
受控的幻覺:當大腦是一台預測機器,知覺錯誤是 bug 還是 feature?
從預測編碼到貝氏大腦——打開知覺運算的引擎蓋,理解為何錯覺恰恰證明了大腦運作得多漂亮
如果大腦是一台「預測機器」,那知覺錯誤究竟是 bug 還是 feature?
你在入門篇已經接受了一個違反直覺的觀點:你看見的世界並非外在實境的忠實副本,而是大腦根據感官線索所做的「最佳猜測」(best guess)。現在我們把問題推得更遠一步。
如果知覺真的是猜測,那它一定有一套運算規則。猜測不會憑空產生——它需要把模糊不清的感官訊號,和某種「世界本來應該長什麼樣」的先驗假設結合起來。這套運算到底是什麼?它能不能被寫成數學式?當它出錯時,是大腦壞掉了,還是這個錯誤恰恰暴露了大腦平時運作得多麼漂亮?
這一篇,我們不再停留在「知覺是建構出來的」這個結論,而是要打開引擎蓋,看看建構知覺的演算法本身——預測編碼(predictive coding)與貝氏推論(Bayesian inference)。這是當代知覺神經科學最具野心的統一框架之一。
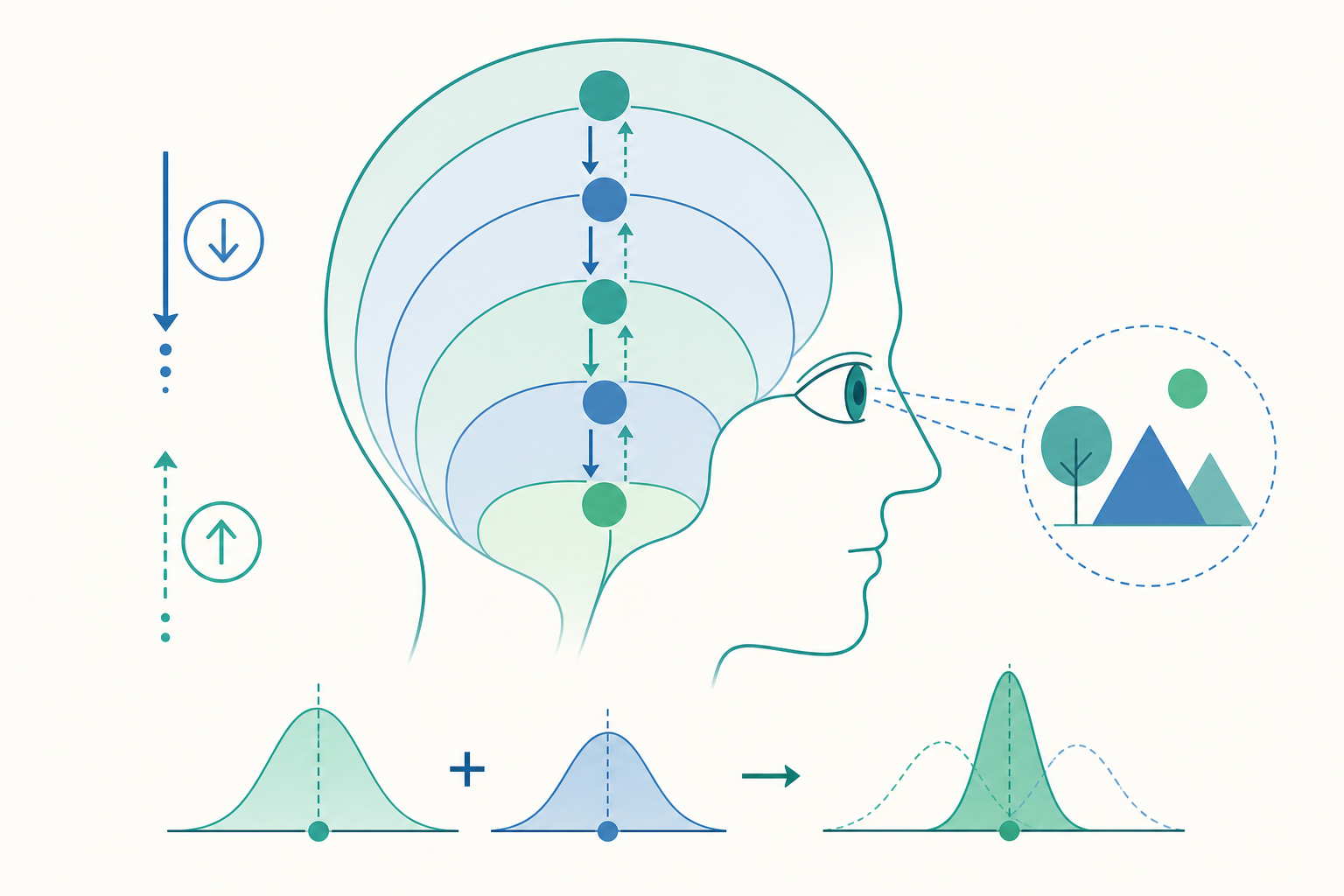
從「由下而上」到「由上而下」:知覺的方向之爭
傳統感官生理學給我們一個樸素的圖像:光打在視網膜上,訊號沿著視神經往上傳,經過外側膝狀體(LGN)、初級視覺皮質(V1)、再到更高階的腦區,一層一層把線條組成形狀、把形狀組成物體。這是由下而上(bottom-up)的處理:資訊從感官端流向認知端。
但這個圖像有一個致命問題:它解釋不了「速度」與「歧義」。
視覺輸入永遠是不充分的。視網膜是二維的,外在世界是三維的——同一個二維影像,理論上對應無限多種三維場景。這就是知覺科學裡著名的逆向光學問題(inverse optics problem)。一個橢圓形的視網膜投影,可能來自正面看的橢圓盤,也可能來自斜著看的圓盤。光靠由下而上的訊號,大腦無法決定到底是哪一個。
於是另一個方向變得不可或缺:由上而下(top-down)的處理。大腦並非被動等待感官資料填滿,而是主動地下注——它先根據過往經驗與當下脈絡,生成一個對世界的假設,再用感官輸入去檢驗、修正這個假設。
Richard Gregory 在 1970 年代就用「知覺即假設」(perception as hypothesis)來描述這件事。但真正把它升級成一套可計算理論的,是後來的預測編碼框架。
預測編碼:大腦只在乎「沒猜中的部分」
預測編碼的核心主張極其簡潔,卻威力驚人:
皮質的每一層,都在試圖預測它下一層(更接近感官端)將會送來什麼訊號;實際傳上來的,不是原始資料,而是預測與實際的落差——也就是預測誤差(prediction error)。
換句話說,大腦是一個層層堆疊的預測機器。高階腦區把它的預測「往下送」給低階腦區;低階腦區拿這個預測去對照真實的感官輸入,只把「沒對上的部分」往上回傳。如果預測完全準確,往上傳的誤差就是零,高階腦區什麼都不必更新。
