『接近隨機』的自然縫隙。 但它們都建立在一些無法被資料直接證明的假設上(DID 的「平行趨勢假設」、RD 的「門檻附近連續假設」、IV 的「排除限制」)。進階研究的功力,泰半展現在論證這些假設為何在自己的情境下成立——這也是審稿人最會緊咬的地方。
從一份資料到一個結論:誤差會層層累積
把測量與因果識別接起來看,你會發現一個社會學研究其實是一條長長的推論鏈,每一環都可能引入誤差:
| 環節 | 潛在的威脅 | 對應的概念 |
|---|---|---|
| 構念 → 指標 | 量表沒測到真正想測的東西 | 構念效度(construct validity) |
| 母體 → 樣本 | 抽樣有系統性偏誤 | 外部效度(external validity) |
| 變項 → 因果 | 沒控制混淆、誤控對撞或中介 | 內部效度(internal validity) |
| 資料 → 顯著 | 多重比較、p 值操弄 | 統計結論效度(statistical conclusion validity) |
這張表來自 Campbell 與 Cook 的效度威脅四分類,是進階方法論的骨架。它提醒我們:一個結論的可信度,等於這條鏈上最弱一環的可信度。你可以用最尖端的因果模型,但如果一開始量表就量錯了東西,或樣本本身就偏,再精密的後段分析也只是把垃圾算得很精緻——這就是著名的「垃圾進、垃圾出(garbage in, garbage out)」。
動手試試
下次你讀到一則「研究顯示 X 導致 Y」的新聞,試著用這條鏈逐環拷問它:
- 它怎麼測 X 和 Y 的?(用單一題目?還是經過效度檢驗的量表?)
- 它的樣本是誰?(網路自願填答?還是隨機抽樣?能推論到誰?)
- 它控制了哪些變項、為什麼?(有沒有漏掉明顯的混淆因子?會不會誤控了對撞或中介?)
- 它的「顯著」可信嗎?(樣本多大?是不是試了很多種跑法,才挑出一個有顯著的來報?)
你會很快發現,多數聳動標題撐不過這四問。能熟練地做這套拷問,你就具備了社會科學的方法論素養——這比記住任何一個統計公式都更接近研究的本質。
p 值操弄與重製危機:方法論的當代反省
最後一個進階主題,是這十多年震撼整個社會科學界的重製危機(replication crisis)。
故事的核心是:許多曾被視為定論、登上頂尖期刊的研究發現,當其他團隊重新做一次,結果重製不出來。心理學的大規模重製計畫發現,能被成功重製的研究比例低得令人不安。社會學、經濟學也未能倖免。問題出在哪?
一大元凶是研究者自由度(researcher degrees of freedom)衍生的 p 值操弄(p-hacking)。在分析一份資料時,研究者面對無數個微小選擇:要不要剔除極端值、用哪幾個控制變項、怎麼分組、看哪個子樣本……只要不斷嘗試各種組合,總能「湊出」一個 p 值小於 0.05、看起來顯著的結果。再加上發表偏誤(publication bias)——期刊偏好刊登「有顯著發現」的論文,不顯著的結果被默默塞進抽屜(檔案抽屜問題,file drawer problem)——整個文獻就被系統性地扭曲成「假陽性的展覽館」。
對此,方法社群推出了一系列開放科學(open science)改革:
- 預先註冊(pre-registration):在看資料之前,就公開鎖定你的假設與分析計畫,事後不能再「換跑法」。這把「探索性分析」和「驗證性分析」清楚分開。
- 資料與程式碼公開:讓任何人都能重跑你的分析,重製性成為可檢驗的承諾。
- 重視效果量(effect size)與信賴區間,而非只看 p 值是否「過關」:「有沒有顯著」是個很低的門檻,「效果有多大、估計有多精確」才是真正該關心的。
這場危機帶來的最深刻啟示是:科學的可信度不來自單一研究的『重大發現』,而來自整個社群可以彼此檢驗、累積、修正的制度。 對學習研究方法的人而言,這意味著:嚴謹不只是個人美德,更是一套讓錯誤無所遁形的公共設計。
重點回顧
- 測量需要模型:社會學常研究的是看不見的潛在變項,必須用多個指標、透過 CFA/SEM 區分真實構念與測量誤差,並檢驗收斂效度與區辨效度。
