
量到的是「那個東西」嗎?測量、檢定力與機制推論的進階紀律
當實驗設計無懈可擊,更隱蔽的問題藏在測量與推論鏈裡——打開信效度黑盒子,理解效果量、統計檢定力,以及讓假設長出機制的中介與調節。
你的問卷量到的,真的是「那個東西」嗎?
入門篇教過你一條鐵律:相關不等於因果。但假設今天你的實驗設計無懈可擊——隨機分派、雙盲、控制組一應俱全——卻有一個更隱蔽的問題從一開始就埋伏在那裡:你用來測量「快樂」的那五道問卷題目,量到的真的是快樂嗎?還是其實量到了「願意對陌生研究者承認自己快樂的程度」?又或者,你宣稱「正念訓練降低了焦慮」,但如果你的焦慮量表在訓練前後的意義根本不一樣(受試者經過訓練後重新理解了「緊張」這個詞),那前後分數的下降究竟代表什麼?
入門篇把測量壓縮成「信度與效度」一句話帶過。但在真實研究裡,測量本身就是一整套理論——心理學測量的不是長度或重量,而是看不見的潛在構念(latent construct)。這篇進階文章要把「信度與效度」這個黑盒子打開,再往前推進到效果量、統計檢定力,以及中介與調節這些讓你的假設「長出機制」的工具。讀完之後,你看一篇論文的眼光會從「他們有沒有做實驗」升級到「他們的推論鏈每一節到底站不站得住」。
測量理論:分數從哪裡來
入門篇說「信度是一致、效度是準確」,這個比喻很好用,但它隱藏了一個關鍵問題:我們從來沒有直接測到焦慮、智力或態度。我們測到的永遠是某種可觀測指標(observed indicator)——量表得分、反應時間、皮膚電導——再從這些指標推論背後的構念。這個推論的合法性,就是測量理論要處理的核心。
古典測驗理論(Classical Test Theory, CTT) 用一條簡潔的方程式描述這件事:
觀測分數(X) = 真分數(T) + 誤差(E)
「真分數」是同一個人在無限次重複測量下的理論平均值,「誤差」則是隨機波動。信度在這個框架下有了精確定義:真分數變異佔總變異的比例(reliability = σ²_T / σ²_X)。當誤差越小,觀測分數就越貼近真分數,信度越高。你常在論文裡看到的 Cronbach's α,估計的正是這個比例——但要注意,α 高並不單純等於「題目都很好」,它同時受到題數與題目間相關的影響,題目一多 α 就容易虛高,這是初學者常踩的雷。
效度則遠比信度複雜。 現代效度觀(以 Messick 為代表)主張效度不是測驗的固有屬性,而是對「分數詮釋」的整體論證。一份憂鬱量表本身無所謂有效或無效;有效的是「用它的得分來推論臨床憂鬱程度」這個特定用途。心理計量學把效度拆成幾個面向:
- 內容效度(content validity):題目是否涵蓋了構念的完整內涵?一份只問「失眠」的憂鬱量表漏掉了情緒低落與興趣喪失,內容效度就不足。
- 效標關聯效度(criterion-related validity):分數能否預測一個外部標準?例如入學測驗能否預測大一成績。
- 建構效度(construct validity):這是最根本的一層。分數是否與「理論上該相關的東西」相關(收斂效度,convergent validity),又與「理論上該無關的東西」無關(區辨效度,discriminant validity)?