這個架構之所以聰明,在於它的效率。神經傳遞與代謝都是昂貴的。如果世界大致符合預期(而日常世界確實如此),那麼大量重複、可預測的訊號根本不需要費力上傳——大腦只需處理「驚訝」的部分。這呼應了資訊理論裡的觀念:可預測的訊號攜帶的資訊量低,不值得花頻寬傳遞。
Rao 與 Ballard 在 1999 年發表的計算模型是這個框架的里程碑。他們證明:如果讓一個階層式網路去學習自然影像,並要求每一層去預測下一層、只上傳殘差,那麼網路自發學出的特徵,竟然和真實視覺皮質神經元的「感受野」(receptive field)性質高度吻合,甚至能解釋一些原本被視為「異常」的現象,例如端點抑制(end-stopping)——某些 V1 神經元對短線段反應強烈,對延長的長線段反應反而減弱。在預測編碼裡,這正是因為延長部分「可被預測」,誤差被抵消掉了。
看一個例子:空心面具錯覺(hollow-mask illusion)
拿一個面具,把它凹面(內側)朝向你。理論上你應該看見一張凹進去的臉。但絕大多數人看見的卻是一張凸出來的、正常的臉——即使你明知它是凹的,這個錯覺依然頑固存在。
為什麼?因為「臉是凸的」是一個極強的先驗假設。你這輩子看過的每一張真實臉孔都是凸的,這個統計規律深深刻進你的視覺系統。當凹面具的感官訊號(陰影、輪廓)送上來時,「凸臉」這個由上而下的預測太強了,強到足以壓過矛盾的感官誤差。大腦寧可相信自己的猜測,也不相信眼前的證據。
這個例子的精彩之處在於它的「可重複測量性」。研究顯示,思覺失調症(schizophrenia)患者對空心面具錯覺的抵抗力較強——他們比較容易正確看出那是凹的。在預測編碼的詮釋裡,這暗示他們的「先驗權重」相對較弱,或者說感官誤差被賦予了過高的權重。錯覺不再只是趣味,而成了探測知覺運算參數的工具。
貝氏大腦:把「猜測」寫成機率
預測編碼回答了「大腦如何運算」,而貝氏推論回答了「為什麼這樣運算是合理的」。兩者是同一枚硬幣的兩面。
貝氏定理告訴我們,要從不確定的證據推論真相,最佳策略是把兩樣東西相乘:
- 先驗機率(prior):在看到任何證據之前,各種假設的合理程度(來自過往經驗的統計規律)。
- 概似度(likelihood):如果某個假設為真,當前感官證據出現的可能性。
兩者結合,得到後驗機率(posterior):在看到證據之後,各假設的合理程度。大腦的知覺,就是這個後驗分布的「最佳估計」。
這套數學立刻解釋了一個關鍵直覺:當感官證據愈不可靠,先驗就愈該主導。在昏暗的房間裡,你的視覺輸入充滿雜訊(概似度很「寬」、很模糊),這時大腦會更依賴先驗——所以你更容易把衣架看成人影。反過來,光線充足、輪廓清晰時,感官證據說了算,先驗的影響就退居其次。這種「依不確定性動態調整權重」的能力,正是貝氏知覺與預測編碼的精髓,在框架裡稱為精確度加權(precision weighting)。
動手試試:用兩種感官打架,逼大腦自曝權重