- 「控制越多越好」是錯的:變項分為混淆、中介、對撞三種角色。控制混淆消除偏誤、控制中介堵死效果、控制對撞無中生有——該控制什麼是理論判斷,DAG 逼你把它說清楚。
- 準實驗在現實裡尋找『接近隨機』的縫隙:DID、RD、IV 各有巧思,但都依賴無法被資料直接證明的識別假設,論證假設成立是進階研究的真功夫。
- 誤差會層層累積:構念、抽樣、因果、統計四種效度威脅,一個結論的可信度取決於最弱的一環,「垃圾進、垃圾出」。
- 重製危機揭露了制度性的脆弱:p 值操弄與發表偏誤扭曲了文獻,開放科學(預先註冊、資料公開、重視效果量)是讓嚴謹可被公共檢驗的解方。
深入探討(研究所視角)
對準備進入研究所、或想真正掌握方法論前沿的讀者,這裡再推進幾個層次。
第一,因果推論有兩種互補的語言,研究生要學會在兩者間翻譯。 一套是 Rubin 的潛在結果框架(potential outcomes / counterfactual framework),從「同一個人在處理與未處理下的兩種假想結果之差」定義因果效果,核心難題是「反事實永遠觀測不到」。另一套是 Judea Pearl 的結構因果模型(structural causal model)與 do-算子,用 DAG 與「後門準則(backdoor criterion)」系統性地判斷「該控制哪一組變項才能識別因果」。前者擅長談估計與偏誤,後者擅長談識別與圖形直覺,成熟的研究者會把兩套語言視為同一件事的兩種表述。
第二,測量誤差不是小事,它會系統性地偏誤你的因果估計。 入門把測量誤差當成「讓估計變吵雜一點」的隨機噪音,但這太樂觀。非系統性(古典)測量誤差會把迴歸係數往零的方向壓(衰減偏誤,attenuation bias),讓真實存在的效果被低估;而系統性測量誤差(例如社會期許偏誤讓人少報歧視態度、多報投票行為)則會把估計往特定方向扭曲,且無法靠加大樣本解決。這正是潛在變項模型(SEM)的價值所在:它能在估計結構關係的同時,明確地把測量誤差建模進去,而不是假裝它不存在。
第三,「顯著性」這個概念本身正受到根本性的質疑。 美國統計學會曾罕見地發表聲明警告 p 值的誤用,部分學者甚至主張廢除 p < 0.05 的二分門檻、或把門檻調嚴到 0.005。背後是更深的哲學分歧:頻率學派的 p 值回答的是「假設虛無為真時,看到這麼極端資料的機率」,這跟人們真正想知道的「假設為真的機率」是兩回事。貝氏統計(Bayesian statistics)提供了另一條路,直接談「給定資料下,各種假設的可信程度」,並用貝氏因子(Bayes factor)取代二分的顯著與否。研究生階段值得認真理解這場「頻率 vs 貝氏」之爭,它不只是技術選擇,更牽涉「機率到底是什麼」的世界觀。
第四,方法的權力面向不容迴避——資料從來不是中立的。 進階方法論越來越關注:誰被算進去、誰被排除、用什麼類別來分類人,本身就是權力的運作。官方統計的分類(族群、職業、家戶)會反過來形塑社會對自己的認識;演算法與大數據看似客觀,卻會把歷史中的偏見自動化、放大、並披上科學外衣(演算法偏誤)。女性主義方法論提出的「情境知識(situated knowledge)」主張:所有知識都來自某個特定位置,宣稱「無立場的客觀」(the view from nowhere)反而是最不誠實的。把方法純粹當成中立技術的人,往往看不見自己正在再生產哪些不平等。
進階閱讀建議: 因果推論可從 Cunningham 的《Causal Inference: The Mixtape》或 Huntington-Klein 的《The Effect》入門(兩本都免費線上可讀、對社會科學友善),再進到 Pearl 的《Causality》與 Morgan、Winship 的《Counterfactuals and Causal Inference》。測量與潛在變項可讀 Bollen 的 SEM 經典;重製危機與開放科學則建議讀 Open Science Collaboration 的大規模重製報告原文。最後一個忠告:工具會過時,但「對自己的推論鏈保持懷疑」這個習慣不會。 永遠去問「我這個結論,最可能錯在哪一環」,比追逐任何最新的統計套件都更接近一個研究者的成熟。