
學習進階:預測誤差、多巴胺與記憶如何被改寫
從 Rescorla–Wagner 模型到測驗效應,看學習如何從「行為的描述」走向「大腦的計算」
為什麼「驚喜」才是學習的引擎?
入門篇裡,巴夫洛夫的狗聽到鈴聲就分泌唾液,手機提示音讓你忍不住伸手解鎖。那是行為主義的經典畫面:刺激配對刺激,反應被強化。但如果你停在這裡,會錯過二十世紀後半到今天最深刻的一個轉折——學習的核心,其實不是「配對」本身,而是預期落空的瞬間。
設想一個情境:你已經很熟悉一間咖啡廳,每次推門進去店員都會說「歡迎光臨」。久而久之,這句話幾乎不再進入你的意識。某天你推門進去,店員卻說「欸,你昨天忘了拿發票」。這一刻你會記得清清楚楚,甚至晚上躺在床上還會想起來。為什麼一句熟悉的招呼被忽略,而一句意外的話卻牢牢刻進記憶?
答案藏在一個看似簡單、卻重寫了整個學習理論的概念裡:預測誤差(prediction error)。本篇就從這裡出發,帶你看學習如何從「行為的描述」走向「大腦的計算」。
從配對到計算:Rescorla–Wagner 模型
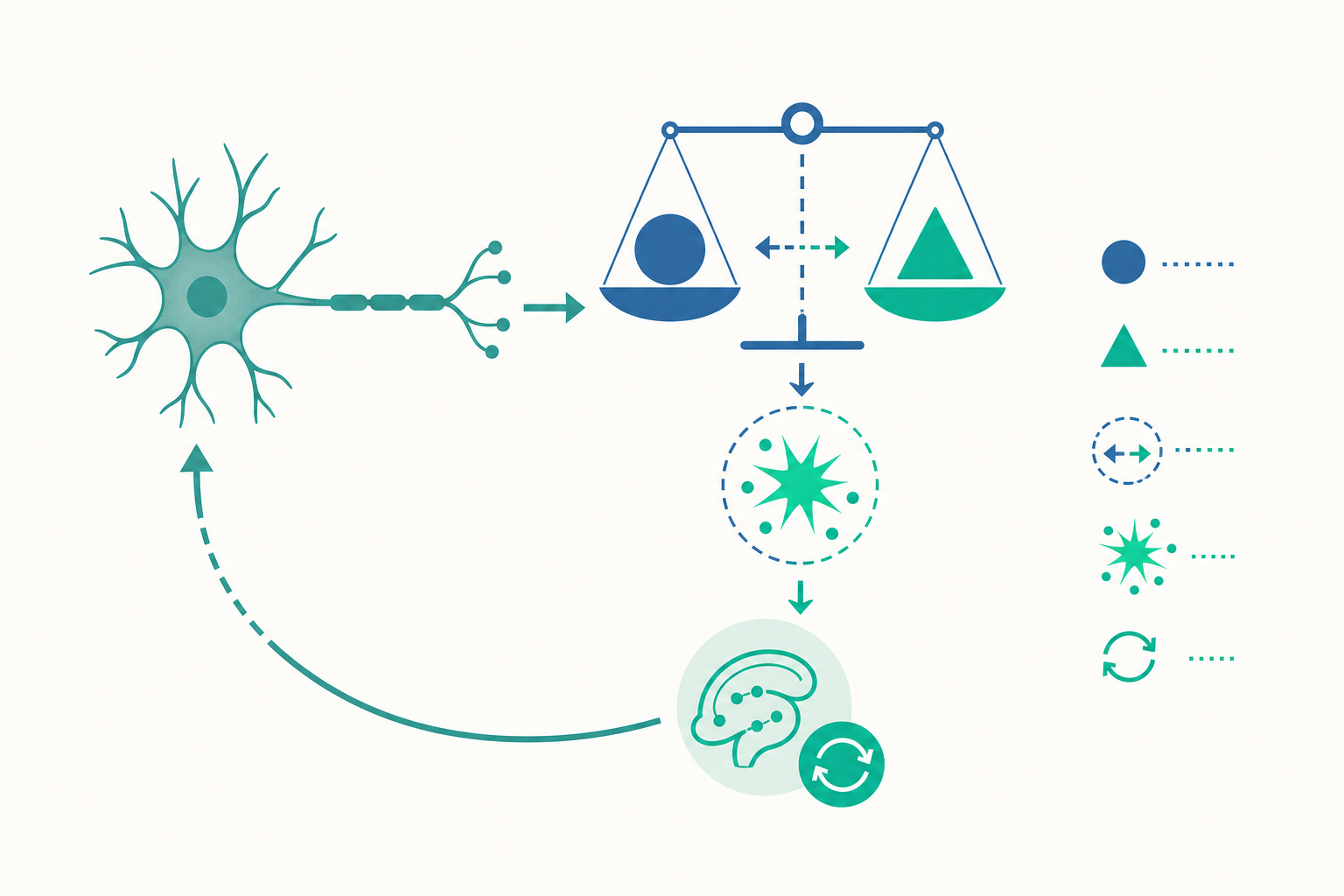
行為主義有個漂亮但有缺陷的假設:刺激出現得越多次、配對得越緊密,連結就越強。聽起來合理,直到一個實驗推翻它。