Campbell 與 Fiske(1959)提出的多特質多方法矩陣(multitrait-multimethod matrix, MTMM)正是檢驗收斂與區辨效度的經典工具:用多種方法測量多個特質,理想情況下「同一特質、不同方法」的相關應該高(收斂),而「不同特質、同一方法」的相關不應該被方法本身撐高(否則就是共同方法變異,common method variance 在作怪)。
為什麼「顯著」不等於「重要」:效果量與檢定力
入門篇的研究所視角提過 p-hacking,但要真正理解可重複性危機,你得先看懂兩個被忽視太久的量:效果量(effect size)與統計檢定力(statistical power)。
p 值回答的問題其實很窄。 它只回答:「假設虛無假設為真,觀察到這麼極端(或更極端)資料的機率有多大?」它不告訴你效應有多大、也不告訴你假設為真的機率。一個極微小、毫無實務意義的差異,只要樣本夠大,照樣可以得到 p < 0.001。這正是為什麼光看 p 值會嚴重誤導。
效果量補上了 p 值缺的那一塊:差異的「大小」。 常見的有比較兩組平均數的 Cohen's d(以標準差為單位的差異),以及表示變異解釋比例的 r²/η²。Cohen 給過粗略的參考錨點(d ≈ 0.2 小、0.5 中、0.8 大),但他本人再三強調這只是沒有領域知識時的權宜,不該僵化套用——在某些高風險領域,d = 0.1 都可能極具意義。
統計檢定力則是另一個長期被低估的概念。 檢定力(power, 1 − β)是「當效應真實存在時,研究能成功偵測到它的機率」。它由三件事共同決定:效果量、樣本數、顯著水準 α。Cohen 早在 1962 年就警告,心理學研究的平均檢定力低得驚人——許多研究即使假設為真,也只有四五成機會發現它。
低檢定力的後果遠比「容易漏掉真效應」更糟糕。它會製造一個惡性循環:在低檢定力下,那些「僥倖達到顯著」的研究,其估計的效果量會被系統性高估(這稱為 winner's curse 或 Type M error,誤差幅度錯誤),甚至連效應的方向都可能搞反(Type S error,符號錯誤)。配合發表偏誤,文獻於是被一堆灌水的效應量填滿——這才是複製失敗的深層機制之一。
動手試試:用檢定力反推樣本數
假設你預期某個介入的真實效果量是 Cohen's d = 0.4(中小程度),想用獨立樣本 t 檢定、雙尾 α = 0.05,達到慣例上可接受的檢定力 0.80。
不需要背公式,重點是理解這個推理的方向:先決定你想偵測的最小效應,再回推需要多少人,而不是先收一收手邊湊得到的樣本、事後再看顯著沒。對 d = 0.4、power = 0.80 的設定,每組大約需要 100 人(合計約 200 人)。如果你只找得到每組 25 人,那麼即使效應真的存在,你也只有大約三成的機會偵測到它——這種研究在開始之前,命運就已經注定大半。
這就是事前檢定力分析(a priori power analysis)的價值:它逼你在花一分錢、找一個受試者之前,就誠實面對「我這個設計到底有沒有機會回答我的問題」。順帶一提,事後檢定力(post hoc power,用觀察到的效果量回算的檢定力)幾乎沒有資訊價值,因為它和 p 值是一對一的數學變換,請不要在論文裡這樣做。
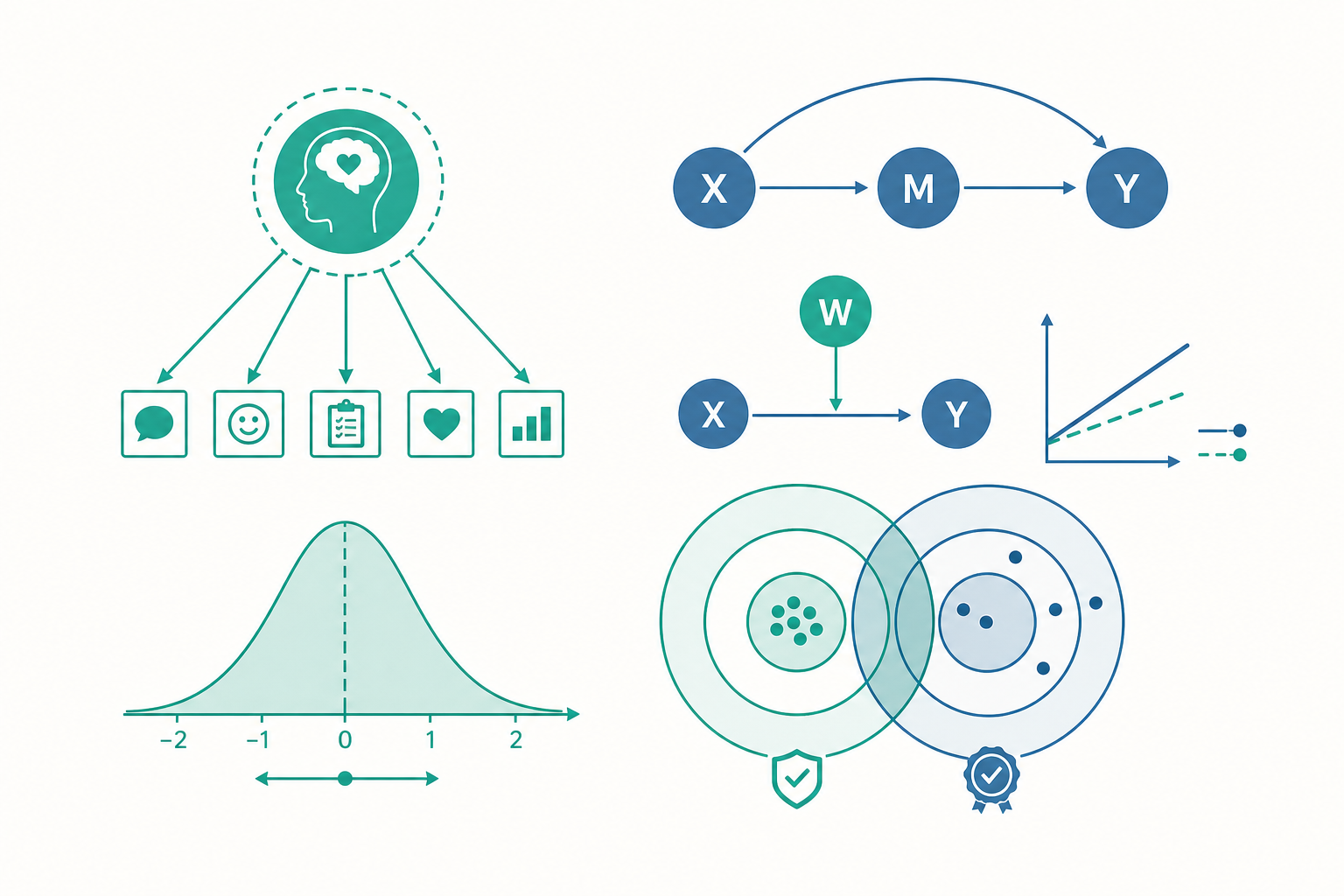
讓假設長出機制:中介與調節
入門篇的假設都很「扁平」:A 影響 B。但成熟的心理學理論幾乎都在問更細的問題——A 是透過什麼影響 B 的?A 的效果在什麼條件下比較強?這兩個問題分別對應兩個常被混淆的概念:中介(mediation)與調節(moderation)。
