
g 因素藏在哪個認知零件裡?智力的因素結構、認知化約與基因組學
當你已經知道 g 是因素分析萃取的統計構念,下一步該問:它由什麼認知歷程組成?高階模型與雙因素模型、工作記憶與反應時間變異性、測量恆等性與 IRT、再到多基因分數,帶你把智力從「一個分數」變成「一個可被機制檢驗的科學對象」。
如果 g 真的存在,它到底「藏」在哪一個認知零件裡?
你已經知道:各種認知測驗彼此正相關,於是因素分析(factor analysis)萃取出一個叫 g 的共同因素。但這個答案其實只是把問題往後推了一步。一個更尖銳的問題立刻浮現:g 到底由什麼基本認知歷程構成? 當你坐在魏氏量表前解一道矩陣推理題,大腦裡哪一個「零件」在決定你的成績——是你能同時記住多少訊息?是你神經傳導有多快?還是你能多有效地壓抑無關干擾?
入門篇把 g 當成一個統計起點。這篇進階文章要做的,是把這個黑盒子拆開:我們要進入因素模型的內部結構(g 該被畫成金字塔頂端還是貫穿全身的軸線?)、g 的認知化約(它能不能被還原成工作記憶與處理速度?)、測量恆等性與試題反應理論(跨群體比分數的技術前提),最後一路推進到基因組學如何重寫遺傳率的意義。這些是把智力從「一個分數」變成「一個可被機制檢驗的科學對象」的關鍵環節。
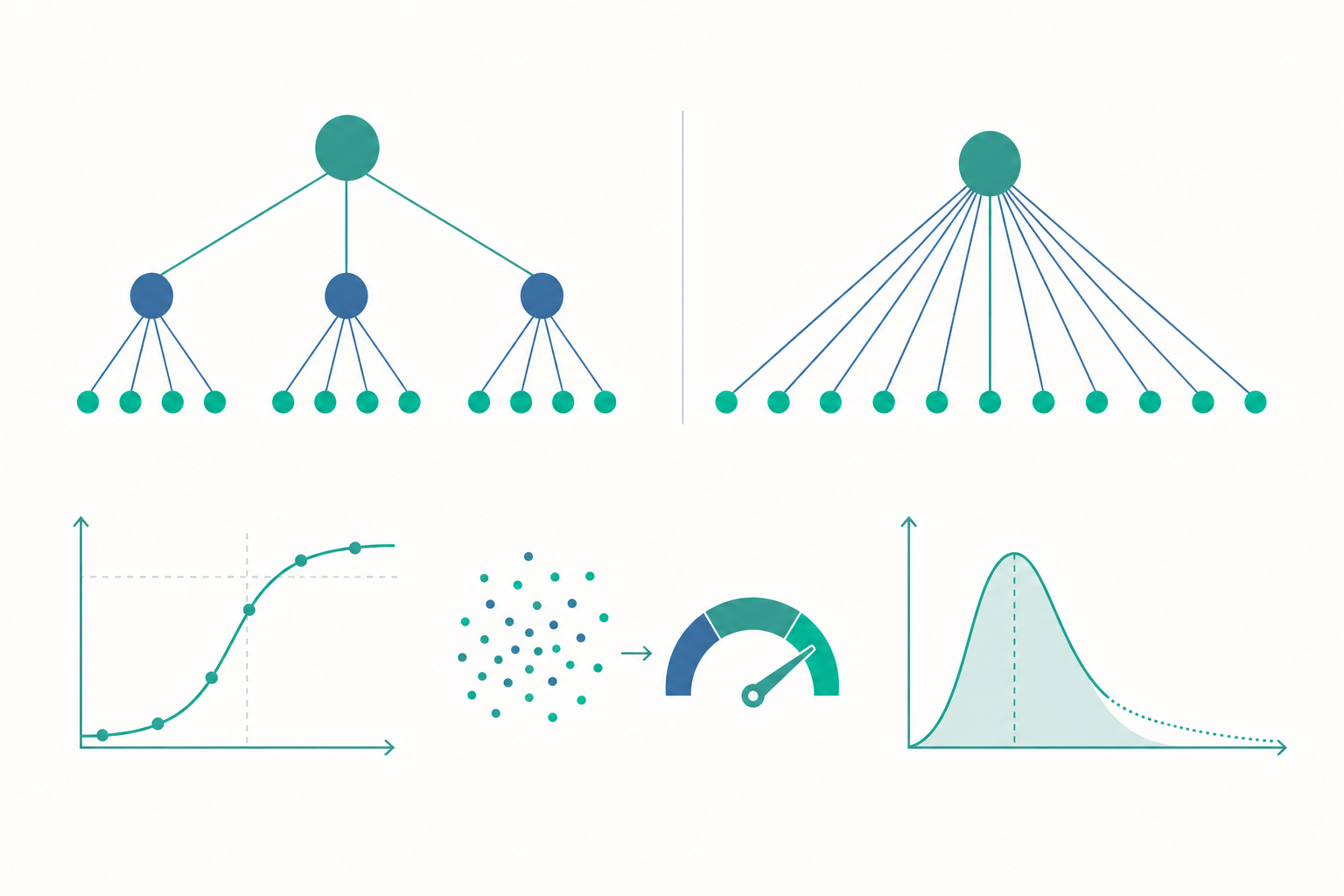
高階因素 vs 雙因素:同一份資料,兩種世界觀
入門篇給你的 CHC 三層金字塔,在統計上其實對應一種特定模型,叫做高階因素模型(higher-order model)。在這個模型裡,g 站在頂端,它透過中層的廣域能力(如流體智力 Gf、晶體智力 Gc)間接影響各個分測驗。也就是說,g 對你某一道題目的影響,全部都「流經」廣域能力這個中介。
但同一份相關資料,還可以用另一種結構去解釋,叫做雙因素模型(bifactor model)。在這裡,g 不再高高在上,而是直接作用於每一個分測驗;同時,每個廣域能力變成與 g 正交(互相獨立)的「群因素」(group factor),只負責解釋扣掉 g 之後剩下的那部分共變。
這個差異聽起來抽象,後果卻很實在:
- 在高階模型裡,「Gf 等於 g」幾乎成立——許多研究發現流體智力與 g 的相關高到接近 1,於是有人主張 Gf 根本就是 g 的化身。