1969 年,Leon Kamin 做了「阻斷效應(blocking effect)」實驗。先讓動物學會「燈光 → 電擊」,等這個連結穩固後,再同時呈現「燈光+聲音 → 電擊」。按照單純配對的邏輯,聲音和電擊配對了很多次,動物應該也會怕聲音。但結果是:動物幾乎沒有學到聲音的意義。聲音被「阻斷」了。
為什麼?因為燈光已經能完美預測電擊,電擊的出現「不令人意外」。聲音沒有提供任何新的資訊,於是大腦不更新對聲音的評價。
1972 年,Robert Rescorla 與 Allan Wagner 把這個洞見寫成一條數學式,成為學習心理學最有影響力的公式之一:
ΔV = α × β × (λ − ΣV)
別被符號嚇到,它在說一件很直覺的事。λ 是這次實際發生的結果(例如電擊的強度),ΣV 是動物根據目前所有線索預期會發生的結果。兩者相減,(λ − ΣV),就是預測誤差——實際與預期的差距。學習量 ΔV,正比於這個差距。
換句話說:
- 當事情如你所料(誤差 ≈ 0),你幾乎不學任何東西。
- 當事情出乎意料(誤差大),你大幅更新。
回到咖啡廳。「歡迎光臨」誤差為零,被忽略;「你忘了拿發票」誤差很大,被牢記。阻斷效應也順理成章:燈光已把預期拉滿,聲音加進來時誤差已經很小,沒得學。
這條式子的革命性在於:學習第一次被寫成一個可計算的歷程,而不只是行為的累積。它預測了行為主義無法解釋的現象,這正是好理論的標誌。
大腦真的在算誤差嗎?多巴胺的故事
理論再漂亮,也得問一句:大腦裡真有東西在計算預測誤差嗎?