中介回答「如何/為什麼」(機制問題)。 中介變項是因果鏈上的中間環節:自變項 X 先影響中介變項 M,M 再影響依變項 Y(X → M → Y)。例如「社經地位影響學業成就」可能是透過「家庭學習資源」這個中介——社經地位高 → 學習資源多 → 成就高。Baron 與 Kenny(1986)的經典四步驟曾主導這個領域數十年,但現代取向已轉向直接檢定間接效果(indirect effect,即 a × b 路徑的乘積)的顯著性,常用 bootstrap 法建立其信賴區間,因為間接效果的抽樣分布通常不對稱,不適合用傳統的常態近似。
調節回答「何時/對誰」(條件問題)。 調節變項改變的是 X 與 Y 之間關係的強度或方向,在統計上表現為 X 與調節變項 W 的交互作用項(interaction term)。例如「壓力對表現的影響」會被「經驗」調節:對新手而言壓力可能是負面的,對老手卻可能無妨甚至有益。請務必區分:中介說的是「中間經過誰」,調節說的是「在誰身上、什麼情況下不一樣」——把調節變項誤稱為中介,是論文寫作裡最常見的概念錯誤之一。
看一個例子:同一個變項,中介還是調節?
設想一個研究問題:運動如何影響睡眠品質?
-
如果你的理論是:運動 → 降低當日皮質醇(cortisol)→ 改善睡眠,那麼「皮質醇」是中介。它站在因果鏈的中間,是運動發揮作用的管道。要支持這條路徑,你得證明運動確實壓低了皮質醇,而皮質醇的下降又確實連到睡眠改善。
-
如果你的問題是:運動對睡眠的好處,是不是在「平常壓力大的人」身上特別明顯?那麼「壓力程度」是調節。它不在因果鏈上,而是站在旁邊調整這條鏈的強弱——對高壓族群,運動 → 睡眠的斜率較陡;對低壓族群較平。
同一個情境,換個問法,變項的角色就完全不同。判準很單純:問「它是經過的站」還是「它是改變斜率的旋鈕」。值得一提的是,這兩者可以結合成更複雜的模型,例如有調節的中介(moderated mediation)——間接效果本身的大小又隨第三變項而變,這類模型在當代社會與健康心理學中已是標準配備。
設計的進階選擇:受試者內與多層次
入門篇預設的是最單純的受試者間設計(between-subjects design):每個人只進一組。但研究者手上還有更精巧的選項。
受試者內設計(within-subjects design) 讓同一個人接受所有條件。它最大的好處是控制了個體差異——既然是同一個人在不同條件下被比較,年齡、智商、人格這些穩定特質自動被抵銷掉了,於是檢定力大幅提升,需要的人數也更少。代價是引入了順序效應(order effect):先做 A 條件可能因為練習而讓 B 做得更好(練習效應),或因為疲勞而讓 B 做得更差(疲勞效應)。對策是對抗平衡(counterbalancing)——讓不同受試者以不同順序經歷各條件(例如一半先 A 後 B,一半先 B 後 A),把順序效應從系統性偏誤打散成隨機噪音。
多層次/巢套資料(multilevel / nested data) 則是當代心理學與教育研究繞不開的結構。學生巢套於班級,班級巢套於學校;同一個人的多次測量巢套於這個人之內。這類資料違反了傳統統計檢定的一個核心假設——觀測值彼此獨立。同一班的學生因為共享老師與環境而彼此相似,把他們當成獨立樣本會嚴重低估標準誤、灌水出假的顯著性。多層次模型(multilevel model,又稱階層線性模型 HLM 或混合效應模型 mixed-effects model)正是為此而生:它明確把變異拆解成「層內」(學生之間)與「層間」(班級之間),既誠實處理了非獨立性,也讓你能同時提問「個人特質的效果」與「環境脈絡的效果」。當你日後在 Uedu 這類平台分析「學生—課程—學校」三層巢套的學習資料時,這正是必備的工具。
重點回顧