- 在雙因素模型裡,你可以把「純粹的 g」與「扣除 g 之後的特定能力」清楚切開,去問一個更精緻的問題:一份測驗的預測力,到底有多少來自 g,又有多少來自它獨有的特定能力?
研究發現一個發人深省的結果:當你用雙因素模型把 g 抽出來後,很多分測驗的「特定能力」對真實世界結果(如學業、工作表現)的額外預測力會大幅縮水。換句話說,這些測驗之所以有用,主要是因為它們都在偷偷測量同一個 g。這對「多元智能」一類主張是個沉重的挑戰:你以為你在分別測量八種獨立才能,模型卻告訴你它們共享了一個巨大的共同核心。
要提醒的是:雙因素模型在統計上容易過度配適(它參數多、彈性大,常常「看起來」配適得更好),近年方法學界對盲目偏好它有不少警告。模型的選擇不該只看配適指標,更要看它在理論上是否站得住腳。這正是智力研究迷人的地方——統計模型不是中立的描述,它本身就是一種對「智力是什麼」的主張。
把 g 拆成零件:工作記憶、處理速度與反應時間
如果 g 是個統計構念,那它能不能被「化約」成更基本、更接近大腦運作的認知歷程?這是過去三十年認知心理學最重要的攻堅方向之一。
工作記憶(working memory) 是頭號嫌疑犯。康威(Andrew Conway)、恩格爾(Randall Engle)等人的大量研究顯示,工作記憶容量——特別是其中的注意力控制成分(在干擾下維持目標訊息的能力)——與流體智力的相關高得驚人,潛在變項層次的相關常落在 0.7 到 0.9 之間。有些研究者一度主張兩者根本是同一回事。後續更細緻的分析則認為,兩者高度重疊但不完全等同:工作記憶解釋了流體智力很大一部分,但不是全部。
處理速度(processing speed) 是另一條線索。傑森(Arthur Jensen)長年研究一個看似平淡的現象:反應時間(reaction time, RT)與 IQ 的負相關——IQ 越高的人,在最簡單的「燈亮就按鍵」作業上反應越快。更有意思的是「赫氏定律」(Hick's law)情境下的發現:當選項變多、作業變難,高 IQ 與低 IQ 者的反應時間差距會拉大。