1990 年代,Wolfram Schultz 在猴子身上記錄中腦多巴胺神經元(dopamine neurons)的放電,得到一組讓神經科學界震動的結果。
長期以來,多巴胺被通俗地稱為「快樂分子」或「獎賞訊號」。但 Schultz 看到的不是這樣:
- 訓練初期,猴子拿到果汁時,多巴胺神經元劇烈放電。看起來像在訊號「獎賞來了」。
- 訓練後期,當一個燈光總是先於果汁出現,多巴胺的放電從果汁的時刻移到了燈光的時刻。果汁本身(已被預測)不再引發放電。
- 如果預期的果汁沒來,多巴胺神經元的放電會在該出現果汁的時刻掉到基線以下——一個負向訊號。
把這三點合起來看,多巴胺編碼的根本不是「獎賞」,而是獎賞預測誤差(reward prediction error):比預期好就上升,如預期就持平,比預期差就下降。這幾乎是 Rescorla–Wagner 的 (λ − ΣV) 在神經元層次的化身。
這項發現後來與電腦科學的時序差分學習(Temporal Difference learning, TD learning)接軌。Richard Sutton 與 Andrew Barto 發展的強化學習(reinforcement learning)演算法,核心也是用預測誤差去更新對「未來價值」的估計——同一套數學,竟同時描述了猴子的多巴胺與訓練 AlphaGo 的演算法。今天你聽到的「強化學習」AI,骨子裡和巴夫洛夫的狗共用一條原理。
需要澄清一個常見迷思:多巴胺不等於「爽」。它更接近「值得學的訊號」。把它簡化成快樂分子,會誤解成癮、動機與學習的整個機制。
學了之後呢?記憶的固化與再固化
預測誤差告訴我們「何時學」,但學到的東西怎麼留下來、又怎麼被改寫?這要進到記憶的固化(consolidation)。
剛形成的記憶是脆弱的。它需要時間,把短期的、易受干擾的痕跡,轉成長期的、穩固的儲存。這個過程牽涉海馬迴(hippocampus)與大腦皮質的對話,而且睡眠扮演關鍵角色——尤其是慢波睡眠期間,海馬迴會「重播(replay)」白天的神經活動序列,把記憶逐步移交給皮質長期保存。這也是為什麼熬夜硬撐的學習效率往往很差:你剝奪了大腦整理檔案的時間。
更顛覆直覺的是再固化(reconsolidation)。長久以來人們以為記憶一旦固化就像刻在石頭上。但 2000 年 Karim Nader 等人的研究顯示:當一段舊記憶被提取(retrieve)出來時,它會短暫回到不穩定狀態,需要再一次固化才能存回去。在這個「重新可塑」的窗口裡,記憶可以被加強、被修改,甚至被干擾。
這不是冷知識。它意味著:回憶本身會改變記憶。每次你回想一件往事,存回去的版本都可能被當下的情緒與資訊微調。法庭上目擊者證詞的不可靠、創傷治療裡改寫恐懼記憶的嘗試,背後都是再固化在運作。記憶不是錄影帶,而是每次播放都會重錄一次的劇本。
為什麼「考自己」比「重讀」更有效?
把上面的機制連起來,會得到一個對你直接有用的結論。我們先看一個被反覆驗證的現象。
看一個例子:測驗效應
2006 年,Henry Roediger 與 Jeffrey Karpicke 做了一個經典實驗。學生讀一段文章後分成兩組:
- 重讀組:再讀一次文章。
- 測驗組:不重讀,而是蓋上文章,盡力回想內容(一次提取練習)。
如果你問學生哪一組學得比較好,多數人——包括測驗組自己——都覺得重讀比較紮實。短期測驗(五分鐘後)也確實是重讀組分數略高。
但一週後再測,結果反轉:測驗組的長期保留率明顯高於重讀組。費力去「提取」記憶,比舒服地「再輸入」一次,留下更持久的痕跡。這就是測驗效應(testing effect),又稱提取練習(retrieval practice)。
為什麼?把前面的機制接上來:
- 提取是一次主動重建,不是被動辨識。重讀時你看著答案,產生「我懂了」的流暢錯覺(fluency illusion);提取時你被迫從零生成,暴露了真正的漏洞——這本身就是一次預測誤差訊號。
- 每次成功提取,都觸發一次再固化,把記憶存回去時順帶強化、並建立更多提取線索。
- 提取的「困難」不是壞事。這呼應了 Robert Bjork 提出的理想難度(desirable difficulties):適度的費力會讓學習更深、更持久,即使當下感覺更糟、進步更慢。
動手試試
下次準備一個概念,先別急著畫重點、重讀。試試這個流程:
- 讀完一段後,蓋上材料。
- 拿白紙,憑記憶寫下剛剛的核心要點(自由回憶,free recall)。
- 寫不出來的地方,正是你的漏洞——翻回去只補那一塊,不要整段重讀。
- 把複習排在幾天後而不是當天連續複習(間隔練習,spaced practice)。
間隔的力量同樣有實證根基,可上溯到 1885 年 Hermann Ebbinghaus 的遺忘曲線(forgetting curve)。他用自己當受試者背無意義音節,量化了記憶隨時間衰退的軌跡,並發現重新學習已遺忘的材料比第一次快——這個「節省(savings)」現象,正是間隔複習有效的最早證據。在記憶快要遺忘、提取有點吃力時複習,效果最好;太早複習(記憶還很鮮明)幾乎是浪費。
把「提取練習+間隔練習」結合,是認知心理學給學生最可靠、CP 值最高的建議——可惜它感覺起來最不爽,所以最少人用。
重點回顧
- 預測誤差是學習的引擎:Rescorla–Wagner 模型用
(λ − ΣV)把學習量綁定在「實際與預期的差距」上。事情如你所料時,你幾乎不學;出乎意料時,你大幅更新。 - 阻斷效應證明單純的配對次數不足以解釋學習——已被預測的結果不再帶來新資訊。
- 多巴胺編碼的是獎賞預測誤差,不是快樂本身;它與 AI 的時序差分強化學習共用同一套數學。
- 記憶會固化也會再固化:提取一段記憶會讓它短暫變得可塑,因此「回憶會改寫記憶」,睡眠則是固化的關鍵時段。
- 測驗效應與間隔練習是最有實證支持的讀書法:費力的提取勝過舒服的重讀,理想難度讓學習更持久。
深入探討(研究所視角)
若要再往前推一層,有幾條值得追的線索。
第一,模型的繼承與超越。 Rescorla–Wagner 雖強,卻有已知限制:它假設線索的「可學性(associability)」固定,無法解釋潛抑制(latent inhibition)等現象。後續的 Mackintosh(1975) 與 Pearce–Hall(1980) 模型,把注意力(attention)動態化——Pearce–Hall 主張預測誤差大的線索反而獲得更多注意力,與 Rescorla–Wagner 形成互補。現代觀點傾向認為大腦同時用多套機制,視情境切換。
第二,model-free 與 model-based 的二分。 強化學習在認知神經科學裡分成兩派系統:model-free(習慣性、緩慢累積價值,對應背側紋狀體與多巴胺 TD 訊號)與 model-based(目標導向、會用內在的環境模型做前瞻推理,對應前額葉與海馬迴)。Daw、Dolan 等人用「two-step task」行為派典,證明人類在兩套系統間動態權衡——壓力、認知負荷會把人推向 model-free 的習慣模式。這對理解成癮、強迫行為與決策都有深遠意涵。
第三,突觸層次的基質。 把預測誤差「寫進」突觸的細胞機制,核心是 長期增益(long-term potentiation, LTP) 與 長期抑制(long-term depression, LTD),源自 Bliss 與 Lømo(1973)在海馬迴的發現。其中 NMDA 受體 作為「巧合偵測器(coincidence detector)」,只有在突觸前後活動同時發生時才開啟鈣離子通道,啟動可塑性——這在分子層次呼應了 Hebb(1949)的名言「fire together, wire together」。從 Hebb 的猜想到 NMDA 的分子確證,是一條跨越半世紀的漂亮故事。
第四,再固化的臨床前景與爭議。 若提取會打開記憶的可塑窗口,理論上可在窗口內以藥物(如 propranolol 阻斷正腎上腺素)或行為干預削弱病理性恐懼記憶。這在 PTSD 治療上引發大量研究,但臨床轉譯的結果並不一致——窗口的邊界條件(記憶強度、年齡、提取方式)遠比早期樂觀預期複雜。這提醒我們:動物模型的乾淨機制,到人類複雜記憶往往要打折扣,是值得保持批判的前沿。
如果你想動手,two-step task 與 delay discounting 是兩個容易上手、又能連結到行為經濟學與計算精神醫學的派典;而把 Rescorla–Wagner 寫成幾行 Python 模擬阻斷效應,是體會「學習即計算」最快的方式。學習的科學,正從描述行為,走向逆向工程大腦的更新規則——而你每一次費力的回想,都是這套規則在你身上運作的證據。