- 測量是一套理論,不是一個數字:我們永遠在用可觀測指標推論看不見的構念。古典測驗理論把信度定義為真分數變異佔總變異的比例;現代效度觀(Messick)則把效度看成對「分數詮釋」的整體論證,核心是收斂效度與區辨效度。
- 顯著 ≠ 重要:p 值不告訴你效應多大。一定要報告效果量(Cohen's d、η²)與信賴區間,並理解 Cohen 的錨點只是權宜參考。
- 檢定力決定研究的命運:低檢定力不只讓你漏掉真效應,還會系統性高估效果量(winner's curse)甚至弄錯方向(Type S/M error)。請做事前檢定力分析、別碰事後檢定力。
- 中介問「如何」、調節問「何時」:中介是因果鏈上經過的站(X→M→Y),調節是改變關係斜率的旋鈕(X×W 交互作用)。混淆兩者是論文常見硬傷。
- 設計有進階選項:受試者內設計提升檢定力但需對抗平衡來壓制順序效應;多層次模型則誠實處理巢套資料的非獨立性。
深入探討(研究所視角)
進到這一層,「測量」與「推論」會合流成一個更統一、也更嚴格的框架。
從 CTT 到潛在變項模型。 古典測驗理論有個根本限制:信度與題目難度都依賴於特定樣本,換一群人就變了。試題反應理論(Item Response Theory, IRT)把焦點從「總分」轉移到「個別題目與潛在特質的關係」,用試題特徵曲線(item characteristic curve)刻畫某道題在不同能力水準下被答對的機率,並估計題目的難度(difficulty)與鑑別度(discrimination)參數。IRT 的威力在於它讓「能力估計」與「樣本」脫鉤,是現代電腦化適性測驗(CAT)的數學基礎。更上一層,驗證性因素分析(Confirmatory Factor Analysis, CFA)與結構方程模型(Structural Equation Modeling, SEM)把測量模型(潛在構念如何由指標反映)與結構模型(構念之間的因果路徑)整合在同一個框架裡,讓你能在「扣除測量誤差」之後估計構念間的真實關係——這也是為什麼 SEM 報告裡的路徑係數,往往比直接拿總分跑迴歸更乾淨。
測量不變性:跨組比較的隱形前提。 當你說「男性的某特質高於女性」或「介入後焦慮下降」,你其實偷偷假設了量表在兩組/兩個時間點測的是同一個東西、用同一把尺。這個假設叫測量不變性(measurement invariance),可在多群組 CFA 中分層檢驗:因素結構相同(形態不變性, configural)、因素負荷量相同(度量不變性, metric)、截距相同(純量不變性, scalar)。若連純量不變性都不成立,那麼比較組間平均數就可能是在比較蘋果與橘子——許多看似驚人的跨文化或性別差異,一旦做了不變性檢定就站不住腳。這是入門篇「效度」一句話完全藏不住的深水區。
估計取向與貝氏視角。 入門篇結尾提到從 NHST 轉向估計取向。更進一步說,整個方法學正從「二分的判決」(顯著/不顯著)轉向「連續的證據刻畫」。貝氏因子(Bayes factor)能量化「資料對 H1 相對於 H0 的支持程度」,而且——不同於 p 值——它允許你蒐集證據去支持虛無假設(例如證明某介入「確實沒效」,這在 NHST 框架下是做不到的)。配合序貫分析(sequential analysis)與預先註冊的停止規則,研究者得以在控制偽陽性的前提下邊收資料邊看證據,既省樣本又透明。
回到根本:方法學是一種知識倫理。 從 IRT 到測量不變性、從檢定力分析到貝氏推論,這些工具表面上是統計技術,骨子裡卻是同一種紀律——對自己的不確定性誠實。一個成熟的研究者不是手握最炫模型的人,而是能清楚說出「我這把尺量的是什麼、量得準不準、我的設計有多大機會看見真相、我又有多少把握下這個結論」的人。當你日後在多模態學習分析、生理感知建模這類前沿題目上工作時,正是這份對測量與推論的雙重清醒,讓你的研究真正禁得起別人重做一遍。