但這裡有一個比平均反應時間更深刻的指標:反應時間的變異性(intra-individual variability, IIV),也就是「你每一次反應快慢的不穩定程度」。研究發現,反應時間的標準差,往往比平均反應時間更能預測 g。為什麼?一個有力的解釋是「神經雜訊假說」:高智力可能對應於更穩定、訊號雜訊比更高的神經處理——不是每次都更快,而是更少出現那種反應特別慢的「失神時刻」(lapses of attention)。這把智力從「速度」重新框定為「處理的一致性與可靠性」,是個漂亮的觀念轉折。
看一個例子:為什麼「偶爾很慢」比「平均很快」更說明問題
假設有兩位同學做同一份簡單反應作業,各做 100 次(單位:毫秒):
- 小安:每次都落在 280 到 320 之間,平均約 300。
- 小宇:大多數時候 250 到 270,飛快;但每隔一陣子會冒出一次 600 甚至 800 的超慢反應,平均算下來也約 300。
兩人平均反應時間幾乎一樣,但他們的標準差天差地遠。神經雜訊假說預測:小安那種「穩定」的剖面,往往對應更高的 g;小宇那些偶發的超慢反應,反映的正是注意力控制偶爾「斷線」——而這種斷線頻率,恰恰是流體智力個別差異的核心來源之一。
這個例子的教學重點是:描述一個人的認知能力時,只看平均數會漏掉最關鍵的訊息。 分布的形狀(尤其是慢速尾端)常常才是金礦。下次你分析任何反應時間資料,別只算 mean——畫出整個分布,看看那條右側的長尾。
為什麼「跨群體比 IQ」在技術上這麼危險:測量恆等性
入門篇提過文化偏誤與刻板印象威脅,那是現象層面的公平性問題。進階篇要給你的是它的技術核心:測量恆等性(measurement invariance)。
想像你要比較甲、乙兩個群體(不同文化、語言、世代或性別)的智力分數。在你能合法地說「甲群體平均比乙群體高」之前,必須先回答一個前提問題:這份測驗在兩個群體身上,測到的是不是同一個構念、用的是不是同一把尺? 這就是恆等性檢驗,通常分幾個層級逐步檢查:
- 形貌恆等(configural invariance):兩群體的因素結構長得一樣嗎?(同樣是 g 加上同樣那幾個廣域能力?)
- 計量恆等(metric invariance):每道題對潛在構念的「載荷量」一樣嗎?(同一題在兩群體中,對 g 的指示強度相同?)