貝氏整合最漂亮的實證,來自多感官整合(multisensory integration)。
Ernst 與 Banks 在 2002 年做了一個經典實驗。他們讓受試者同時用「看」和「摸」去判斷一個物體的高度,並且偷偷讓視覺與觸覺給出略微衝突的訊息。結果發現,受試者的最終判斷,恰恰是兩種感官的加權平均——而且權重的分配,精準地符合貝氏理論的預測:哪個感官此刻較可靠(變異較小),它的權重就較高。當實驗者人為地增加視覺雜訊,受試者就自動把更多權重轉移到觸覺上。
你可以在生活中體驗一個近親版本:腹語效應(ventriloquist effect)。看電影時,聲音其實來自牆角的喇叭,但你「聽見」的對白卻彷彿從螢幕上演員的嘴裡發出。因為在「定位」這件事上,視覺通常比聽覺精確得多,於是大腦用視覺位置去「綁架」了聲音的位置。這不是錯誤,而是大腦正確地把權重押在較可靠的感官上——只是這次它被人為的影音分離給「騙」了。
關鍵洞見是:錯覺不是大腦的失靈,而是它在非典型情境下,依然忠實執行同一套最佳化規則的結果。 在自然環境裡讓你準確的那套機制,被搬到實驗室的人造情境裡,就產生了可預測、可測量的偏差。
主動推論:知覺與行動其實是同一件事
如果你覺得預測編碼已經夠激進,那麼它的延伸版本——主動推論(active inference,由 Karl Friston 提出)——會更顛覆。
主動推論說:要減少預測誤差,大腦其實有兩條路。
第一條路你已經知道:更新你的內在模型,讓預測去貼合感官(這就是知覺)。
第二條路是反過來——改變這個世界,讓感官去貼合你的預測(這就是行動)。如果你的大腦預測「我的手指此刻應該碰到杯子」,但感官說「沒有」,你可以選擇移動手去抓住杯子,主動製造出符合預測的感官輸入。
在這個觀點下,知覺與行動不再是兩個分開的系統,而是同一個「最小化預測誤差」目標下的兩種手段。這也順帶解釋了一個老謎題:為什麼你搔不到自己癢? 因為當你自己動手時,大腦能精準預測即將到來的觸覺,於是把這個「可被預測」的感官訊號的精確度調低、抵消掉——你自己製造的感覺被「打折」了。別人來搔你,大腦預測不準,誤差訊號就保留下來,於是才覺得癢。Blakemore 等人 2000 年的研究用功能性磁振造影證實了這種自我產生動作對體感皮質反應的抑制。
重點回顧
- 逆向光學問題:感官輸入永遠不足以唯一決定外在世界,因此知覺必須是「推論」而非「讀取」。由上而下的假設不是錦上添花,而是邏輯上的必需品。
- 預測編碼:皮質階層往下送預測、往上只傳「預測誤差」。這讓大腦極度高效——只處理意料之外的訊號。Rao & Ballard(1999)的計算模型能重現真實視覺皮質的特性,如端點抑制。
- 貝氏大腦:知覺是先驗(經驗統計)與概似度(當前證據)相乘後的後驗估計。證據愈不可靠,先驗主導力愈強——這由「精確度加權」動態調控。
- 錯覺是 feature 不是 bug:空心面具、腹語效應、自我搔癢失效,都是同一套最佳化規則在非典型情境下的忠實輸出。研究錯覺,等於在測量知覺運算的參數。
- 主動推論:減少預測誤差有兩條路——更新模型(知覺)或改變世界(行動)。兩者統一在同一目標之下。
深入探討(研究所視角)
若你打算往認知神經科學或計算神經科學深耕,以下幾條線索值得追下去。
一、自由能原理(Free Energy Principle)與其爭議。 Friston 主張,所有上述機制都可以歸結到一條更抽象的原則:任何能持續存在的自適應系統,都必須最小化變分自由能(variational free energy)——一個對「預測誤差驚訝量」的上界估計。這個框架野心極大,企圖統一知覺、行動、學習乃至生命本身。但它也招致嚴厲批評:反對者認為它在數學上幾乎不可證偽(unfalsifiable),任何行為都能事後被詮釋成「在最小化自由能」。這場辯論(可參考 Colombo & Wright、Andrews 等人的批判性文獻)本身就是學習「一個理論該如何被科學社群檢驗」的絕佳案例。
二、預測編碼的神經實作仍未定論。 框架要求皮質中存在功能上分離的兩群神經元:傳遞「預測」的與傳遞「誤差」的。理論上常把它對應到皮質的層狀結構(如深層送預測、淺層送誤差)與不同頻段的神經振盪(gamma 頻段攜帶前饋誤差、beta 頻段攜帶回饋預測,見 Bastos 等人 2012、2015 的工作)。但這些對應目前仍是假說,直接的單細胞層級證據有限。這是一個開放的實證戰場。
三、計算精神病學(computational psychiatry)的轉譯前景。 把「先驗 vs. 概似度的權重失衡」當作一個可量化的旋鈕,許多精神疾病可以被重新描述:自閉症或許是「先驗過弱/感官誤差精確度過高」(因此細節壓不下去、對變化過度敏感);思覺失調的幻覺與妄想或許是「先驗過強」凌駕了感官否證。Powers 等人 2017 年在《Science》發表的條件化幻聽實驗,正是用貝氏框架去量化「先驗如何誘發幻覺」的開創性嘗試。這條路把抽象的運算理論,連到了真實的臨床測量與介入。
四、與機器學習的雙向啟發。 預測編碼與深度學習中的自編碼器(autoencoder)、預測性學習(predictive learning)在精神上高度相通。近年有研究探討預測編碼能否作為反向傳播(backpropagation)的生物學上更合理的替代演算法,因為它只用局部誤差訊號就能近似全域梯度。這意味著研究大腦的知覺理論,可能反過來啟發更節能、更接近生物的人工智慧架構——這正是 Uedu 在 Educational Omics 框架下,把認知歷程(Cognomics)與計算建模並置研究的旨趣所在。
最後留一個思辨給你:如果知覺真的是「受控的幻覺」(controlled hallucination,Anil Seth 語),那麼「客觀現實」與「主觀經驗」的界線究竟在哪裡?當不同人的先驗不同,我們是否從來就不曾看見「同一個」世界?這不只是哲學遊戲——它直接決定了我們該如何理解他人的感受、如何設計能適應個體差異的學習環境。