- 純量恆等(scalar invariance):每道題的「截距」一樣嗎?這一層最關鍵——唯有純量恆等成立,跨群體比較平均分數才有意義。
如果純量恆等不成立,卻硬要比較兩群體的平均 IQ,那就是 CLAUDE.md 裡那句話的精確含意:在比較蘋果與橘子。某道題可能對甲群體偏易、對乙群體偏難(例如題目用了某個文化專有的詞),這種「試題功能差異」(differential item functioning, DIF)會系統性地汙染群體比較,而它完全可能藏在一份「信度很高」的測驗裡。
這就是為什麼負責任的智力研究者,對任何「某群體比某群體聰明」的宣稱會極度謹慎——不是出於政治正確,而是因為多數這類宣稱根本沒先通過恆等性這一關,在方法學上就站不住腳。
試題反應理論:從「答對幾題」到「你在能力軸上的位置」
要真正理解現代智力測量,你需要認識試題反應理論(item response theory, IRT),它是當代測驗(含許多大型 IQ 與教育評量)的計量骨幹,也是離差智商背後更精密的引擎。
古典測驗理論(classical test theory)關心的是「總分」,但總分有個尷尬:答對 10 題簡單題和答對 10 題困難題,分數一樣,能力卻明顯不同。IRT 換了一套思路——它同時為「人的能力」與「題的難度」建立參數,放在同一條潛在量尺上。
最常見的形式是把每道題畫成一條 S 形的「試題特徵曲線」(item characteristic curve):橫軸是受測者的潛在能力 θ(theta),縱軸是答對該題的機率。一道題由幾個參數刻畫:
- 難度(b 參數):曲線往右移多少——這道題要多高的能力才有五成把握答對。
- 鑑別度(a 參數):曲線多陡——這道題區分高低能力者的效率。陡的題,能力稍高一點答對率就明顯跳升。
- (三參數模型還會加上猜測度 c,描述能力極低者靠瞎猜也能答對的下限。)
IRT 帶來幾個古典理論做不到的能力:它能算出每道題在能力軸不同位置的「訊息量」,從而設計出電腦適性測驗(computerized adaptive testing, CAT)——你答對就出更難的題、答錯就出更簡單的題,系統動態逼近你的真實能力,用更少題目達到更高精度。前面講的 DIF 檢測,技術上也正是建立在 IRT 之上:它檢查的是「在控制了潛在能力 θ 相同之後,兩群體答對同一題的機率是否仍有差異」。
理解 IRT,你才會明白為什麼「IQ 分數」不只是「答對題數換算」那麼簡單——它背後是一整套關於「能力」與「試題」如何在同一量尺上對話的精密理論。
從遺傳率到多基因分數:分子時代的智力遺傳學
入門篇用雙生子研究談了遺傳率,並且正確地警告「遺傳率是群體統計量、不是個人命運」。進階篇要帶你看這個領域在分子生物學時代發生的革命,以及它如何讓那個警告變得更加重要。
過去的雙生子研究只能告訴你「基因整體上解釋了多少變異」,卻指不出是哪些基因。全基因組關聯研究(genome-wide association study, GWAS)改變了這一切:研究者掃描數十萬至數百萬人的基因組,尋找與認知能力或教育程度相關的單核苷酸多型性(SNP)。
結果揭示了智力遺傳結構的真相——極度多基因(highly polygenic)。沒有所謂的「聰明基因」;相反,認知能力受到成千上萬個微效基因共同影響,每一個的效果都小到幾乎可以忽略。把這些微小效果加總起來,可以算出一個人的多基因分數(polygenic score, PGS)。
但這裡有四個必須牢記的限制,它們讓「基因決定論」的天真版本徹底破產:
- 預測力仍然有限。 目前最好的教育/認知多基因分數,在獨立樣本中也只能解釋個位數到約一成多的變異。它在群體層次有研究價值,用在個人身上幾乎沒有實用預測力。
- 「缺失的遺傳率」。 GWAS 抓到的遺傳效果,加總後仍遠低於雙生子研究估計的遺傳率,這個落差至今未被完全解釋。
- 相關不等於因果機制。 與認知相關的 SNP,很多其實透過「基因—環境相關」起作用(例如某些基因傾向讓人選擇更多刺激的環境),而非直接「製造聰明的大腦」。
- 跨族群不可移植。 多基因分數主要建立在歐洲血統樣本上,套用到其他族群時預測力會大幅下降——這既是科學限制,也是倫理警訊:誤用會放大既有的不平等。
把這四點合起來,現代基因組學給出的訊息,恰恰強化了入門篇的結論:高遺傳率與「可改變、不可貼標籤」完全相容。我們現在比以往任何時候都更清楚——沒有一條基因捷徑能告訴你一個人會有多聰明。
重點回顧
- g 的因素結構不是唯一的:高階模型把 g 放在金字塔頂端,雙因素模型則讓 g 直接貫穿所有測驗。選哪個模型本身就是一種理論主張;雙因素抽出 g 後,許多「特定能力」的獨立預測力會縮水。
- g 可被部分化約為認知零件:工作記憶(尤其注意力控制)與流體智力高度重疊;而反應時間的變異性常比平均反應時間更能預測 g,指向「神經處理的一致性」而非單純的速度。
- 跨群體比較分數的技術前提是測量恆等性:唯有達到純量恆等,比較平均 IQ 才合法;否則就是在比蘋果與橘子,試題功能差異(DIF)會系統性汙染結論。
- IRT 是現代測量的骨幹:它把人的能力與題的難度放在同一量尺上,支撐了電腦適性測驗與 DIF 檢測,遠比「答對幾題」精密。
- 智力是極度多基因的:沒有「聰明基因」,多基因分數對個人預測力有限、有缺失遺傳率與跨族群不可移植等問題——分子證據反而強化了「不可貼標籤」的結論。
深入探討(研究所視角)
把上面這些線索收束起來,研究前沿有幾個彼此咬合的張力值得繼續追問。
化約論的天花板:g 能被完全溶解嗎? 把 g 還原成工作記憶與處理速度,是一個誘人的研究綱領,但它面臨一個概念困境:如果工作記憶本身又是個多面向構念、而它與 Gf 的高相關有部分來自共享的方法變異(兩者都用類似的「在干擾下解題」作業測量),那麼「Gf 約等於工作記憶」會不會只是測量上的同義反覆,而非實質的機制化約?這需要更乾淨的實驗分離(例如以不同作業範式、甚至神經指標來三角驗證),是工作記憶—智力文獻持續爭論的核心。
互利論與網絡取向對「潛在變項」本體論的衝擊。 入門篇提到的互利論(mutualism)若成立,g 是發展過程中能力互相促進的湧現結果而非先存原因,那麼把 g 模型化成一個「潛在共同因」就在本體論上犯了錯。順著這條路,近年興起的心理計量網絡分析(psychometric network analysis)乾脆放棄潛在變項,把各認知能力視為一張互相影響的節點網絡,用網絡中心性等指標重新詮釋「正向流形」。這代表測量哲學的一次典範競爭:智力究竟是「一個躲在背後的因」,還是「一群互動歷程的系統性質」?兩種模型可能對同一份資料給出相近配適,卻指向截然不同的介入策略。
因果推論的新工具與其陷阱。 基因組時代帶來了孟德爾隨機化(Mendelian randomization)這類工具,試圖用基因變項當作「自然實驗」來推論「認知能力是否因果地影響健康、壽命、所得」。它很有力,但對「水平多效性」(一個基因同時影響多條路徑)與群體分層極為敏感,結論需要審慎。同時,基因—環境交互作用(如 Scarr-Rowe 假說:在資源匱乏環境中智力遺傳率被壓低)若為真,意味著遺傳率根本不是一個固定常數,而是環境的函數——這直接動搖了任何「把遺傳率當成命運係數」的解讀。
跨領域的開放問題。 在認知老化研究中,流體與晶體智力的分流軌跡,正被用來建立失智前驅期的早期偵測模型;在教育與勞動經濟學,多基因分數帶來的不只是預測,更是棘手的倫理問題——當「基因稟賦」可被部分量化,社會該如何避免它被誤用為新形式的決定論?而在生成式 AI 的衝擊下,一個更根本的問題浮現:當大型語言模型能輕鬆通過許多傳統「高 g」作業(語文推理、類比、矩陣題),我們對 g 的整套效度論證——「它預測真實世界成就」——是否需要重新檢視?機器在這些測驗上的高分,反過來逼我們追問:這些測驗測到的,究竟是某種普遍的智能,還是只是某類可被統計模式擬合的規律性?
對研究者而言,這一系列問題最終都指向同一個謙遜的領悟:智力研究的成熟,不在於找到 g 的「真身」,而在於學會在統計模型、認知機制、遺傳結構與社會脈絡四個層次之間反覆校準,並且時時記得——我們手上每一個漂亮的數字,都同時是一項科學發現,也是一個有待批判的建構。